Altavista
Система открыта в декабре 1995. Принадлежит компании DEC
С 1996 года сотрудничает с Yahoo
Атрибут NAME
META-таги с атрибутом NAME используются в случаях, когда поля не соотносятся с HTTP-заголовками. Иногда ясность теряется: некоторые агенты могут интерпретировать таг "Keywords" описанный как NAME, другие - как HTTP-EQUIV
Robots
Источники: Spidering
Управление индексацией страницы для поисковых роботов.
<META NAME="Robots" CONTENT="NOINDEX,FOLLOW">
Возможные значения: ALL NONE INDEX NOINDEX FOLLOW NOFOLLOW
Подробнее об этом в статье
Description
Источники: Spidering, Altavista, Infoseek
Краткая аннотация содержания документа. Используется поисковыми системами для описания документа. Этот таг сильно полезен в случаях, когда в документе мало текста, когда это управляющий фреймами файл (frameset) или в начале документа используются скрипты. Длина текста до 100 символов.
<META NAME="Description" CONTENT="Документ содержит словарь META-тагов">
Подробнее об этом в статье
Keywords
Источники: Altavista, Infoseek
Используется поисковыми системами для индексирования документа. Обычно здесь указываются синонимы к словам в заголовке (title) или альтернативный заголовок. Длина списка до 1000 символов. Не допускается использование одного и того же ключевого слова более 7 раз, поисковые системы просто будут игнорировать это слово.
<META NAME="Keywords" CONTENT="таги,тэги,метаданные,список">
Подробнее об этом в статье
Document-state
Источники: Spidering
Управление индексацией страницы для поисковых роботов. Определяет частоту индексации - или один раз индексировать, или реиндексировать документ регулярно.
<META NAME="Document-state" CONTENT="Static">
Возможные значения: Static Dynamic
Подробнее об этом в статье
URL
Источники: Spidering
Управление индексацией страницы для поисковых роботов. Определяет частоту индексации - или один раз индексировать, или реиндексировать документ регулярно.
<META NAME="URL" CONTENT="absolute_url">
Подробнее об этом в статье
Author
Источники: HTML редакторы
Обычно имя автора, формат произвольный.
Generator
Источники: HTML редакторы
Обычно название и версия редактора, с помощью которого создана эта страница. Может быть использована для определения доли рынка, занимаемого тем или иным продуктом.
Copyright
Источники: HTML редакторы
Обычно описание авторских прав на документ в произвольном формате
Distribution
Возможные значения global local iu (internal use)
Resource-type
Текущее состояние данного файла. Важен для поисковых систем, т.е. если его значение document, то поисковая система приступает к его индексированию.
Прочие Classification Formatter Site-languages Version Template Operator Rating Creation Host Document Subject Build Random text (<META NAME="Joe Smith">)
Помимо перечисленных более или менее стандартных тагов существует еще множество других специализированных, например, для конкретной поисковой машины тагов.
Будьте бдительны!
Если ваши страницы уже попали в индексы поисковых машин, проверяйте это не реже раза в неделю. Иногда случаются странные вещи. Страницы исчезают из индексов. Линки становятся искаженными. Если Вы заметили подобные вещи - укажите страницы поисковой машине еще раз.
Частота появления ссылок
Основные поисковые машины могут определить популярность документа по тому, как часто на него ссылаются из других мест Сети. Некоторые машины на основании таких данных "делают вывод" стоит или не стоит тратить время на индексирование такого документа.
Чего люди хотят от этой жизни, что спрашивают..
Списки наиболее популярных запросов к поисковым машинам можно посмотреть:
За рубежом:
Вам понадобится броузер с поддержкой Java чтобы увидеть это во всей своей красе
20 случайно выбранных запросов в реальном времени.
200 самых популярных запросов к Yahoo У нас:
Статистика частоты упоминания слов в запросах к поисковой машине Rambler
Что такое метапоисковая система?
Ни для кого не секрет, что всемирная сеть Интернет, содержащая постоянно растущий огромный объем динамически изменяющейся информации, развивается небывало бурными темпами. Для того, чтобы как-то упорядочить этот непрерывный поток данных, а самое главное, дать возможность пользователям Сети находить нужную информацию, были созданы специальные поисковые системы. Каждая такая система имеет индекс, несущий служебную информацию о содержимом проиндексированных документов, где каждому слову текста соответствует частота его употребления и координаты данного слова в тексте.
Каждая поисковая система имеет только свое собственное, ограниченное ее ресурсами, множество документов, которые доступны для поиска. Ни одна из подобных систем не сможет охватить всех ресурсов Интернет, поэтому в любой момент может возникнуть ситуация, когда информационные потребности пользователя не смогут быть удовлетворены. Как правило, в этом случае пользователь переходит на другую поисковую систему и пытается искать то, что ему нужно, там.
Для решения данной проблемы и расширения возможности поиска, были созданы системы, названные метапоисковыми. Они не имеют собственных поисковых баз данных, не содержат никаких индексов и при поиске используют ресурсы множества поисковых систем. За счет этого полнота поиска в таких системах максимальна и вероятность нахождения нужной информации очень высока.
Дата индексирования документа
Некоторые поисковые машины показывают дату, когда был проиндексирован тот или иной документ. Это помогает пользователю понять, какой "свежести" ссылку выдает поисковая система. Другие оставляют пользователям только догадываться об этом.
Description
Этот параметр показывает как поисковые машины генерируют описания ссылок для пользователя в ответ на его запрос.
Доменные имена: реалии Сети
В первые годы становления Паутины доменное имя Web-сервера нередко отождествлялось с именем компании-провайдера, а основную смысловую нагрузку в адресной схеме URL несли названия подкаталогов, поскольку именно они были связаны с реальными поставщиками информации, арендующими дисковое пространство. В сегодняшней Сети стала обычной практика, когда даже не очень крупная компания может позволить себе содержание персонального сервера. Часто доменное имя нового узла регистрируется разработчиком под определенный проект.
Таким образом, если искомое ключевое слово входит в доменное имя сервера, то вероятность получить исчерпывающие сведения о предмете с такого "специализированного" под ваш интерес узла существенно возрастает.
В Интернете можно отыскать немало простеньких пособий 2-3-летней давности, обучающих тому, как сходу угадать имя нужного сервера на основе минимальных начальных данных. Сегодня эти материалы явно нуждаются в уточнении. Навыки игры в "угадайку" при наличии развитой системы поисковых сервисов могут показаться ненужными, однако это не так по двум причинам. Во-первых, если вам повезет, вы можете установить соединение с сервером, который не зарегистрирован ни в одной ИПС (о том, как происходит регистрация см. КомпьтерПресс N 5). Во-вторых, даже если приходится прибегать к URL-поиску на поисковой машине, то угадывание с самого начала хотя бы некоторых элементов адреса существенно сокращает время решения задачи. Начнем с несколько простых, но важных замечаний.
Односложные имена и домены верхнего уровня
Если компания или коммерческий проект, имеющие в "светской" жизни односложное название, реализуют в Сети свой сервер, то его имя с высокой вероятностью укладывается в формат www.name.com, а для российского сектора Интернета - www.name.ru, где name - имя компании или проекта.
Даже беглое знакомство с Сетью показывает, что в качестве названий фигурируют не только имена собственные (напр., www.disney.com - сервер У. Диснея; www.intel.ru -российский узел компании Intel), которые первоначально могут быть и неизвестны, но и те, которые в обычной языковой практике используются как нарицательные.
Если смысловая нагрузка имен очевидна (напр., www.windows95.com - сайт с программами для Windows; www.gazeta.ru - от рус. "газета"), то их легко использовать при поиске. Проблемы начинаются тогда, когда приходится разыскивать названия, воспринятые на слух. Отдельный случай - использование имен неанглоязычного происхождения, в частности русских, которые в строке URL должны быть прописаны средствами латинского алфавита, однако об этом - чуть ниже. Тем не менее если даже предположить, что нам удалось верно восстановить "светское" имя проекта, точное попадание на узел вероятно лишь в случае сравнительно коротких имен, как в примерах выше. Длинные же имена, приходящие в Сеть, могут подвергаться сокращению с большой долей произвола, особенно это относится к сравнительно "старым" серверам государственных организаций. Наиболее употребимо сохранение нескольких первых букв имени с конечной согласной (www.mos.ru - мэрия Москвы, www.chel.su от г.Челябинск), затем идут сокращения с выборочным удалением букв из середины слова, чаще гласных (www.chg.ru - от г. Черноголовка; www.tmsk.ru от г. Томск). Если имя первоисточника многосложное, но одно из слов доминирует по своему весу, то в имени сервера может остаться одна доминанта (узел "Новочеркасск-Он-Лайн" - www.novoch.ru; узел "Чертовы кулички" - www.kulichki.com ) Появление дополнительного домена в имени и отклонение от схемы с наличием элемента "www" делают точное угадывание затруднительным. Примеры - http://hope.nsk.su - узел клуба "Надежда" (от англ. hope) из г. Новосибирска (nsk). В этом случае разумнее обратиться к URL-поиску на ИПС. Если есть основания полагать, что искомый узел базируется в домене определенного государства или является некоммерческим, то в тех схемах, о которых мы говорили выше, вместо com и ru следует подставить нужный домен. Всегда полезно иметь под рукой полный список доменов верхнего уровня по странам. Он опубликован на многих серверах Сети, один из адресов -http://www.uninett.no/navn/domreg.html
Двусложные и многосложные имена
Полное название организации или проекта, открывающих в Сети свое представительство, может состоять и из нескольких слов, которые находят свое отражение в доменном имени узла или, в более общем случае, в URL ресурса.
При этом обычно в имени сервера используется соответствующая аббревиатура. Заметим, что формироваться она может по-разному: из первых букв слов названия, по одной из каждого (www.ndr.ru - от "Наш Дом - Россия"); при участии нескольких первых букв (www.amcyber.com от "American Cybernetics"). Двусложные названия стоят в этом ряду особняком - слов оказывается слишком мало для создания яркой, запоминающейся аббревиатуры. Кроме того свободных двухбуквенных имен в популярных доменах совсем немного. Как показал недавний скандал с компанией General Motors и ее сервером www.gm.com, экономия на длине имени может слишком дорого обойтись солидной организации. Когда стороний разработчик зарегистрировал узел сомнительного содержания под именем www.general-motors.com, ему удалось добиться внушительной популярности сайта на волне ошибочных посещений, а авторитет крупной компании был подорван. Естественно, что двусложные имена сегодня стали часто встречаться без сокращений. Наиболее употребимы такие варианты как слияние двух слов в одно (www.webcrawler.com - от Web Crawler), а также написание их через дефис (www.biblio-globus.ru от Библио Глобус). Другие разделители встречаются гораздо реже. Применяются также и частичные аббревиатуры (www.cpress.com от КомпьютерПресс), и распределение имен по разным доменам (http://altavista.digital.com).
Именной сленг
Применение сленга всегда связано со стремлением к более яркой, живой лексике, однако есть и обратная сторона медали - сленг понятен не всем. Одним из проявлений, которое следует отнести к сленгу, является присутсвие в Сети большого количества серверов, имена которых неадекватны содержимому узла, но звучат ярко и метафорично (напр., портал www.stars.ru. - от англ. stars - звезды с отнюдь не астрономической тематикой). Ставка разработчика на то, что оригинальность имени облегчит продвижение сайта и увеличит его видимость в Сети вполне понятна, однако URL-поиск таких узлов на ИПС может оказаться бесполезным.
Скажем, если вы разыскиваете сетевой книжный (англ. book) магазин (shop, store), то один из вариантов запроса может иметь вид url:(book and shop), где для определенности использован синтакис команд расширенного поиска AltaVista. При этом узел "Мистраль" (www.mistral.ru от англ. mistral - холодный сев. ветер на юге Франции), довольно известный подборкой компьютерной литературы, наверняка не попадет в поле вашего зрения. В этом проявляется ограниченность URL-поиска в чистом виде. Часто в доменных именах наряду с буквами появляются и цифры (узел Тысяча мегагерц - www.1000Mhz.ru ). Речь здесь, разумеется не идет об IP- адресах, хотя цифровой состав последних вполне можно использовать при URL -поиске. Некоторые находки авторов оказываются трудно предсказуемыми. Так, цифрой 4 могут заменяться предлоги за и для (от англ. 4 - four, звучащего так же как и предлог for со значением за, для) в сочетаниях типа 4free (за бесплатно) и 4you (для вас). Цифра 2 применяется как эквивалент предлага to также из-за совпадения звучания (от 2 - two, произносимого как предлог to - в, к, по направлению), например, в сочетаниях типа death2life (c англ., от смерти к жизни). Иногда эту цифру можно встретить не в доменном имени узла, а в конечном файле - программе преобразования одного формата данных в другой (напр., bmp2gif.exe - от bmp к gif). Известный сервер программного обеспечения "Two Cows" ("Две коровы") использует "ошибочное" (т.е. tu вместо two) написание своего имени - www.tucows.com (рис. 3).
Достижение оптимального индексирования Вашего сервера поисковыми машинами
Нет никакого волшебства и секретных методов для того, чтобы заставить страницу появиться в начале листинга любой поисковой машины. Каждая поисковая машина определяет релевантность по-своему. В довершение всего появляются новые страницы, старые обновляются - соответственно меняется и листинг.
Ниже предлагаются несколько общих советов, которые могут помочь Вам увеличить появление Ваших страниц в листингах поисковых машин. Часто это очень простые идеи, которые были выпущены из виду. Все эти советы расширены дополнительной информацией о дизайне и управлении страницами (в разрезе поисковых машин).
Excite Search
Запущенная в конце 1995 года, система быстро развивалась. В июле 1996 куплена Magellan, в сентябре 1996 - приобретена WebCrawler. Однако, оба используют ее отдельно друг от друга. Возможно в будущем они будут работать вместе.
Существует в этой системе и каталог - Excite Reviews. Попасть в этот каталог - удача, поскольку далеко не все сайты туда заносятся. Однако информация из этого каталога не используется поисковой машиной по умолчанию, зато есть возможность проверить ее после просмотра результатов поиска.
Фреймы могут погубить Ваши усилия.
Некоторые поисковые машины не могут проводить индексацию по ссылкам из FRAMESET. Чтобы избежать этого необходимо обеспечить альтернативный вход и индексацию страниц, использовать META-таги или упростить дизайн. Более подробно об этом можно прочитать .
Глубина индексирования
Этот параметр относится только к не указанным страницам. Он показывает сколько страниц после указанной будет индексировать поисковая система.
Большинство крупных машин не имеют ограничений по глубине индексирования. На практике же это не совсем так. Вот несколько причин, по которым могут быть проиндексированы не все страницы:
не слишком аккуратное использование фреймовых структур (без дублирования ссылок в управляющем (frameset) файле )
использование imagemap без дублирования их обычными ссылками
Поисковые системы - статьи
Автор: Phil Craven ()
Перевод статьи:
Как и большинство наиболее известных поисковых систем, Google учитывает понятие темы в той мере, в которой она влияет на рейтинг сайтов. Некоторые часто удивляются, что их страницы с индексом цитирования, равным 6, вытесняются страницами с более низким рейтингом (5 или 4) при определенных поисковых запросах. На это существует масса причин. И одна из них - это тематика сайта. Хорошим примером может служить сайт . Во время написания данной работы, этот сайт содержал всего 5 страниц, и все из них были проиндексированы Google. На этот сайт ссылаются несколько сайтов со средним PR (индексом цитирования), а на одной из страниц сайта - ссылка из . Как результат, 4 страницы сайта имеют PR 4, а страница, связанная с DMOZ - PR 5.
Маленький сайт "перебивает" по рейтингу страницы с более высоким PR на сайтах большего размера. Почему? Потому что сайт индексируется как одна целая тема. Он посвящен только одной тематике. Даже на главной странице слово "PageRank" встречается несколько раз.
Некоторые сайты вмещают в себя разделы, посвященные совершенно разным темам, и это приводит к "размытию" общей тематики сайта и уменьшению PR.
Вот одна из причин, по которой страницы с более низким PR иногда "перебивают" страницы с более высоким PR.
Помимо тематики существует множество факторов, влияющих на определение релевантности страницы (сайта). Если я добавлю на сайт несколько страниц, содержимое которых значительно отличается от главной темы сайта, то PR, отражающий целостность собранной на сайте информации, ухудшится. Какими бы ни были отступления от темы, они негативно влияют на PR сайта. Хотя сайт по-прежнему будет содержать страницы, подобранные по тематике, главная тема сайта немного "размоется". В примере о сайте ювелирных изделий, каждая страница рассказывает об определенном виде изделий - ожерельях, браслетах, кольцах и т.д. Но общая тема сайта - "ювелирные изделия", а не "ожерелья". Если же взять сайт, описывающий только ожерелья, то и тема у него будет "ожерелья". И по этому ключевому слову он имеет все шансы опередить в рейтинге сайт с темой "ювелирные изделия". Это, конечно, будет зависеть от множества факторов, и тема - один из самых важных.
Большинство сайтов не останавливаются на подробном описании лишь ожерелий или какой-то другой темы. Как правило, они включают в себя топики общего характера. Однако в наших силах улучшить тематическую направленность сайта и более четко определить темы для каждой страницы.
Представим, что сайт ювелирных изделий содержит информацию о браслетах, кольцах и ожерельях, - причем, каждая страница сайта рассказывает обо всех трех видах изделий. Как при этом определить тему страницы и тему сайта? Информация об этих изделиях распределена по всему сайту и страницам в произвольном порядке. Поэтому тему каждой отдельно взятой страницы трудно определить однозначно. Ни на одной из страниц сайта информация о каком-либо одном виде изделий не будет преобладать над прочими. Это верно и для темы сайта.
Теперь давайте предположим, что сайт тематически разбит на разделы, в которых отдельно друг от друга рассматриваются ожерелья, кольца и браслеты. Содержание страницы каждого раздела строго соответствует тематике. Это обеспечивает страницам более высокий рейтинг по заданной теме поиска.
Поисковые системы - статьи
, #01/2003
Любая автоматизированная информационно-поисковая система (ИПС) состоит из двух основных частей: формирователя собственной базы данных и генератора ответов на запросы пользователей. Главными показателями для первой являются ее объем и продуманность внутренней структуры, а для второй - скорость поиска информации и удобство пользования. На самом деле такое деление очень условно, потому что функциональная гибкость запросов изначально зависит от структуры базы данных: невозможно запросить что-то, что не было заложено в алгоритмы разработчиками.
Скажем, можно создать программу (Интернет-робота), которая будет скачивать все содержимое глобальной сети (если позволяют каналы связи) и сваливать эту информацию в одну кучу. Но, даже обладая всем этим богатством, невозможно потом будет хоть как-нибудь им воспользоваться. Конкретный поиск в неструктурированной базе данных заставит обработчик запросов полностью (!) просмотреть все содержимое кучи. Именно поэтому создатели поисковых систем и баз данных вводят индексацию внутренней структуры. То есть упрощенно под индексом можно понимать нечто, помогающее существенно ускорить поиск (алгоритмы, способы обращения к большим объемам информации, способы упорядочивания и хранения данных и т. д.).
С другой стороны, пусть существует хорошо проработанная база данных. По определенному запросу пользователя программа-обработчик поисковой системы выдаст множество документов, где встречается заданное словосочетание. Задачей номер один для создателей ИПС является такая сортировка результатов поиска, чтобы в самых первых позициях находились именно те документы, которые были затребованы. Этот параметр называется релевантностью ответа. Если задать в поиске только общие слова, например , тогда как вы ищете информацию про его ингредиенты, вряд ли в первой паре страниц отчета вам выдадут то, что вы искали. Поисковая система просто не в состоянии знать ваши мысли. Поэтому, задавая запрос, максимально конкретизируйте его для получения наиболее точного результата.
Давайте изучим внутреннюю структуру ИПС на примере Google ().
Google появился сравнительно недавно, в 1998 г.
Его создатели, сотрудники Стенфордского университета (США) Сергей Брин и Лоуренс Пейдж, постарались сделать его механизм более гибким и расширяемым, чем существовавшие на то время у грандов поиска - Аltavista и Inktomi. На данный момент Google и Fast (еще одна ИПС, www.alltheweb.com) имеют самый большой объем проиндексированных страниц - более двух миллиардов (данные на июль 2002 г.). Речь идет не только о собственно html- и xml-документах, но и pdf, doc и даже флэш-анимации. Причем только Google, в отличие от других иностранных ИПС (мы не рассматриваем "Яндекс", "Рамблер> и <Апорт>), хорошо индексирует русскоязычные Web-ресурсы в зоне.ru.
Почти в каждой поисковой системе есть своя внутренняя система оценки <качества> документов. В Google она называется PageRank (PR). Суть ее заключается в том, что при решении о порядке выдачи пользователю списка страниц, попадающих под его запрос, во внимание принимается некий коэффициент, зависящий от количества ссылок с других сайтов на эту страницу и от их популярности. На самом деле в этом есть рациональное зерно. Ведь если рассматриваемая страница действительно такая важная, что ее стоит прочитать, скорее всего, на нее уже ссылаются другие источники. Верно и обратное: если на документ никто не ссылается - кому он тогда нужен?! Причем PageRank - это не просто общая сумма ссылок, это нормализованное отношение количества ссылок, приводящих на данную страницу, к количеству исходящих c нее. Расчетная формула, опубликованная С. Брином и Л. Пейджем, выглядит следующим образом:
где d - эмпирически подобранный коэффициент (d=0.85); Т1...Tn - страницы, ссылающиеся на рассматриваемый документ; С(Tn)... С(Tn) - общее количество ссылок, ведущих вовне со страниц Т1...Tn.
Отсюда видно, что PageRank любого документа зависит от PageRank документов, с которых возможен переход на него. Таким образом, он всегда будет высоким для страниц, имеющих популярность в Интернете.
Важно также отметить, что PageRank имеет смысл вероятности, с которой среднестатистический Интернет-путешественник попадет на определенную страницу, хаотически блуждая по ссылкам.
Сумма PageRank всех страниц равна единице
где N - количество проиндексированных страниц).
Вышеприведенная формула достаточно проста, и если задаться целью построить некоторое количество взаимосвязанных страниц, то, по-видимому, PageRank каждой может быть искусственно завышен. Например, можно попытаться сократить число ведущих вне ссылок и создать большое кольцо, в котором документ ссылается только на <друзей>. Тогда каждый из них вследствие итеративности алгоритмов расчета PageRank будет иметь достаточно высокий коэффициент <важности>. Несмотря на это в модели Google, вероятно, предусмотрены какие-то механизмы, позволяющие не начислять слишком высокий PageRank <подозрительным> и <нежелательным> сайтам. И естественно, эти механизмы являются ноу-хау и не подлежат разглашению.
Еще одна важная черта ИПС Google заключается в том, что в ней хранятся описания ссылок на проиндексированные страницы. Эта особенность позволяет более адекватно проводить поиск в накопленной базе данных. Скажем, автор странички забыл указать ее название между тегами <title></title>. Любая ИПС при выдаче результатов поиска ставит высокий приоритет словам, указанным именно в названии. В этом случае Google будет ориентироваться по текстам ссылок на эту страничку, справедливо основываясь на предположении, что если кто-то ставит ссылку на что-то, то уж, по крайней мере, он эту страничку изучил и постарался наиболее емко отобразить ее содержание в тексте ссылки. Именно поэтому во всех наставлениях по правильному оформлению содержимого документов имеется следующий совет.
Никогда не ставьте ссылку под словами <здесь>, <тут>, <сюда> (например: полную версию постановления смотри <a href=<...>>здесь</a>). Попробуйте написать так: <на сайте есть также и <a href=<...>>полная версия постановления</a>>. Кстати, сказанное верно еще и потому, что почти во всех браузерах текст внутри тега <a> подсвечивается тем или иным образом (выделяется подчеркиванием, цветом).
Глаз при беглом просмотре странички более вероятно зацепится за выделенные информативные слова, чем за неконкретное краткое наставление <вам сюда>. Как говорится, покупатель и продавец, будьте взаимно вежливы!
Кроме расчетов PageRank и запоминания текста ссылок, Google хранит шрифтовой размер и смещение каждого слова относительно начала документа. (Примечание: некоторые ИПС ориентируются также и на цветовое выделение слов относительно текста.) В спецификации HTML 3.2 было определено семь уровней заголовков по размеру шрифта (от <h1> - самого крупного, до <h7> - самого мелкого). Поэтому поисковик всегда выдаст по запросу документ, в котором данное слово выделено более крупным шрифтом или находится ближе к его началу. Благодаря тому что система знает конкретное место каждого слова в документе, становится возможен так называемый Proximity search - поиск по наиболее близкому расположению слов друг относительно друга. Например, по запросу <слово1 слово2> ИПС найдет много документов у себя в базе данных, но в отчет в первых строках пойдут только те, в которых <слово1> находится максимально близко слева от <слова2>.
Теперь более подробно рассмотрим схему функционирования информационно-поисковой системы Google. Всю основную работу по просеиванию сквозь себя содержимого Сети выполняют Интернет-роботы (боты, crawlers). Каждый из них берет один адрес (URL, uniform resource locator; каждый URL соответствует определенному идентификатору документа) из базы данных URL-сервера, скачивает и передает содержимое странички на сервер хранения документов (рис. 1). Необходимо отметить, что все содержимое сервера хранится в заархивированном виде для увеличения его вместимости.

Рис. 1. Структура информационно-поисковой системы Google
Другая программа - индексатор - занимается тем, что разлагает текст документа на составляющие его слова (хит в терминологии Google), запоминая при этом местонахождение, шрифтовой вес, а также написано ли слово заглавными или строчными буквами и принадлежит ли оно к категории <особенных> (названия документов, метатеги, URL'ы и тексты ссылок).
Вся эта информация складывается в набор контейнеров, именуемых на рисунке прямым индексом. Структура хранимых в нем данных выглядит следующим образом (рис. 2).

Рис. 2. Структура прямого индекса (doc_id - идентификатор документа; word_id - идентификатор слова; null_word - символ окончания документа; n_hits - частота, с которой слово встречается в документе)
Идентификаторы слов берутся из словаря, который постоянно пополняется. Одновременно с этим индексатор просматривает содержимое тегов <a></a> и проверяет корректность всех ссылок в службе разрешения имен DNS (domain name service). Если ему встретился URL, которого нет в базе данных по doc_id, он пополняет не только ее, но и коллекцию ссылок. В дальнейшем этот Интернет-адрес попадает в URL-сервер и круг замыкается. Система поиска новых документов, при условии, что на них хоть кто-нибудь ссылается, становится самодостаточной - она сама себя подпитывает.
Но каким образом ИПС узнает о новых Web-ресурсах, которых еще никто не успел посетить? Для разрешения этой проблемы разработчики предусмотрели ручную форму регистрации ресурсов в поисковой системе. Введенные в нее адреса после проверки на корректность также попадают в URL-сервер.
Заметим, что каждая из программ, обозначенных на рис. 1 эллипсом, работает независимо от других, причем аппаратные конфигурации серверов и рабочих станций, на которых функционирует <движок> Google, выбираются так, чтоб не создавать <пробок> при обработке информации, собранной Интернет-роботами.
Описанная выше структура прямого индекса не очень удобна при поиске документов на основании встречающихся в них слов (пользователь задает слово или словосочетание, а система должна найти подходящий документ). Чтобы решить эту проблему, был введен так называемый инверсный, или обратный, индекс (рис. 3). В нем любому слову из словаря соответствует набор doc_id-документов, в которых это слово встречается. Работой по постоянному формированию инверсного индекса занимаются сортировщики.
Так как, во-первых, всегда появляются новые документы и, во-вторых, обновляются старые, индекс приходится постоянно перестраивать.

Рис. 3. Структура инверсного индекса (word_id - идентификатор слова; ndocs - количество документов с этим словом; doc_id - идентификатор документа; n_hits - частота, с которой слово встречается в документе)
Пусть от пользователя поступил запрос найти документы со словом <мухобойка>. Программа, формирующая ответы, посмотрит в словарь, найдет там word_id для <мухобойки>, сформирует запрос в базу данных с использованием инверсного индекса и получит набор документов, в которых это слово встречается. Далее на основании PageRank, количества хитов, их качества и, может быть, других ограничений и приоритетов разработчиков будут распределены порядковые номера страниц в выходном списке. В итоге Интернет-пользователь получит самую оптимальную, по мнению ИПС, информацию о том, где и что писали о правилах и способах мухоубийства.
Качество поисковой системы, как уже было отмечено, зависит не только от количества проиндексированных документов, правил их отбора в итоговый список, но и от того, как часто Интернет-роботы заново проверяют содержимое ранее обработанных сайтов. В таблице на примере thermo.karelia.ru приведены данные об общем объеме запрошенных роботами документов и количестве заходов на сайт (по данным Webalizer - анализатора журналов Web-сервера).
Из таблицы видно, что роботы <Яндекса> и Google ведут себя по-разному. <Яндекс> останавливается на корневом документе Web-сервера (например, index.html) и скачивает содержимое сайта последовательно, документ за документом, в один поток. Google распараллеливает работу между несколькими роботами, причем каждый из них при скачивании может <отвлекаться> на другие дела. То есть эти две поисковые системы характеризуются совершенно различными структурами URL-серверов и способами пополнения информации из Интернета.
Второй важный вывод, который напрашивается по результатам изучения приведенной таблицы, заключается в том, что русскоязычные поисковики <лучше> иностранных, они более часто посещают ресурсы постсоветского пространства.
Даже <Апорт>, уступивший на данный момент третье место Google по общему количеству обрабатываемых запросов (данные с www.spylog.ru), как минимум раз в месяц просматривает содержимое каждого сайта.
Последние две строчки в таблице требуют некоторых пояснений. За надписью Sunet.ru скрывается один из московских провайдеров Интернет-услуг (e-Style). Причем поражает завидное постоянство, с которым действует их робот. Какой из поисковых систем они предоставляют информацию и предоставляют ли ее вообще - автору неизвестно.
Dec.com - робот некогда существовавшего гиганта Digital Equipment Corporation (впоследствии он был перекуплен компанией Compaq). Dec поддерживал Altavista, поэтому можно предположить, что получаемая информация идет в закрома самой известной ИПС.
В заключение хотелось бы заметить, что каждый сайт строится уникальным образом, имея линейную, древовидную или смешанную структуру. Одни построены на документах с динамическим контентом, другие вообще статичны и не изменяются. По-видимому, будет существовать разница даже в процессе индексации постоянно изменяющихся сайтов, имеющих динамическое содержимое. Не секрет, что целая категория Web-ресурсов, отнесенных к разделу новостных, просматривается чуть ли не ежеминутно.
На основании изложенных соображений можно выделить ряд рекомендаций создателям Web-ресурсов для улучшения позиций их проектов в рейтингах информационно-поисковых систем (впрочем, не только для этого):
четко продумывать структуру каждого сайта; называть каждую страницу уникальным именем, максимально отражающим ее содержимое; избегать использования одного и того же имени файла для группы документов с передачей после него различных параметров (например, index.php? razdel=1&document=2) (программисты иногда забывают менять значение переменной, содержащей название документа); избегать навигации "плохо индексируемыми" способами (формы, флэш-анимация).
HotBot
Запущена в мае 1996. Принадлежит компании Wired. Базируется на технологии поисковой машины Berkeley Inktomi.
Имена собственные. Русско-английская транслитерация.
Практика показывает, что большинство деловых поисковых задач в Интернете в той или иной степени связано с поиском имен собственных - названий компаний и организаций, всевозможных стандартов, оборудования и т.п. Любимые стихи и биографию эстрадной звезды также проще отыскать по личным именам. Во многих поисковых ситуациях, которые, казалось бы, не имеют прямого отношения к именам собственным, привлечение последних обеспечивает наибольшую результативность. Например, если вы решили разыскать в Сети фотодокументы, имеющие отношение к кометам и в целом к космической тематике, то применение термина NASA (аббревиатура Американского Национального Управление по Аэронавтике) как одного из элементов запроса, не только облегчит задачу, но и даст некоторые гарантии достоверности информации.
Многие наименования имеют национальное происхождение и появляются в тексте документа в оригинальном написании - с использованием символов соответствующих алфавитов - немецкого, французского, японского и др. Если такое имя попадает в URL ресурса, то разработчик вынужден прописать его средствами латинской графики. Сама по себе проблема транслитерации, т. е. точной передачи букв или сочетаний букв одного языка средствами алфавита другого языка, не нова. Трудно добиться взаимной однозначности такого перевода в прямом и обратном направлениях без разработки жестких стандартов. В мире хорошо известны ИСО (www.iso.ch)- стандарты по транслитерации языков всех континентов из одной графики в другую, которыми широко пользуются в алфавитных каталогах иностранной литературы. Однако имена в Интернете дают не специалисты библиотечного дела. Это и приводит к стихийному размыванию стандартов и появлению реальных проблем при поиске.
Если говорить о русских наименованиях в Сети, присутствующих в URL ресурсов, то от стандарта ISO-9-1986 -(E)/ISO/TC 46 по транслитерации знаков славянской кириллицы знаками латинского алфавита наблюдаются заметные отклонения. Существование нескольких русских кодировок типа translit для обмена почтовыми сообщениями, англоязычное происхождение самого Интернета, а также доминирование в образовательной системе России английского языка над другими определяют тенденции таких отклонений.
В таблице 1 мы приводим обобщенную русско- латинскую систему транслитерации, фактически тяготеющую к русско-английской. Она составлена на основе анализа большого количества имен российской части Интернета и нескольких распространенных в Сети схем транслитерации.
| а | a |
| б | b |
| в | v, w |
| г | g, h, gu |
| гв | gv, gw, gu |
| гз | gz, x |
| д | d |
| дж | dzh, j, g |
| е | e, ye, je, ie |
| ё | e, yo, io, ye, ie, jo,je |
| ж | zh, g, j |
| з | z, s |
| и | i, y |
| ия | ia, iya, ija |
| й | y, i |
| ий, ый | на конце слов y, iy, i, ii |
| к | k, c, ch |
| кс | ks, x |
| кв | kv, kw, qu |
| л | l, ll |
| м | m |
| н | n |
| о | o |
| п | p, pp |
| р | r , rr |
| с | s, c, ss |
| т | t, th |
| у | u |
| ф | f, ph |
| х | kh, h |
| ц | ts, tz |
| ч | ch |
| ш | sh, ch |
| щ | shch |
| ь | опуска-ется, "'" |
| ъ | опуска-ется, "'" |
| ы | y, i |
| э | e |
| ю | yu, u, ju, iu |
| я | ya, ia, a |
табл.1.) Тем не менее не все возможные варианты оказались учтены, поскольку нет смысла еще больше размывать систему транслитерации случаями, связанными c факторами чисто английского языкового происхождения. Если вам, скажем, понадобилась, компания известная под именем Мун, то имя узла www.mun.com вполне может оказаться неверным, если первоисточник подразумевал английское Moon (луна) со своим специфическим написанием. Варианты типа у-oo не включались в таблицу. В подобных ситуациях, требующих хорошего знания иностранного языка как такового и его звуко-графических соответствий, целесообразно прибегать к так называемым словарям "плохого произношения". В них обычно приводится все многообразие графических вариантов проблемно звучащей лексики. На сегодня можно считать почти состоявшейся замену ранее активно используемой "пронемецкой" литеры j для передачи русских гласных (у - ju, ё -jo, я - ja,и реже е - je ) на "более английский" вариант - литеру y (yu, yo, ya, реже ye). Русская буква е обычно заменяется латинской e, особенно после согласных (www.perm.ru - от г. Пермь). После гласной встречается как литера e (www.krylatskoe.msk.ru - от Крылатское), так и сочетание ye (Krylatskoye). Букву й в середине слова чаще заменяет литера i (Doinov - фамилия Дойнов, далее сокр. ф.), а в конце слов после гласной - y ( Rushchay - ф. Рущай). Сочетания -ий и -ый на конце слов чаще передаются единственной буквой y (www.primorsky.ru - от Приморский край), но есть и другие варианты (www.mari.su - от республики Марий Эл). Для буквы я применяется также несколько способов ее передачи: ya - обычно появляется после согласной или в начале слова (www.bryansk.ru -от г. Брянск; www.yaroslavl.su - от г. Ярославль, но и www.krasnoyarsk.ru от г. Красноярск), a чаще встречается после гласной, особенно после i на конце слов (www.karelia.ru - от респ. Карелия) Что касается мягкого и твердого знаков, то в URL они обычно никак не передаются (www.citynet.kharkov.ua - от г.
Харьков), хотя в поле текста Web-страницы можно столкнуться с использованием апострофа (Solov'ev - ф. Соловьев ). Наконец, русская ы наиболее часто передается с помощью y (www.syzran.ru от Сызрань), i используется для этого гораздо реже. Русские доменные имена Отечественные разработчики активно эксплуатируют английскую и русскую лексику, давая имена Web-узлам. Если вы решили почерпнуть из Сети материалы по изучению английского языка, то пробный заход на www.language.ru (от англ. language - язык) оказался бы результативным. Адрес сервера, связанного с языковым образованием, вряд ли мог иметь вид www.yazyk.ru - это выглядело бы скорее забавно, чем привлекательно. Однако компании, реализующей на российском рынке сахар, которая открывает в Сети свой узел, есть над чем подумать - сервер с именем www.sakhar.ru (или www.sahar.ru) может оказаться чуть более видимым для потенциального клиента, чем www.sugar.ru (от англ. sugar - сахар). Сайт телепрограммы Моя семья, претендующий на самую широкую российскую аудиторию вполне резонно именует себя www.moya-semya.ru, а не www.my-family.ru (c англ. my family - моя семья). Тем не менее понятно, что, даже ориентируясь на "прогрессивную" поблику, в некоторых случаях приходится отдавать дань традициям политической и культурной жизни государства. Например, большинство политических образований и движений России предпочитает поддерживать в качестве основных узлы в домене ru с соответствующими русскими названиями (напр. www.yabloko.ru - объединение "Яблоко"). Некоторые транслитерированные наименования едва заметно отличаются от английских эквивалентов, напр. literature (англ.) и literatura (рус.), что также требует аккуратного обращения. В заключение отметим, что одной из целей этой статьи было привлечь внимание читателя к возможностям URL-поиска в Web-пространстве. Найденный узел или каталог - это почти всегда более емкое, чем единичный документ, собрание материалов. Особое предпочтение здесь следует отдать тем поисковым системам, которые позволяют комбинировать URL-запросы с внутритекстовым поиском, а также выборочно работать с фрагментами адреса - доменным именем узла, доменом верхнего уровня, именами каталогов и файлов.Другой важный аспект работы в Сети -это корректное применение имен собственных, которые способны стать опорными ключевыми словами для широко спектра поисковых задач и обеспечить высокую результативность поиска.
Имя поискового робота
В этом пункте указаны имена роботов, которыми они отвечают на HTTP-запрос. Полезно для написания robots.txt. Подробнее смотри
InfoSeek
Запущена чуть раньше 1995 года, широко известна, прекрасно ищет и легко доступна. В настоящее время "Ultrasmart/Ultraseek" содержит порядка 50 миллионов URL.
Опция для поиска по умолчанию Ultrasmart. В этом случае поиск производится по обоим каталогам. При опции Ultraseek результаты запроса выдаются без дополнительной информации. Поистине новая поисковая технология также позволяет облегчить поиски и множество других особенностей, которые Вы можете прочитать об InfoSeek
Существует отдельный от поисковой машины каталог InfoSeek Select.
Интерактивность. Что может быть лучше? Однако...
Генерация страниц через CGI или необходимость использования баз данных? Ожидается, что некоторые поисковые машины не будут индексировать подобные страницы. Рекомендации могут быть следующими: создание статических страниц везде, где это возможно, использование баз данных для обновления уже существующих и при этом статических(!) страниц, ни в коем случае не генерировать их на лету. Еще одна деталь: очень плохо относятся поисковые роботы к специальным символам в URL, особенно к символу '?'
Поисковые машины это основной путь,
Поисковые машины это основной путь, по которому люди могут зайти на Ваш сайт, однако не единственный. К числу оставшихся путей можно отнести традиционную рекламу, средства массовой информации, почтовые рассылки и информация из телеконференций, рекламные сети, веб-каталоги и ссылки с других серверов. Зачастую эти пути далеко не так эффективны, как при использовании поисковых машин.
Измерение популярности
Лучший способ определить как люди попадают на Ваш сервер - посмотреть файл статистики (если конечно он содержит поле HTTP_REFERER). Можно сделать это и с помощью поисковых машин. Общий для всех машин способ - набрать имя сервера, однако в этом случае в результаты запроса попадут и страницы самого сервера. Более продвинутые способы проверки наличия ссылок на Ваш сервер с других изложены ниже.
Alta Vista
Чтобы проверить наличие ссылок на Ваш сервер с других достаточно набрать в окне запроса:
link:citforum.ru
Excite
Просто наберите URL Вашего сервера в окне запроса
HotBot
Наберите URL Вашего сервера в окне запроса и смените опцию "all of the words" на "links to this URL"
Infoseek
Поисковая машина Infoseek предоставляет возможность измерить популярность сервера на странице"Special Searches":
WebCrawler
Как и на InfoSeek здесь есть специальная страница:
Как же все это работает?
Ниже будет описан принцип работы метапоисковой системы , разработанной автором этой статьи, однако общие принципы будут верны и для остальных систем этого класса (см. рис. 2).
Начнем со стартовой страницы данной метапоисковой системы. Обычно интерфейс такой системы предельно упрощен и сразу же позволяет понять, что, где и как здесь можно искать. В нашем случае (MetaPing) поиск возможен по трем областям поиска: по России, по Украине и по всему миру, при этом имеется возможность искать все, отметив поиск по интернету, или сузить область поиска и искать конкретно объявления, новости, файлы и рефераты (рис. 3).
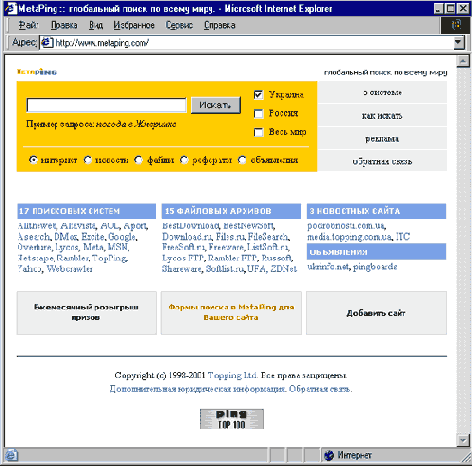
Рис.3 Стартовая страница MetaPing
Пользователь выбирает, скажем, поиск по России, и вводит, например, такой запрос: (рис. 4).
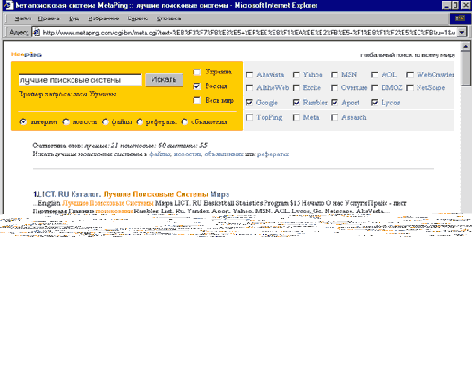
Рис. 4 Страница MetaPing с результатами поиска
После этого запрос ретранслируется указанным российским поисковым системам (в нашем случае это Рамблер, Апорт, Lycos и Google). Следует отметить, что Google, хотя и не является российской поисковой системой, в настоящее время успешно с ними конкурирует как по полноте баз, так и по качеству поиска, и именно поэтому он здесь оказался. Кстати, внимательный читатель наверняка отметил отсутствие самой крупной российской поисковой системы Яндекс. На момент запуска MetaPing Яндекс тоже здесь тоже присутствовал, но после его пришлось убрать.
Для передачи запроса к поисковой системе используется специальный метапоисковый агент, который отвечает не только за процесс ретрансляции запроса и приема страниц, но и за то, чтобы запрос был передан в правильной кодировке, принятой в каждой из выбранных поисковых систем, иначе будет получен совершено другой набор описаний документов или не будет получен вовсе, что негативно скажется на качестве поиска.
После обработки полученного запроса каждая система возвращает метапоисковому агенту множество описаний и ссылок на документы, которые считает релевантными данному запросу.
Как среди этого множества выбрать именно то, что нужно пользователю?
В начале этой статьи уже упоминался стандартный подход, который используется большинством систем метапоиска и состоит в том, чтобы просто расположить полученные ссылки по порядку их следования в результатах поиска каждой из поисковых систем.
При этом, если в разных поисковых системах был найден один и тот же сайт, то ценность его для пользователя, естественно, существенно повышается. Подход, безусловно, правильный, но что делать в том случае, если одна система, к примеру, индексирует динамически генерирующиеся страницы, а другая нет? У них различные множества проиндексированных документов, различная полнота баз, следовательно, запрошенная пользователем информация может быть найдена в одной системе и может быть не найдена в другой. В этом случае пользователь может получить несколько действительно релевантных ссылок от одной системы, которые будут перемешаны с абсолютно нерелевантными из другой (например, в случае, когда фраза целиком не найдена, поиск идет по одному из ключевых слов запроса). В результате, пользователю вручную приходится отбирать релевантные ссылки и велика вероятность того, что покопавшись в подобном "винегрете", он попросту уйдет и уже никогда не вернется. Есть ли какой-либо способ решить эту проблему? Конечно есть. Нужно с полученным от поисковых систем множеством описаний документов сделать то же, что делают они сами с этими документами, то есть определить частоты ключевых слов в каждом заголовке и описании и попытаться самостоятельно определить рейтинг каждого из них. Именно по такому принципу построена метапоисковая система MetaPing, где реализован смешанный алгоритм обработки информации. Автором были разработаны специальные программы для анализа полученных данных, благодаря которым на первом этапе происходит ранжирование множества описаний полученных документов, на втором ранг дополнительно корректируется согласно месту, на котором находится документ, и общему количеству документов, найденных по запросу (это позволяет оценить полноту поисковых баз конкретной системы). Подобная обработка позволяет не только убирать документы, в описании которых вообще нет ключевых слов как потенциально нерелевантные запросу, но и находить строгое соответствие в том случае, если все ключевые слова встречаются в описании документа полностью, что неизмеримо повышает качество и точность поиска.
Контроль индексации
Показывает, какими средствами можно управлять той или иной поисковой машиной. Все крупные поисковые машины руководствуются предписаниями файла robots.txt. Некоторые также поддерживают контроль с помощью META-тагов из самих индексируемых документов.
Копирование фреймов
Note: Этот материал предназначен для тех, кто достаточно хорошо знаком с фреймовыми структурами. Если это не так, рекомендую ознакомиться сначала с информацией о фреймах и их использовании .
Большинство поисковых машин не умеют работать с фреймовыми структурами. Они не будут проверять ссылки, определенные в структуре FRAMESET. Для того чтобы поисковые машины отработали таки ссылки из FRAMESET следует предпринять специальные меры по дублированию ссылок из FRAMESET в конструкции NOFRAMES. Теперь подробнее:
В большинстве случаев фреймовые структуры используются для обеспечения удобства навигации внутри сервера. В маленьком фрейме делаются ссылки на разделы сервера, в большом отображаются собственно документы с информацией. То есть с помощью маленького фрейма идет управление переходами по большому. Рассмотрим простой пример.
Имеется структура из двух окон: в одном отображается навигационное меню, во втором - информация по каждому из пунктов.
Поисковые машины похожи на уже устаревшие версии броузеров типа первых Netscape Navigator и MS Internet Explorer, которые еще не умели работать с фреймами. Когда робот заходит на управляющий фреймами файл, он видит только содержимое NOFRAMES, а именно строку "Извините! Для просмотра этого сайта необходимы броузеры, поддерживающие фреймы!". Вы думаете, подобное способствует успешной индексации сервера? Ни одной ссылки нет, идти роботу некуда. Соответственно он вносит в индекс поисковой машины эту строчку и отваливает, а сотни Ваших прекрасных и полезных страниц оказываются для него не видны.
Одним из решений подобной проблемы могут быть для этой страницы, однако это лишь частичное решение, поскольку не все поисковые машины поддерживают META-таги. Кроме того, не забывайте про людей, пользующихся старыми версиями броузеров. Ведь они увидят все ту же единственную строку, и пойти дальше им некуда! Им остается лишь нажать кнопку "Back".
Второе решение таково: в содержимое NOFRAMES вставляется полный каталог документов Вашего сервера или что-либо в этом роде.
Получается типичная карта сервера, пусть не такая симпатичная как с использованием фреймов, зато и люди видят, куда им дальше податься и роботы поисковых машин могут идти по ссылкам и индексировать содержимое. У этого решения есть два узких места:
Вебмастеру при обновлении сервера приходится следить за корректностью фреймовой части и не забывать обновлять содержимое NOFRAMES.
Если человек попал не на заглавную страницу сервера, он увидит документы без фреймов. А если в документе нет навигационных средств (ссылок дальше), получается ситуация "Dead end". Поэтому при создании сервера с использованием фреймов не забывайте включать средства навигации в каждый документ!
Мой Вам совет: используйте фреймы только тогда, когда без них уже ну никак нельзя обойтись.
Источники информации о фреймах и их использовании
Framing the Web
An excellent introduction and tutorial on creating frame sites.A Compendium of HTML Elements
The ABCs of HTML tags, including frame-related tags.
Литература
Eric J. Glover, Steve Lawrence, Michael D. Gordon, William P. Birmingham, C. Lee Giles - "Web Search - Your Way"
Adele E. Howe Daniel Dreilinger – "SavvySearch: A MetaSearch Engine that Learns which Search Engines to Query"
Вячеслав Тихонов - "Поисковые системы в сети Интернет"
Weiyi Meng, Clement Yu, King-Lup Liu – "Building Efficient and Effective Metasearch Engines"
Zonghuan Wu, Weiyi Meng, Clement Yu, Zhuogang Li - "Towards a HighlyScalable and Effective Metasearch Engine"
Swathi Chiteddi - "Meta Search Engine For NWRC"
Энциклопедия поисковых систем
Lycos
Примерно с мая 1994 года работает одна из старейших поисковых систем Lycos. Широко известная и часто используемая. В ее состав входит поисковая машина Point (работает с 1995 года) и каталог A2Z (работает с февраля 1996 года).
"META-миф".
META-таги могут помочь контролировать действия поисковых роботов и машин, однако некоторые машины "умеют" работать со всеми тагами, некоторые - только с несколькими тагами, остальные и вовсе на воспринимают подобные вещи. Отсюда следует вывод, что использование META-тагов НЕ ГАРАНТИРУЕТ, что Ваши страницы окажутся первыми в списке ответов на пользовательский запрос к машине. Детали можно понять, прочитав статью "Несколько слов о роботах поисковых машин".
META-таги
META-таги имеют два возможных атрибута
- <META HTTP-EQUIV="имя" CONTENT="содержимое">
- <META NAME="имя" CONTENT="содержимое">
META-таги должны находиться в заголовке HTML-документа между <HEAD> и </HEAD> (особенно это важно для документов, использующих фреймы).
Атрибут HTTP-EQUIV
META-таги с атрибутом HTTP-EQUIV эквивалентны HTTP-заголовкам. Обычно они управляют действиями броузеров и могут быть использованы для совершенствования информации, выдаваемой обычными заголовками. Таги такой формы могут дать такой же эффект, что и HTTP-заголовки, и на некоторых серверах автоматически могут быть переведены в настоящие HTTP-заголовки. HTTP-заголовки описываются в RFC1945 (HTTP/1.0) и RFC2068 (HTTP/1.1).
HTTP-заголовки могут быть сгенерированы с помощью CGI-скриптов. Это позволяют сделать серверы Apache и CERN. В других серверах могут использоваться другие механизмы генерирования заголовков. Некоторые генерируемые сервером поля заголовков не могут быть подменены значениями из META-тагов (в частности Date), другие подменяются только при ненормальном статус-коде (<>200). Когда заголовок не понятен, то значение HTTP-заголовка превалирует над значением META-тагов.
Expires
Источники: HTTP/1.1 (RFC2068)
Дата устаревания. Управление кэшированием в HTTP/1.0. В Netscape Navigator это выглядит следующим образом: если указанная дата прошла, то очередной запрос этого документа вызывает повторный сетевой запрос, а не подгрузку документа из кэша. Дата со значением "0" интерпретируется как "сейчас". Такое значение заставляет броузер каждый раз при запросе проверять - изменялся ли этот документ. Это, кстати относится и к прокси-агентам. Поисковые роботы могут либо совсем не индексировать такой документ, либо постоянно "обнюхивать" его.
Дата должна быть задана в формате, описываемом в RFC850,
<META HTTP-EQUIV="expires" CONTENT="Wed, 26 Feb 1997 08:21:57 GMT">
что эквивалентно HTTP-заголовку
Expires: Wed, 26 Feb 1997 08:21:57 GMT
Pragma
Контроль кэширования для HTTP/1.0.
Значением должно
быть "no-cache". Очень полезный контейнер, я всегда использую его при выдаче результатов работы любого скрипта.
Content-Type
Источники: HTTP/1.0 (RFC1045)
Указание типа документа. Может быть расширено указанием
кодировки страницы (charset). Если же указывать charset в
содержании META-тага, то Netscape Navigator
выводит такую страницу уже в заданном charset.
Однако будьте аккуратны, если текст страницы
в кодировке Windows, а значение charset=KOI8-r,
то никакими силами пользователь не сможет поменять encoding,
чтобы увидеть нормальные слова!
<META HTTP-EQUIV="Content-type"
CONTENT="text/html; charset=ISO-2022-JP">
Content-language
Источники: HTTP/1.0
Указание языка документа. Может использоваться поисковыми
машинами при индексировании страниц. Комбинация поля Accept-Language
(посылаемого броузером) с содержимым Content-language
может быть условием выбора сервером того или
иного языка.
<META HTTP-EQUIV="Content-language"
CONTENT="en-GB">
что эквивалентно HTTP-заголовку
В недавно вышедшей спецификации HTML 4.0 появилась другая возможность явного указания языка - <html lang="en">
Content-language: en-GB
Язык описывается парой значений (язык-диалект). В
примере: Английский-Великобритания
Refresh
Источники: Netscape
Определение задержки в секундах, после которой броузер
автоматически обновляет документ. Дополнительная возможность -
автоматическая загрузка другого документа.
<META HTTP-EQUIV="Refresh"
Content="3, URL=http://www.name.com/page.html">
что эквивалентно HTTP-заголовку
Refresh: 3; URL=http://www.name.com/page.html
В Netscape Navigator это дает такой же эффект, что и
нажатие на кнопку Reload.
Window-target
Источники: Jahn
Rentmeister
Определяет окно текущей страницы; может быть использован
для прекращения появления новых окон броузера при применении фреймовых
структур. Действует для многих (но не для всех) броузеров.
<META HTTP-EQUIV="Window-target"
CONTENT="_top">
что эквивалентно HTTP-заголовку
Window-target: _top
Ext-cache
Источники: Netscape
Определяет имя альтернативного кэша для Netscape
Navigator
<META HTTP-EQUIV="Ext-cache"
CONTENT="name=/some/path/index.db; istructions=User Instructions">
PICS-Label
Platform-Independant Content
rating Scheme.Обычно используется для определения
рейтинга "взрослости" (adult)
содержания (sex,violence,
...):-)) однако это довольно гибкая схема
и может использоваться для других целей.
Cache-Control
Источники: HTTP/1.1
Определяет действия кэша
по отношению к данному документу. Возможные
значения:
Public -
документ кэшируется в доступных для всех кэшах
Private
- только в частном кэше
no-cache
- не может быть кэширован
no-store
- может быть кэширован, но не сохраняется
Vary
Источники: HTTP/1.1
Определяет доступные альтернативы для указанных в CONTENT полей HTTP-заголовка.
<META HTTP-EQUIV="Vary"
CONTENT="Content-language">
что эквивалентно HTTP-заголовку
Vary: Content-language
Lotus
Lotus-редакторы генерируют свои собственные поля
Bulletin-Date и Bulletin-Text атрибуты. Bulletin-Text содержит
описание документа
Не указанные (non-submitted) страницы
Если хотя бы одна страница сервера указана, то поисковые машины обязательно найдут следующие страницы по ссылкам из указанной. Однако на это требуется больше времени. Некоторые машины сразу индексируют весь сервер, но большинство все-таки, записав указанную страницу в индекс, оставляют индексирование сервера на будущее.
Необходимо наличие ссылок на внутренние страницы.
Опять прописная истина, но поисковые машины отыскивают страницы именно по гипертекстовым ссылкам. Вообще говоря, чем больше ссылок внутри дерева документов на сервере, тем больше вероятность того, что ни одна страница не будет забыта при индексировании. Верно и обратное: если есть ссылки на другие, внешние сервера, то есть вероятность, что поисковый робот уйдет по этим ссылкам, не до конца проиндексировав страницы.
Несколько слов о том, как работают роботы (spiders) поисковых машин.
Андрей Аликберов,
Введение
Эта статья вовсе не является попыткой объяснить, как работают поисковые машины вообще (это know-how их производителей). Однако, по моему мнению, она поможет понять как можно управлять поведением поисковых роботов (wanderers, spiders, robots - программы, с помощью которых та или иная поисковая система обшаривает сеть и индексирует встречающиеся документы) и как правильно построить структуру сервера и содержащихся на нем документов, чтобы Ваш сервер легко и хорошо индексировался.
Первой причиной того, что я решился написать эту статью, явился случай, когда я исследовал файл логов доступа к моему серверу и обнаружил там следующие две строки:
lycosidae.lycos.com - - [01/Mar/1997:21:27:32 -0500] "GET /robots.txt HTTP/1.0" 404 -
lycosidae.lycos.com - - [01/Mar/1997:21:27:39 -0500] "GET / HTTP/1.0" 200 3270
то есть Lycos обратился к моему серверу, на первый запрос получил, что файла /robots.txt нет, обнюхал первую страницу, и отвалил. Естественно, мне это не понравилось, и я начал выяснять что к чему.
Оказывается, все "умные" поисковые машины сначала обращаются к этому файлу, который должен присутствовать на каждом сервере. Этот файл описывает права доступа для поисковых роботов, причем существует возможность указать для различных роботов разные права. Для него существует стандарт под названием .
По мнению Луиса Монье (Louis Monier, Altavista), только 5% всех сайтов в настоящее время имеет не пустые файлы /robots.txt если вообще они (эти файлы) там существуют. Это подтверждается информацией, собранной при недавнем исследовании логов работы робота Lycos. Шарль Коллар (Charles P.Kollar, Lycos) пишет, что только 6% от всех запросов на предмет /robots.txt имеют код результата 200. Вот несколько причин, по которым это происходит: люди, которые устанавливают Веб-сервера, просто не знают ни об этом стандарте, ни о необходимости существования файла /robots.txt. не обязательно человек, инсталлировавший Веб-сервер, занимается его наполнением, а тот, кто является вебмастером, не имеет должного контакта с администратором самой "железяки". это число отражает число сайтов, которые действительно нуждаются в исключении лишних запросов роботов, поскольку не на всех серверах имеется такой существенный трафик, при котором посещение сервера поисковым роботом, становится заметным для простых пользователей.
Формат файла /robots.txt.
Файл /robots.txt предназначен для указания всем поисковым роботам
(spiders) индексировать информационные сервера так, как определено
в этом файле, т.е.
только те директории и файлы сервера, которые
НЕ описаны в /robots.txt. Это файл должен содержать 0 или более
записей, которые связаны с тем или иным роботом (что определяется
значением поля agent_id), и указывают для каждого робота или для
всех сразу что именно им НЕ НАДО индексировать. Тот, кто пишет
файл /robots.txt, должен указать подстроку Product Token поля
User-Agent, которую каждый робот выдает на HTTP-запрос индексируемого
сервера. Например, нынешний робот Lycos на такой запрос выдает
в качестве поля User-Agent:
Lycos_Spider_(Rex)/1.0 libwww/3.1
Если робот Lycos не нашел своего описания в /robots.txt - он поступает
так, как считает нужным. Как только робот Lycos "увидел"
в файле /robots.txt описание для себя - он поступает так, как
ему предписано.
При создании файла /robots.txt следует учитывать еще один фактор
- размер файла. Поскольку описывается каждый файл, который не
следует индексировать, да еще для многих типов роботов отдельно,
при большом количестве не подлежащих индексированию файлов размер
/robots.txt становится слишком большим. В этом случае следует
применять один или несколько следующих способов сокращения размера
/robots.txt:
указывать директорию, которую не следует индексировать, и,
соответственно, не подлежащие индексированию файлы располагать
именно в ней
создавать структуру сервера с учетом упрощения описания исключений
в /robots.txt
указывать один способ индексирования для всех agent_id
указывать маски для директорий и файлов
Записи (records) файла /robots.txt
Общее описание формата записи.
[ # comment string NL
]*
User-Agent: [ [ WS ]+
agent_id ]+ [ [ WS ]* # comment string ]? NL
[ # comment string NL
]*
Disallow: [ [ WS ]+ path_root
]* [ [ WS ]* # comment string ]? NL
[
# comment string NL
|
Disallow: [ [ WS ]+
path_root ]* [ [ WS ]* # comment string ]? NL
]*
[ NL ]+
Параметры
Описание параметров, применяемых в записях /robots.txt
[...]+ Квадратные скобки со следующим за ними знаком + означают,
что в качестве параметров должны быть указаны один или несколько
терминов.
Например, после "User-Agent:" через пробел могут быть
указаны один или несколько agent_id.
[...]* Квадратные скобки со следующим за ними знаком * означают,
что в качестве параметров могут быть указаны ноль или несколько
терминов.
Например, Вы можете писать или не писать комментарии.
[...]? Квадратные скобки со следующим за ними знаком ? означают,
что в качестве параметров могут быть указаны ноль или один термин.
Например, после "User-Agent: agent_id" может быть написан
комментарий.
..|..
означает или то, что до черты, или то, что после.
WS один из символов - пробел (011) или табуляция (040)
NL один из символов - конец строки (015) , возврат каретки (012)
или оба этих символа (Enter)
User-Agent: ключевое слово (заглавные и прописные буквы роли не
играют).
Параметрами являются agent_id поисковых роботов.
Disallow: ключевое слово (заглавные и прописные буквы роли не
играют).
Параметрами являются полные пути к неиндексируемым файлам или
директориям
# начало строки комментариев, comment string - собственно тело
комментария.
agent_id любое количество символов, не включающих WS и NL, которые
определяют agent_id различных поисковых роботов. Знак * определяет
всех роботов сразу.
path_root любое количество символов, не включающих WS и NL, которые
определяют файлы и директории, не подлежащие индексированию.
Расширенные комментарии формата.
Каждая запись начинается со строки User-Agent, в которой описывается
каким или какому поисковому роботу эта запись предназначается.
Следующая строка: Disallow. Здесь описываются не подлежащие индексации
пути и файлы. КАЖДАЯ запись ДОЛЖНА иметь как минимум эти две строки
(lines). Все остальные строки являются опциями. Запись может содержать
любое количество строк комментариев. Каждая строка комментария
должна начинаться с символа # . Строки комментариев могут быть
помещены в конец строк User-Agent и Disallow. Символ # в конце
этих строк иногда добавляется для того, чтобы указать поисковому
роботу, что длинная строка agent_id или path_root закончена. Если
в строке User-Agent указано несколько agent_id, то условие path_root
в строке Disallow будет выполнено для всех одинаково. Ограничений
на длину строк User-Agent и Disallow нет. Если поисковый робот
не обнаружил в файле /robots.txt своего agent_id, то он игнорирует
/robots.txt.
Если не учитывать специфику работы каждого поискового робота,
можно указать исключения для всех роботов сразу. Это достигается
заданием строки
User-Agent: *
Если поисковый робот обнаружит в файле /robots.txt несколько записей
с удовлетворяющим его значением agent_id, то робот волен выбирать
любую из них.
Каждый поисковый робот будет определять абсолютный URL для чтения
с сервера с использованием записей /robots.txt.
Заглавные и строчные
символы в path_root ИМЕЮТ значение.
Примеры.
Пример 1:
User-Agent: *
Disallow: /
User-Agent: Lycos
Disallow: /cgi-bin/ /tmp/
В примере 1 файл /robots. txt содержит две записи. Первая относится
ко всем поисковым роботам и запрещает индексировать все файлы.
Вторая относится к поисковому роботу Lycos и при индексировании
им сервера запрещает директории /cgi-bin/ и /tmp/, а остальные
- разрешает. Таким образом сервер будет проиндексирован только
системой Lycos.
Пример 2:
User-Agent: Copernicus
Fred
Disallow:
User-Agent: * Rex
Disallow: /t
В примере 2 файл /robots.txt содержит две записи. Первая разрешает
поисковым роботам Copernicus и Fred индексировать весь сервер.
Вторая - запрещает всем и осебенно роботу Rex индексировать такие
директории и файлы, как /tmp/, /tea-time/, /top-cat.txt, /traverse.this
и т.д. Это как раз случай задания маски для директорий и файлов.
Пример 3:
# This is for every spider!
User-Agent: *
# stay away from this
Disallow: /spiders/not/here/
#and everything in it
Disallow: # a little nothing
Disallow: #This could
be habit forming!
# Don't comments make
code much more readable!!!
В примере 3 - одна запись. Здесь всем роботам запрещается индексировать
директорию /spiders/not/here/, включая такие пути и файлы как
/spiders/not/here/really/, /spiders/not/here/yes/even/me.html.
Однако сюда не входят /spiders/not/ или /spiders/not/her (в директории
'/spiders/not/').
Некоторые проблемы, связанные с поисковыми роботами.
Незаконченность стандарта (Standart
for Robot Exclusion).
К сожалению, поскольку поисковые системы появились не так давно,
стандарт для роботов находится в стадии разработки, доработки,
ну и т.д. Это означает, что в будущем совсем необязательно поисковые
машины будут им руководствоваться.
Увеличение трафика.
Эта проблема не слишком актуальна для российского сектора Internet,
поскольку не так уж много в России серверов с таким серьезным
трафиком, что посещение их поисковым роботом будет мешать обычным
пользователям. Собственно, файл /robots.txt
для того и предназначен, чтобы ограничивать действия роботов.
Не все поисковые роботы используют /robots.txt.
На сегодняшний день этот файл обязательно запрашивается поисковыми
роботами только таких систем как Altavista,
Excite, Infoseek, Lycos, OpenText и WebCrawler.
Использование мета-тагов HTML.
Начальный проект, который был создан в результате соглашений между
программистами некоторого числа коммерческих индексирующих организаций
(Excite, Infoseek, Lycos, Opentext и WebCrawler) на недавнем
собрании Distributing Indexing Workshop (W3C) , ниже.
На этом собрании обсуждалось использование мета-тагов HTML для
управления поведением поисковых роботов, но окончательного соглашения
достигнуто не было.
Были определены следующие проблемы для обсуждения
в будущем:
Неопределенности в спецификации файла /robots.txt
Точное определение использования мета-тагов HTML, или дополнительные
поля в файле /robots.txt
Информация "Please visit"
Текущий контроль информации: интервал или максимум открытых
соединений с сервером, при которых можно начинать индексировать
сервер.
ROBOTS мета-таги
Этот таг предназначен для пользователей, которые не могут контролировать
файл /robots.txt на своих веб-сайтах. Таг позволяет задать поведение
поискового робота для каждой HTML-страницы, однако при этом нельзя
совсем избежать обращения робота к ней (как возможно указать в
файле /robots.txt).
<META NAME="ROBOTS" CONTENT="robot_terms">
robot_terms - это разделенный запятыми список следующих ключевых
слов (заглавные или строчные символы роли не играют): ALL, NONE,
INDEX, NOINDEX, FOLLOW, NOFOLLOW.
NONE - говорит всем роботам игнорировать эту страницу при индексации
(эквивалентно одновременному использованию ключевых слов NOINDEX,
NOFOLLOW).
ALL - разрешает индексировать эту страницу и все ссылки из нее
(эквивалентно одновременному использованию ключевых слов INDEX,
FOLLOW).
INDEX - разрешает индексировать эту страницу
NOINDEX - неразрешает индексировать эту страницу
FOLLOW - разрешает индексировать все ссылки из этой страницы
NOFOLLOW - неразрешает индексировать ссылки из этой страницы
Если этот мета-таг пропущен или не указаны robot_terms, то по
умолчанию поисковый робот поступает как если бы были указаны robot_terms=
INDEX, FOLLOW (т.е. ALL).
Если в CONTENT обнаружено
ключевое слово ALL, то робот
поступает соответственно, игнорируя возможно указанные другие
ключевые слова.. Если в CONTENT имеются
противоположные по смыслу ключевые слова, например, FOLLOW,
NOFOLLOW, то робот поступает по своему усмотрению (в этом
случае FOLLOW).
Если robot_terms содержит только NOINDEX,
то ссылки с этой страницы не индексируются. Если robot_terms содержит
только NOFOLLOW, то страница
индексируется, а ссылки, соответственно, игнорируются.
KEYWORDS мета-таг.
<META NAME="KEYWORDS"
CONTENT="phrases">
phrases - разделенный запятыми
список слов или словосочетаний (заглавные и строчные символы роли
не играют), которые помогают индексировать страницу (т.е.
отражают
содержание страницы). Грубо говоря, это те слова, в ответ на которые
поисковая система выдаст этот документ.
DESCRIPTION мета-таг.
<META NAME="DESCRIPTION"
CONTENT="text">
text - тот текст, который
будет выводиться в суммарном ответе на запрос пользователя к поисковой
системе. Сей текст не должен содержать тагов разметки и логичнее
всего вписать в него смысл данного документа на пару-тройку строк.
Предполагаемые варианты исключения повторных посещений с помощью
мета-тагов HTML
Некоторые коммерческие поисковые роботы уже используют мета-таги,
позволяющие осуществлять "связь" между роботом и вебмастером.
Altavista использует KEYWORDS
мета-таг, а Infoseek использует
KEYWORDS и
DESCRIPTION мета-таги.
Индексировать документ один раз или делать это регулярно?
Вебмастер может "сказать" поисковому роботу или файлу
bookmark пользователя, что
содержимое того или иного файла будет изменяться. В этом случае
робот не будет сохранять URL,
а броузер пользователя внесет или не внесет это файл в bookmark.
Пока эта информация описывается только в файле /robots.txt,
пользователь не будет знать о том, что эта страница будет изменяться.
Мета-таг DOCUMENT-STATE может
быть полезен для этого. По умолчанию, этот мета-таг принимается
с CONTENT=STATIC.
<META NAME="DOCUMENT-STATE"
CONTENT="STATIC">
<META NAME="DOCUMENT-STATE"
CONTENT="DYNAMIC">
Как исключить индексирование генерируемых страниц или дублирование
документов, если есть зеркала сервера?
Генерируемые страницы - страницы, порождаемые действием CGI-скриптов.
Их наверняка не следует индексировать, поскольку если попробовать
провалиться в них из поисковой системы, будет выдана ошибка. Что
касается зеркал, то негоже, когда выдаются две разные ссылки на
разные сервера, но с одним и тем же содержимым. Чтобы этого избежать,
следует использовать мета-таг URL
с указанием абсолютного URL
этого документа (в
случае зеркал - на соответствующую страницу главного сервера).
<META NAME="URL" CONTENT="absolute_url">
Источники
Charles P.Kollar, John R.R.Leavitt,
Michael Mauldin, Robot Exclusion Standard Revisited,
Martijn Koster, Standard for
robot exclusion,
Об авторе
Алексей Петрович Мощевикин - к.ф.-м.н., Петрозаводский государственный университет,
Объем документов, загруженных роботами поисковых систем с thermo.karelia.ru, Мбайт

Примечание. в скобках указано количество заходов роботом на сайт за месяц
Общие советы
На вашей странице должен быть текст. Поскольку поисковые машины индексируют именно текст (извините за прописные истины). Страница с недостаточным количеством текста имеет мало шансов попасть в список ответа на запрос пользователя.
Не забывайте, что текст на картинке не может быть распознан поисковой машиной, поэтому рекомендуется записывать в таг ALT не только название рисунка, но и важнейшие слова из него (если они есть). Часто встречающаяся ошибка - большой сложный рисунок, содержащий множество ключевых слов, выносится вебмастером в отдельный HTML-файл. Это понятно: не хочется перегружать файл с текстом такой громадиной. Однако в это отдельном файле есть только заголовок, собственно сам рисунок, и далеко не всегда - подпись к рисунку из пары-тройки слов. А представляете, если в ALT и META записаны все слова из рисунка!
Кстати говоря, существует такое понятие, как спамминг - к примеру: когда люди повторяют слова маленьким фонтом или цветом фона страницы, чтобы не было заметно через броузер. Этими хитростями действительно обманываются поисковые машины. Ожидается, что поисковые машины будут учитывать подобные вещи при индексации страниц.
OpenText
Система OpenText появилась чуть раньше 1995 года. С июня 1996 года стала партнерствовать с Yahoo. Постепенно теряет свои позиции и вскоре перестанет входить в число основных поисковых систем.
Основные поисковые машины
Какие из сотен поисковых машин действительно важны для вебмастера?
Ну, разумеется, широко известные и часто используемые.
Но при этом следует учесть ту аудиторию, на которую рассчитан Ваш сервер. Например, если Ваш сервер содержит узкоспециальную информацию о новейших методах доения коров, то вряд ли Вам стоит уповать на поисковые системы общего назначения. В этом случае я посоветовал бы обменяться ссылками с Вашими коллегами, которые занимаются сходными вопросами:-)
Итак, для начала определимся с терминологией.
Существует два вида информационных баз данных о веб-страницах: поисковые машины и каталоги.
Поисковые машины: (spiders, crawlers) постоянно исследуют Сеть с целью пополнения своих баз данных документов. Обычно это не требует никаких усилий со стороны человека. Примером может быть поисковая система Altavista.
Для поисковых систем довольно важна конструкция каждого документа. Большое значение имеют title, meta-таги и содержимое страницы.
Каталоги: в отличие от поисковых машин в каталог информация заносится по инициативе человека. Добавляемая страница должна быть жестко привязана к принятым в каталоге категориям. Примером каталога может служить Yahoo.
Конструкция страниц значения не имеет.
Далее речь пойдет в основном о поисковых машинах.
Особенности поисковых машин
Каждая поисковая машина обладает рядом особенностей. Эти особенности следует учитывать при изготовлении своих страниц. Ниже приведена сравнительная таблица основных поисковых машин. Прочерк означает неизвестные или неисследованные значения.
Перенаправление (redirect)
Некоторые сайты перенаправляют посетителей с одного сервера на другой, и этот параметр показывает какой URL будет связан с вашими документами. Это важно, поскольку, если поисковая машина не отрабатывает перенаправление, то могут возникнуть проблемы с несуществующими файлами.
Период обновления
Поскольку Веб изменяется непрерывно, поисковые машины индексируют все без учета даты. Однако в каждый момент времени ссылки, выдаваемые в ответ на запросы пользователей, могут быть однодневной давности, а могут быть и месячной давности, а то и больше.
Вот некоторые причины, по которым это происходит:
некоторые поисковые машины сразу индексируют страницу по запросу пользователя, а затем продолжают индексировать еще не проиндексированные страницы
другие чаще могут "ползать" по наиболее популярным страницам сети, чем по другим.
Поддержка фреймов
Если поисковый робот не умеет работать с фреймовыми структурами, то многие структуры с фреймами будут упущены при индексировании.
Поддержка ImageMap
Тут примерно та же проблема, что и с фреймовыми структурами серверов
Поддержка META-тагов
По идее, все поисковые машины должны учитывать метаданные при индексации страниц, однако на практике не все это делают. Как использовать метаданные можно прочитать в статьях и .
Подготовка сайта к индексации
Повышение релевантности (соответствия запросу) сайта и привлечение на него посетителей с поисковиков - штука крайне аморфная. То есть если в одной поисковой машине сайт выходит, скажем по запросу "Теплые булочки с маком" на пятом месте, а значит и в первом листе, то другой выкинет его эдак двадцать седьмым, и соответствено - "нереферероспособным".
Что тут поделать? Ну, во первых, не торопиться. Как правило, сразу после того как сайт протестили в нескольких броузерах и нашли вполне удобоваримым, его стараются как можно быстрее "залить" на сервер хостера. Поверьте, если уж у Вас HTML совместим с основными UA (user agents), он стоит того чтобы потратить на него еще одну бессонную ночь для повышения его "совместимости" с поисковыми машинами.
Итак, начнем:
Шаг первый - закройте броузер и HTML документы своего проекта. Сделайте себе кофе или чай (опционально) и отойдите от компьютера. Сядьте в удобное кресло (тем у кого нет кресла ремендую подоконник в офисе) и попытайтесь решить для кого вы собственно этот сайт сделали. В идеале определятся с целевой аудиторией надо до написания какого либо кода, но идеал на то и идеал...
Что нужно решать прежде всего - возраст, образование, пол, причина по которой Ваш сайт подходит этой группе людей.
Пример:
Сайт посвященный породе собак аргентинский мастиф
Возраст аудитории - определить невозможно, от ребенка который "хочет собаку" и уже умеет запускать Internet Explorer в интернет-кафе, до бизнесмена который решил обзавестись модным псом и выходит из офиса по выделенке.
Образование - то же что и возраст.
Пол - вот тут можно с уверенностью сказать что к догообразным породам склоняется в основном сильная часть человечества. Женщины же если и заводят таких собак, то в основном руководствуясь желанием обезопасить себя.
Причина соответствия - на сайте есть история породы, фотографии лучших представителей и адреса заводчиков в крупнейших городах России.
Кроме того, сайт подходит людям просто интересующимся собаками.
С другой стороны, профессиональные собачники как правило с интернетом не дружат и основной частью аудитории будут "ламеры". Ну вот, с основными моментами разобрались. Шаг второй - подходите к компьютеру и запускаете либо текстовый редактор с модной фичей под названием подсчет знаков и слов в тексте или Word, где эта функция точно есть. Теперь основные правила работы: Содержание элемента title, желательно, не должно превышать 60 знаков.
В значении атрибута description не желательно наличие более 200 знаков.
В значении атрибута keywords не должно быть более 1000 знаков.
В тексте странички знаков может быть сколько угодно, но некоторые поисковики, не работающие с description в качестве ее описания выведут первые 200 знаков текста. Первое и главное, что Вы должны составить - это title. Значение этого элемента имеет наибольший вес при определении релевантности и, соответственно, должно быть тщательно продуманно. В нашем примере подойдет такой вариант:
<title>Аргентинский мастиф Dogo Argentino описание породы заводчики</title>
Вкючены оба названия породы и основные темы сайта. Ограничение на 60 знаков необязательно, но желательно так как в большинстве браузеров выводятся только первые 60 знаков в заголовке окна. В поисковиках действует то же правило только заголовок выводится в виде ссылки. Вторая задача - составить keywords и description. Подбирать эти параметры отдельно друг от друга довольно затруднительно поскольку они неразрывно связанны между собой. Дело в том что те поисковики которые поддерживают description при определении релевантности расчитывают содержание ключевых слов, введенных в форму поиска пользователем, в процентном виде. То есть, и keywords и description должны быть оптимально подобранны друг другу. Особенно это относится к description. Проще всего обьяснить это на примере:
<meta name="description" content="На сайте Вы найдете интересные материалы про породу Аргентинский мастиф, фотографии чемпионов , адреса заводчиков в городах Росси и сможете пообщатся с другими поклонниками породы на форуме и в чате">
В данном примере описания содержится 199 знаков и по этому показателю он вполне отвечает нашим требованиям.
Но если рассмотреть его подробнее то можно найти много "грязи". Во первых, это лишние слова в начале - "На сайте Вы найдете" совсем не обязательно включать в описание, смысл от этого не пострадает. Упоминание чата и форума тоже не обязательно, если только эти сервисы не являются ключевыми на сайте. Поскольку в нашем случае это не так (как впрочем и в большинстве случаев, чаты и форумы как и гестбуки являются "навесками" к основному контенту), то эти упоминания тоже можно удалить. В результате остается "Интересные материалы про породу Аргентинский мастиф, фотографии чемпионов, адреса заводчиков в городах России" - 110 знаков. Зачем так сокращать текст? Вспомните про процентный подсчет, чем description короче, тем меньшее количество раз должно повторяться ключевое слово для набора необходимых процентов. Кстати эти проценты находятся в диапазоне от 5 до 10. Теперь разработка keywords:
<meta name="keywords" content="Аргентинский мастиф, Dogo Argentino, адреса заводчиков, фотографии, чемпион, надежный защитник.">
Зачем было добавлять "надежный защитник"? Помните про женщин которые заводят таких собак руководствуясь желанием обезопасить себя? Вот для них и добавили. Но если уж добавили то нужно отразить это и в description. Получается:
<meta name="description" content="Аргентинский мастиф (Dogo Argentino) - надежный защитник и телохранитель, фотографии чемпионов , адреса заводчиков в городах России">
Длинна описания 131 знак. Идем дальше, теперь нам надо, вооружившись калькулятором или специальной программой, расчитать процентное содержание ключевых слов в описании. В нашем случае получается:
| Слово | Встречается раз | в % | Результат |
| Аргентинский мастиф | 1 | 5% | OK |
| Dogo Argentino | 1 | 5% | OK |
| адреса заводчиков | 1 | 5% | OK |
| фотографии | 1 | 5% | OK |
| чемпион | 1 | 5% | OK |
| надежный защитник | 1 | 5% | OK |
Как уже указывалось выше, поисковики используют текст для определения релевантности, а некоторые из них выводят его в описании сайта. Каким образом составлять текст? Во-первых он должен быть осмысленным. Во-вторых, забудьте про методы маскировки типа "белым по белому". Текст должен быть правильно отформатирован с использованием H1, H2 и т.д. Поисковики индексируют слова с учетом этих параметров и <h1>Аргентинский Мастиф</h1> имеет большую релевантность чем <p style="font-size: 15pt">Аргентинский Мастиф</p>. Кстати некоторые особо умные юзеры знакомые с CSS используют эту возможность для написания практически всего текста странички внутри контейнеров Hx, с помошью CSS представляя их как нормальный текст. В общем то эти горе-дизайнеры скорее всего или тестируют свои сайты или в последних версиях MSIE или вообще этим не занимаются. Пользователь, зашедший на такую страничку с NN до версии 4.5 или в любом браузере с отключенной поддержкой CSS (в Opera 6, кстати, для этого достаточно нажать одну кнопку и даже в меню лезть не надо) увидит то, что можно охарактеризовать одним емким словом [...]. Чтобы этого не случилось, используйте элементы разметки по назначению. Итак, вернемся к составлению текста. Что-то в этом духе будет вполне приемлемо: <h2>Аргентинский Мастиф</h2> <p>Аргентинский Мастиф ( Dogo Argentino ) одна из наиболее активно развивающихся в нашей стране пород догообразных собак. Надежный защитник и телохранитель, он как никто другой подходит для нашей неспокойной жизни.<br> История Dogo Argentino началась в 20-х годах 20-го века. Аргентинский Мастиф, родиной которого, как можно угадать из названия стала Южная Америка, создавался как универсальная собака для охоты на крупную дичь. Аргентинский мастиф способен долго преследовать зверя и после этого к него остается еще достаточно сил чтобы вступить в схватку. <br> Фотографии чемпионов породы Вы можете посмотреть в нашей Галерее, адреса заводчиков найти в Адресной книге, а про историю породы узнать в Справочнике.
Мы верим, что Аргентинский Мастиф окажется тем другом которого вы искали всю свою жизнь. </p> Приведенный здесь фрагмент - только начало текста странички. Чтобы поисковый робот счел ее достойной индексирования, текст должен содержать не менее 200 слов. В приведенном фрагменте слов 119 но и по смысловому напонению он далеко не полон. Впрочем, только на элементах навигации и всяческих копирайтах 200 слов Вы, я уверен, наберете :-) Теперь давайте взглянем как будет выглядеть наша страничка при выводе ее по запросу пользователя.
|
Аргентинский мастиф ( Dogo Argentino ) - надежный защитник и телохранитель, фотографии чемпионов , адреса заводчиков в городах России 98% Date: 21 фев 2002, Size 15K, http://www.yoursite.com/index.html Аргентинский Мастиф Аргентинский Мастиф ( Dogo Argentino ) одна из наиболее активно развивающихся в нашей стране пород догообразных собак. Надежный защитник и телохранитель, он как никто другой подх Last Modified 21-фев-2002 -page size 15K - URL: http://www.yoursite.com/index.html |
Это единственный извесный мне сервис статистики где дают бесплатный невидимый счетчик и довольно приличный список отчетов. Шаг четвертый- последние уточнения. Некоторые моменты лучше уточнить до выкладывания сайта на хост. Во-первых, какой веб сервер использует хостинг-провайдер. Подавляющее большинство русских провайдеров использует Russian Apache, который автоматически перекодирует страничку в зависимости от броузера клиента. Таким образом, атрибут charset является лишним. Однако в последнее время многие предпочитают иностранные хостинги, которые при полной бесплатности не требуют размещения баннера или pop-up окна. Естественно, что у них стоит "просто" Apache который ничего перекодировать не будет. В таком случае лучшим вариантом будет выкладывание всех документов в кодировке KOI-8r, являющейся стандартом де-факто в кириллице. Еще один момент - реиндексация сайта. Срок в днях, через который поисковый робот должен заново проиндексировать сайт, указывается в META-теге: <meta name="revisit-after" content="ХХdays"> Шаг пятый- ускорение индексации сайта. Фактически, если Вы выложили сайт на хостинг, то ускорить его индексацию намного нельзя. Большинство роботов работают по принципу паука, то есть обнаруживают новые странички следуя по ссылкам. Если вы не зарегистрировали сайт в каталогах типа , и т.д. то единственный способ ускорить индексацию - упоминать URL Вашего сайта на форумах, досках объявлений. Если у Вас есть друзья, имеющие сайты в сети, то можете попросить их разместить ссылку на Ваш сайт. Боьшинство дизайнеров не любят каталоги за то, что они взамен регистрации требуют разместить на сайте их кнопку или счетчик. Естественно, что в большинстве случаев это портит дизайн. Единтвенный извесный мне российский сечбот, который принимает заявки на индексацию - Но при заполнении заявки Вам сообщается, что срок, в течении которого Ваш сайт будет проиндексирован, неизвестен :-)
Поиск в Интернете: использование имён
, Центр Информационных Технологий
Опубликовано в журнале #2 (2000)
Этой статьей мы продолжаем разговор о наиболее эффективных приемах поиска информации в сети Интернет, начатый в выпусках КомпьютерПресс N 7-9 за этот год. Сегодня усилиями разработчиков растет потенциал информационно-поисковых систем (ИПС). Среди прочего предоставляется и возможность искать по ключевым словам не только внутри документа, но и в пределах его сетевого адреса - URL, т.е. среди имен серверов, каталогов и конечных информационных файлов. Специфике, преимуществу и недостаткам такого поиска будет посвящена часть материала.
Кроме того, в поле URL, где используется латинский алфавит, нередко привносится лексика из языков, графика которых не совпадает с латинской. Это явление вполне характерно и для российского сектора Интернета и связано прежде всего с масштабным присутствием в Сети имен собственных, роль которых при решении поисковых задач крайне велика. Наша цель- попытаться осмыслить современную практику употребления имен в Интернете в широком поле видения проблемы- от стандартов транслитерации до стихийного сленга.
Поисковые роботы
За последние годы Всемирная паутина стала настолько популярной, что сейчас Интернет является одним из основных средств публикации информации. Когда размер Сети вырос из нескольких серверов и небольшого числа документов до огромных пределов, стало ясно, что ручная навигация по значительной части структуры гипертекстовых ссылок больше не представляется возможной, не говоря уже об эффективном методе исследования ресурсов.
Эта проблема побудила исследователей Интернет на проведение экспериментов с автоматизированной навигацией по Сети, названной "роботами". Веб-робот - это программа, которая перемещается по гипертекстовой структуре Сети, запрашивает документ и рекурсивно возвращает все документы, на которые данный документ ссылается. Эти программы также иногда называют "пауками", " странниками", или " червями" и эти названия, возможно, более привлекательны, однако, могут ввести в заблуждение, поскольку термин "паук" и "странник" cоздает ложное представление, что робот сам перемещается, а термин "червь" мог бы подразумевать, что робот еще и размножается подобно интернетовскому вирусу-червю. В действительности, роботы реализованы как простая программная система, которая запрашивает информацию из удаленных участков Интернет, используя стандартные cетевые протоколы.
3.1 Использование поисковых роботов
Роботы могут использоваться для выполнения множества полезных задач, таких как статистический анализ, обслуживание гипертекстов, исследования ресурсов или зазеркаливания страниц. Рассмотрим эти задачи подробнее.
3.1.1 Статистический Анализ
Первый робот был создан для того, чтобы обнаружить и посчитать количество веб-серверов в Сети. Другие статистические вычисления могут включать среднее число документов, приходящихся на один сервер в Сети, пропорции определенных типов файлов на сервере, средний размер страницы, степень связанности ссылок и т.д.
3.1.2 Обслуживание гипертекстов
Одной из главных трудностей в поддержании гипертекстовой структуры является то, что ссылки на другие страницы могут становиться " мертвыми ссылками" в случае, когда страница переносится на другой сервер или cовсем удаляется.
На сегодняшний день не существует общего механизма, который смог бы уведомить обслуживающий персонал сервера, на котором содержится документ с сылками на подобную страницу, о том, что она изменилась или вобще удалена. Некоторые серверы, например, CERN HTTPD, будут регистрировать неудачные запросы, вызванные мертвыми ссылками наряду с рекомендацией относительно страницы, где обнаружена мертвая cсылка, предусматривая что данная проблема будет решаться вручную. Это не очень практично, и в действительности авторы документов обнаруживают, что их документы содержат мертвые ссылки лишь тогда, когда их извещают непосредственно, или, что бывает очень редко, когда пользователь cам уведомляет их по электронной почте. Робот типа MOMSPIDER, который проверяет ссылки, может помочь автору документа в обнаружении подобных мертвых ссылок, и также может помогать в обслуживании гипертекстовой структуры. Также роботы могут помочь в поддержании содержания и самой структуры, проверяя соответствующий HTML-документ, его соответствие принятым правилам, регулярные модернизации, и т.д., но это обычно не используется. Возможно, данные функциональные возможности должны были бы быть встроены при написании окружающей среды HTML-документа, поскольку эти проверки могут повторяться в тех случаях, когда документ изменяется, и любые проблемы при этом могут быть решены немедленно.
3.1.3 Зазеркаливание
Зазеркаливание - популярный механизм поддержания FTP архивов. Зеркало рекурсивно копирует полное дерево каталогов по FTP, и затем регулярно перезапрашивает те документы, которые изменились. Это позволяет распределить загрузку между несколькими серверами, успешно справиться с отказами сервера и обеспечить более быстрый и более дешевый локальный доступ, так же как и автономный доступ к архивам. В Сети Интернет зазеркаливание может быть осуществлено с помощью робота, однако на время написания этой статьи никаких сложных средств для этого не существовало. Конечно, существует несколько роботов, которые восстанавливают поддерево страниц и сохраняют его на локальном сервере, но они не имеют средств для обновления именно тех страниц, которые изменились.
Вторая проблема - это уникальность страниц, которая состоит в том, что ссылки в скопированных страницах должны быть перезаписаны там, где они ссылаются на страницы, которые также были зазеркалены и могут нуждаться в обновлении. Они должны быть измененены на копии, а там, где относительные ссылки указывают на страницы, которые не были зазеркалены, они должны быть расширены до абсолютных ссылок. Потребность в механизмах зазеркаливания по причинам показателей производительности намного уменьшается применением сложных кэширующих серверов, которые предлагают выборочную модернизацию, что может гарантировать, что кэшированный документ не обновился, и в значительной степени самообслуживается. Однако, ожидается, что cредства зазеркаливания в будущем будут развиваться должным образом.
3.1.4 Исследование ресурсов
Возможно, наиболее захватывающее применение роботов - использование их при исследовании ресурсов. Там, где люди не могут справиться с огромным количеством информации, довольно возможность переложить всю работу на компьютер выглядит довольно привлекательно. Существует несколько роботов, которые собирают информацию в большей части Интернет и передают полученные результаты базе данных. Это означает, что пользователь, который ранее полагался исключительно на ручную навигацию в Сети, теперь может объединить поиск с просмотром страниц для нахождения нужной ему информации. Даже если база данных не содержит именно того, что ему нужно, велика вероятность того, что в результате этого поиска будет найдено немало ссылок на страницы, которые, в свою очередь, могут ссылаться на предмет его поиска. Второе преимущество состоит в том, что эти базы данных могут автоматически обновляться за определенный период времени так, чтобы мертвые ссылки в базе данных были обнаружены и удалены, в отличие от обслуживания документов вручную, когда проверка часто является спонтанной и не полной. Использование роботов для исследования ресурсов будет обсуждаться ниже.
3.1.5 Комбинированное использование
Простой робот может выполнять более чем одну из вышеупомянутых задач.
Например робот RBSE Spider выполняет статистический анализ запрошенных документов и обеспечивает ведение базы данных ресурсов. Однако, подобное комбинированное использование встречается, к сожалению, весьма редко.
3.2 Повышение затрат и потенциальные опасности при использовании поисковых роботов
Использование роботов может дорого обойтись, особенно в случае, когда они используются удаленно в Интернете. В этом разделе мы увидим, что роботы могут быть опасны, так как они предъявляют слишком высокие требования к Сети.
3.2.1 Сетевой ресурс и загрузка сервера
Роботы требуют значительной пропускной способности канала сервера. Во-первых роботы работают непрерывно в течение длительных периодов времени, часто даже в течение месяцев. Чтобы ускорить операции, многие роботы делают параллельные запросы страниц с сервера, ведущие в последствии к повышенному использованию пропускной способности канала сервера. Даже удаленные части Сети могут чувствовать сетевую нагрузку на ресурс, если робот делает большое количество запросов за короткий промежуток времени. Это может привести к временной нехватке пропускной способности сервера для других пользователей, особенно на серверах с низкой пропускной способностью, поскольку Интернет не имеет никаких cредств для балансирования нагрузки в зависимости от используемого протокола. Традиционно Интернет воспринимался как "свободный", поскольку индивидуальные пользователи не должны были платить за его использование. Однако теперь это поставлено под сомнение, так как особенно корпоративные пользователи платят за издержки, связанные с использованием Сети. Компания может чувствовать, что ее услуги (потенциальным) клиентам стоят оплаченных денег, а страницы, автоматически переданные роботам - нет. Помимо предъявления требований к Сети, робот также предъявляет дополнительные требования к самому серверу. В зависимости от частоты, с которой он запрашивает документы с сервера, это может привести к значительной загрузке всего сервера и снижению скорости доступа других пользователей, обращающихся к серверу.
К тому же, если главный компьютер используется также для других целей, это может быть вообще неприемлемо. В качестве эксперимента автор управлял моделированием 20 параллельных запросов от своего сервера, функционирующего как Plexus сервер на Sun 4/330. Несколько минут машину, замедленную использованием паука, вообще невозможно было использовать. Этот эффект можно почувствовать даже последовательно запрашивая страницы. Все это показывает, что нужно избегать ситуаций с одновременным запросом страниц. К сожалению, даже современные браузеры (например, Netscape) создают эту проблему, параллельно запрашивая изображения, находящиеся в документе. Сетевой протокол HTTP оказался неэффективным для подобных передач и как средство борьбы с подобными эффектами сейчас разрабатываются новые протоколы.
3.2.2 Обновление документов
Как уже было упомянуто, базы данных, создаваемые роботами, могут автоматически обновляться. К сожалению, до сих пор не имеется никаких эффективных механизмов контроля за изменениями, происходящими в Сети. Более того, нет даже простого запроса, который мог бы определить, которая из cсылок была удалена, перемещена или изменена. Протокол HTTP обеспечивает механизм "If-Modified-Since", посредством которого агент пользователя может определить время модификации кэшированного документа одновременно с запросом самого документа. Если документ был изменен, тогда сервер передаст только его содержимое, так как этот документ уже был прокэширован. Это средство может использоваться роботом только в том случае, если он сохраняет отношения между итоговыми данными, которые извлекаются из документа: это сама ссылка и отметка о времени, когда документ запрашивался. Это ведет к возникновению дополнительных требований к размеру и сложности базы данных и широко не применяется.
3.3 Роботы / агенты клиента
Загрузка Сети является особой проблемой, связанной с применением категории роботов, которые используются конечными пользователями и реализованы как часть веб-клиента общего назначения (например, Fish Search и tkWWW робот).
Одной из особенностей, которая является обычной для этих роботов, является способность передавать обнаруженную информацию поисковым системам при перемещении по Сети. Это преподносится как усовершенствование методов исследования ресурсов, так как запросы к нескольким удаленным базам данных осуществляются автоматически. Однако, по мнению автора, это неприемлемо по двум причинам. Во-первых, операция поиска приводит к большей загрузке сервера, чем даже простой запрос документа, поэтому обычному пользователю могут быть причинены значительные неудобства при работе на нескольких серверах с большими издержками, чем обычно. Во-вторых, ошибочно предполагать, что одни и те же ключевые слова при поиске одинаково релевантны, синтаксически правильны, не говоря уже об оптимальности для различных баз данных, и диапазон баз данных полностью скрыт от пользователя. Например, запрос " Форд и гараж " мог бы быть послан базе данных, хранящей литературу 17-ого столетия, базе данных, которая не поддерживает булевские операторы или базе данных, которая определяет, что запросы относительно автомобилей должны начаться со слова "автомобиль: ". И пользователь даже не знает это. Другой опасный аспект использования клиентского робота заключается в том, что как только он был распространен по Сети, никакие ошибки уже не могут быть исправлены, не могут быть добавлены никакие знания проблемных областей и никакие новые эффективные свойства не могут его улучшить, как не каждый пользователь впоследствии будет модернизировать этого робота самой последней версией. Наиболее опасный аспект, однако - большое количество возможных пользователей роботов. Некоторые люди, вероятно, будут использовать такое устройство здраво, то есть ограничиваться некоторым максимумом ссылок в известной области Сети и в течение короткого периода времени, но найдутся и люди, которые злоупотребят им из-за невежества или высокомерия. По мнению автора, удаленные роботы не должны передаваться конечным пользователям, и к счастью, до сих пор удавалось убедить по крайней мере некоторых авторов роботов не распространять их открыто. Даже не учитывая потенциальную опасность клиентских роботов, возникает этический вопрос: где использование роботов может быть полезно всему Интернет-сообществу для объединения всех доступных данных, а где они не могут быть применены, поскольку принесут пользу только одному пользователю. "Интеллектуальные агенты" и " цифровые помощники", предназначенные для использования конечным пользователем, который ищет информацию в Интернет, являются в настоящее время популярной темой исследований в компьютерной науке, и часто рассматриваются как будущее Сети.
В то же время это действительно может иметь место, и уже очевидно, что автоматизация неоценима для исследований ресурсов, хотя требуется проводить еще больше исследований для того, чтобы их сделать их использование эффективным. Простые управляемые пользователем роботы очень далеки от интеллектуальных сетевых агентов: агент должен иметь некоторое представление о том, где найти определенную информацию (то есть какие услуги использовать) вместо того, чтобы искать ее вслепую. Рассмотрим ситуацию, когда человек ищет книжный магазин; он использует "Желтые страницы" для области, в которой он проживает, находит список магазинов, выбирает из них один или несколько, и посещает их. Клиентский робот шел бы во все магазины в области, спрашивая о книгах. В Сети, как и в реальной жизни, это неэффективно в малом масштабе, и совсем должно быть запрещено в больших масштабах.
3.3.1 Плохие программные реализации роботов
Нагрузка на сеть и серверы иногда увеличивается плохой программной реализацией особенно недавно написанных роботов. Даже если протокол и ссылки, посланные роботом, правильны, и робот правильно обрабатывает возвращенный протокол (включая другие особенности вроде переназначения), имеется несколько менее очевидных проблем. Автор наблюдал, как несколько похожих роботов управляют вызовом его сервера. В то время, как в некоторых случаях негативные последствия были вызваны людьми, использующими свой сайт для испытаний (вместо локального сервера), в остальных случаях стало очевидно, что они были вызваны плохим написанием самого робота. При этом могут произойти повторные запросы страниц в том случае, если нет никаких записей об уже запрошенных ссылках (что является непростительным), или когда робот не распознает, когда несколько ссылок синтаксически эквивалентны, например, где различаются DNS псевдонимы для одного и того же адреса IP, или где ссылки не могут быть обработаны роботом, например " foo/bar/ ../baz.html " является эквивалентным "foo/baz.html". Некоторые роботы иногда запрашивают документы типа GIF и PS, которые они не могут обработать и поэтому игнорируют. Другая опасность состоит в том, что некоторые области Сети являются почти бесконечными.Например, рассмотрим сценарий, который возвращает страницу со ссылкой на один уровень, расположенный ниже. Он начнет, например, с " /cgi-bin/pit / ", и продолжит с " /cgi-bin/pit/a / ", " /cgi-bin/pit/a/a / ", и т.д. Поскольку такие cсылки могут заманить в робота в ловушку, их часто называют "черными дырами".
Поисковые системы
Учебник предоставлен сайтом
Алан Кнехт (Alan K'necht), Digital Web
Перевод: Максим Россомахин, сайт www.webmascon.com
Ирина Пономарева, Дмитрий Антонов. Источник:
Robin Nobles, перевод
Dave Davies, перевод - http://www.searchengines.com.ua/
Даррин Ворд, перевод - http://www.searchengines.com.ua/
Phil Craven, перевод
Дейл Гетч, Перевод -
Дэниэл Базак, Перевод -
Phil Craven, http://webworkshop.net/, перевод Webmasterpro.com.ua
Духанин Роман
Алексей Мощевикин
Sergey R. Lisin
Повышение релевантности (соответствия запросу) сайта и привлечение на него посетителей с поисковиков - штука крайне аморфная. То есть если в одной поисковой машине сайт выходит, скажем по запросу "Теплые булочки с маком" на пятом месте, а значит и в первом листе, то другой выкинет его эдак двадцать седьмым, и соответствено - "нереферероспособным".
Вячеслав Тихонов
Вячеслав Тихонов,
, #2 (2000)
Михаил Талантов, КомпьютерПресс N 9, 1999
Михаил Талантов, КомпьютерПресс N 7, 1999
Михаил Талантов, КомпьютерПресс N 7, 1999
Михаил Талантов, КомпьютерПресс N 5, 1999, с 114
Павел Храмцов, из учебных материалов конференции ,
Подборка статей и технической информации по работе и характеристикам поисковых машин
А.Аликберов, ЦИТ
Е. Колмановская, CompTek International
А. Аликберов,
А. Аликберов,
Перевод А. Аликберова,
Пауки сообщают о содержании найденного документа, индексируют его и извлекают итоговую информацию. Также они просматривают заголовки, некоторые ссылки и посылают проиндексированную информацию базе данных поискового механизма. Кроулеры просматривают заголовки и возращают только первую ссылку. Роботы могут быть запрограммированы так, чтобы переходить по различным cсылкам различной глубины вложенности, выполнять индексацию и даже проверять ссылки в документе. Из-за их природы они могут застревать в циклах, поэтому, проходя по ссылкам, им нужны значительные ресурсы Сети. Однако, имеются методы, предназначенные для того, чтобы запретить роботам поиск по сайтам, владельцы которых не желают, чтобы они были проиндексированы.
Агенты извлекают и индексируют различные виды информации. Некоторые, например, индексируют каждое отдельное слово во встречающемся документе, в то время как другие индексируют только наиболее важных 100 слов в каждом, индексируют размер документа и число слов в нем, название, заголовки и подзаголовки и так далее. Вид построенного индекса определяет, какой поиск может быть сделан поисковым механизмом и как полученная информация будет интерпретирована. Агенты могут также перемещаться по Интернет и находить информацию, после чего помещать ее в базу данных поискового механизма. Администраторы поисковых систем могут определить, какие сайты или типы сайтов агенты должны посетить и проиндексировать. Проиндексированная информация отсылается базе данных поискового механизма так же, как было описано выше. Люди могут помещать информацию прямо в индекс, заполняя особую форму для того раздела, в который они хотели бы поместить свою информацию. Эти данные передаются базе данных. Когда кто-либо хочет найти информацию, доступную в Интернет, он посещает страницу поисковой системы и заполняет форму, детализирующую информацию, которая ему необходима. Здесь могут использоваться ключевые слова, даты и другие критерии. Критерии в форме поиска должны соответствовать критериям, используемым агентами при индексации информации, которую они нашли при перемещении по Сети. База данных отыскивает предмет запроса, основанный на информации, указанной в заполненной форме, и выводит соответствующие документы, подготовленные базой данных.
Чтобы определить порядок, в котором список документов будет показан, база данных применяет алгоритм ранжирования. В идеальном случае, документы, наиболее релевантные пользовательскому запросу будут помещены первыми в списке. Различные поисковые системы используют различные алгоритмы ранжирования, однако основные принципы определения релевантности следующие:
Количество слов запроса в текстовом содержимом документа (т.е. в html-коде). Тэги, в которых эти слова располагаются. Местоположение искомых слов в документе. Удельный вес слов, относительно которых определяется релевантность, в общем количестве слов документа. Эти принципы применяются всеми поисковыми системами. А представленные ниже используются некоторыми, но достаточно известными (вроде AltaVista, HotBot). Время - как долго страница находится в базе поискового сервера. Поначалу кажется, что это довольно бессмысленный принцип. Но, если задуматься, как много существует в Интернете сайтов, которые живут максимум месяц! Если же сайт существует довольно долго, это означает, что владелец весьма опытен в данной теме и пользователю больше подойдет сайт, который пару лет вещает миру о правилах поведения за столом, чем тот, который появился неделю назад с этой же темой. Индекс цитируемости - как много ссылок на данную страницу ведет с других страниц, зарегистрированных в базе поисковика.
База данных выводит ранжированный подобным образом список документов с HTML и возвращает его человеку, сделавшему запрос. Различные поисковые механизмы также выбирают различные способы показа полученного списка - некоторые показывают только ссылки; другие выводят cсылки c первыми несколькими предложениями, содержащимися в документе или заголовок документа вместе с ccылкой. Когда Вы щелкаете на ссылке к одному из документов, который вас интересует, этот документ запрашивается у того сервера, на котором он находится.
2.2 Сравнительный обзор поисковых систем
Lycos. В Lycos используется следующий механизм индексации:
слова в <title> заголовке имеют высший приоритет; слова в начале страницы; слова в ссылках; если в его базе индекса есть сайты, ссылка с которых указывает на индексируемый документ - релевантность этого документа возрастает.
Как и большинство систем, Lycos дает возможность применять простой запрос и более изощренный метод поиска.
В простом запросе в качестве поискового критерия вводится предложение на естественном языке, после чего Lycos производит нормализацию запроса, удаляя из него так называемые stop-слова, и только после этого приступает к его выполнению. Почти сразу выдается информация о количестве документов на каждое слово, а позже и список ссылок на формально релевантные документы. В списке против каждого документа указывается его мера близости запросу, количество слов из запроса, попавших в документ, и оценочная мера близости, которая может быть больше или меньше формально вычисленной. Пока нельзя вводить логические операторы в строке вместе с терминами, но использовать логику через систему меню Lycos позволяет. Такая возможность применяется для построения расширенной формы запроса, предназначенной для искушенных пользователей, уже научившихся работать с этим механизмом. Таким образом, видно, что Lycos относится к системе с языком запросов типа "Like this", но намечается его расширение и на другие способы организации поисковых предписаний.
AltaVista. Индексирование в этой системе осуществляется при помощи робота. При этом робот имеет следующие приоритеты:
слова содержащиеся в теге <title> имеют высший приоритет; ключевые фразы в <Meta> тэгах; ключевые фразы, находящиеся в начале странички; ключевые фразы в ALT - ссылках ключевые фразы по количеству вхождений\присутствия слов\фраз;
Если тэгов на странице нет, использует первые 30 слов, которые индексирует и показывает вместо описания (tag description) Наиболее интересная возможность AltaVista - это расширенный поиск. Здесь стоит сразу оговориться, что, в отличие от многих других систем AltaVista поддерживает одноместный оператор NOT. Кроме этого, имеется еще и оператор NEAR, который реализует возможность контекстного поиска, когда термины должны располагаться рядом в тексте документа. AltaVista разрешает поиск по ключевым фразам, при этом она имеет довольно большой фразеологический словарь. Кроме всего прочего, при поиске в AltaVista можно задать имя поля, где должно встретиться слово: гипертекстовая ссылка, applet, название образа, заголовок и ряд других полей.
К сожалению, подробно процедура ранжирования в документации по системе не описана, но видно, что ранжирование применяется как при простом поиске, так и при расширенном запросе. Реально эту систему можно отнести к системе с расширенным булевым поиском. Yahoo. Данная система появилась в Сети одной из первых, и сегодня Yahoo сотрудничает со многими производителями средств информационного поиска, а на различных ее серверах используется различное программное обеспечение. Язык Yahoo достаточно прост: все слова следует вводить через пробел, они соединяются связкой AND либо OR. При выдаче не указывается степень соответствия документа запросу, а только подчеркиваются слова из запроса, которые встретились в документе. При этом не производится нормализация лексики и не проводится анализ на "общие" слова. Хорошие результаты поиска получаются только тогда, когда пользователь знает, что в базе данных Yahoo информация есть наверняка. Ранжирование производится по числу терминов запроса в документе. Yahoo относится к классу простых традиционных систем с ограниченными возможностями поиска. OpenText. Информационная система OpenText представляет собой самый коммерциализированный информационный продукт в Сети. Все описания больше похожи на рекламу, чем на информативное руководство по работе. Система позволяет провести поиск с использованием логических коннекторов, однако размер запроса ограничен тремя терминами или фразами. В данном случае речь идет о расширенном поиске. При выдаче результатов сообщается степень соответствия документа запросу и размер документа. Система позволяет также улучшить результаты поиска в стиле традиционного булевого поиска. OpenText можно было бы отнести к разряду традиционных информационно-поисковых систем, если бы не механизм ранжирования. Infoseek. В этой системе индекс создает робот, но он индексирует не весь сайт, а только указанную страницу. При этом робот имеет такие приоритеты:
слова в заголовке <title> имеют наивысший приоритет; слова в теге keywords, description и частота вхождений\повторений в самом тексте; при повторении одинаковых слов рядом выбрасывает из индекса Допускает до 1024 символов для тега keywords, 200 символов для тэга description; Если тэги не использовались, индексирует первые 200 слов на странице и использует как описание;
Система Infoseek обладает довольно развитым информационно-поисковым языком, позволяющим не просто указывать, какие термины должны встречаться в документах, но и своеобразно взвешивать их.
Достигается это при помощи специальных знаков "+" - термин обязан быть в документе, и "-" - термин должен отсутствовать в документе. Кроме этого, Infoseek позволяет проводить то, что называется контекстным поиском. Это значит, что используя специальную форму запроса, можно потребовать последовательной совместной встречаемости слов. Также можно указать, что некоторые слова должны совместно встречаться не только в одном документе, а даже в отдельном параграфе или заголовке. Имеется возможность указания ключевых фраз, представляющих собой единое целое, вплоть до порядка слов. Ранжирование при выдаче осуществляется по числу терминов запроса в документе, по числу фраз запроса за вычетом общих слов. Все эти факторы используются как вложенные процедуры. Подводя краткое резюме, можно сказать, что Infoseek относится к традиционным системам с элементом взвешивания терминов при поиске. WAIS. WAIS является одной из наиболее изощренных поисковых систем Internet. В ней не реализованы лишь поиск по нечетким множествам и вероятностный поиск. В отличие от многих поисковых машин, система позволяет строить не только вложенные булевые запросы, считать формальную релевантность по различным мерам близости, взвешивать термины запроса и документа, но и осуществлять коррекцию запроса по релевантности. Система также позволяет использовать усечения терминов, разбиение документов на поля и ведение распределенных индексов. Не случайно именно эта система была выбрана в качестве основной поисковой машины для реализации энциклопедии "Британика" на Internet.
Повторное указание страниц.
Многие поисковые машины сейчас индексируют сайты в соответствии с их изменением. Это хорошо, если сайт редко изменяется, и реиндексация его один-два раза в год - нормально. Если же сайт изменяется часто, рекомендуется регулярно указывать страницы поисковым машинам, раз в один-два месяца. Это может гарантировать, что содержимое индекса в поисковых машинах не будет отличаться от реального содержания страниц.
Принцип перевернутой информационной пирамиды.
Газетчики очень хорошо знают как это делается. Грубо говоря, необходимо в начале документа выдавать его "изюминку". Это полезно как для людей, так и для поисковых машин. Однако то, что видно человеку в шапке документа, в исходнике не всегда находится в начале. К примеру, при табличной организации документа его релевантность некоторому запросу может оказаться ниже, чем при простой страничной организации того же самого документа. Вывод прост: включите аннотацию документа в начало документа и в META-таги (газетчики всегда пишут после заголовка статьи пару абзацев жирным шрифтом, после чего идет собственно статья) или упростите дизайн страницы (если это возможно).
Принципы работы метапоисковых систем
При проектировании метапоисковой системы нужно решить ряд проблем.
Прежде всего, из полученного от поисковых систем множества документов необходимо выделить наиболее релевантные, то есть соответствующие запросу пользователя. Как правило, создатели метапоисковых систем не совсем оправданно надеются, что поисковые системы, которые они используют, возвращают релевантные результаты поиска, и слишком полагаются на позицию, на которой в данной поисковой системе находится документ.
Этот стандартный подход представлен на рис. 1. В таких системах анализ полученных описаний документов не производится, что может поставить нерелевантные документы, идущие первыми в одной поисковой системе, выше релевантных в другой, чем существенно понизить качество самого поиска. Этот принцип оказался хорошим при создании автором , но в целом для систем метапоиска оказался неудовлетворительным.
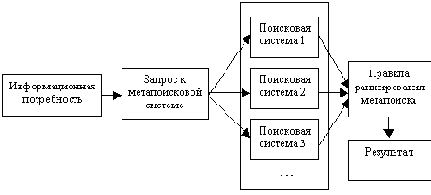
Рис.1 Стандартная метапоисковая система
При разработке следующего поколения метапоисковых систем были учтены недостатки, присущие стандартным метапоисковым системам. Были созданы системы с возможностью выбора тех поисковых машин, в которых, по мнению пользователя, он с большей вероятностью может найти то, что ему нужно (рис. 2)
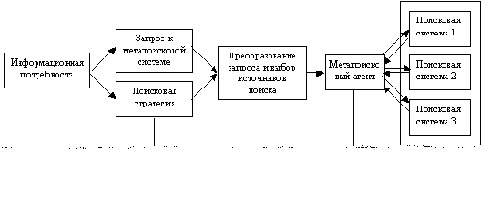
Рис. 2. Следующее поколение метапоисковых систем
Кроме этого, такой подход позволяет уменьшить используемые вычислительные ресурсы метапоискового сервера, не перегружая его слишком большим объемом ненужной информации и серьезно сэкономить трафик. Здесь нужно отметить, что в любой системе метапоиска наиболее узким местом в основном является пропускная способность канала передачи данных, так как обработка страниц с результатами поиска, полученными от нескольких десятков поисковых серверов не является слишком трудоемкой операцией, потому что затраты времени на обработку информации на порядки меньше времени прихода страниц, запрошенных у поисковых серверов.
Как пример систем, имеющих подобную организацию, можно назвать , , , .
Проблемы при каталогизации информации
Бесспорен тот факт, что базы данных, наполняемые роботами, популярны. Автор непосредственно регулярно использует такие базы данных для нахождения нужных ему ресурсов. Однако, имеется несколько проблем, которые ограничивают применение роботов для исследования ресурсов в Сети. Одна из них заключается в том, что здесь находится слишком много документов, и все они постоянно динамически изменяются.
Одной из мер эффективности подхода к поиску информации является "отзыв" (recall), содержащий информацию о всех релевантных документах, которые были найдены. Брайен Пинкертон утверждает, что отзыв в индексирующих системах Интернет является вполне приемлемым подходом, так как обнаружение достаточно релевантных документов не проблема. Однако, если сравнивать все множенство информации, доступной в Интернет, с информацией в базе данных, созданной роботом, то отзыв не может быть слишком точным, поскольку количество информации огромно и она очень часто изменяется. Так что практически база данных может не содержать специфического ресурса, который доступен в Интернет в данный момент, и таких документов будет множество, поскольку Сеть непрерывно растет.
4.1. Определение роботом, какую информацию включать / исключать
Робот не может автоматически определить, была ли данная страница в Сети включена в его индекс. К тому же веб-сервера в Интернет могут содержать документы, которые являются релевантными только для локального контекста, документы, которые существуют временно, и т.д. На практике роботы сохраняют почти всю информацию о том, где они побывали. Заметьте, что, даже если робот смог определить, должна ли указанная страница быть исключена из его базы данных, он уже понес накладные расходы на запрос самого файла, а робот, который решает игнорировать большой процент документов, очень расточителен. Пытаясь исправить эту ситуацию, Интернет-сообщество приняло " Стандарт исключений для роботов". Этот стандарт описывает использование простого структурированного текстового файла, доступного в известном месте на сервере ("/robots.txt") и используемого для того, чтобы определить, какая из частей их ссылок должна игнорироваться роботами.
Это средство может быть также использовано для того, чтобы предупредить роботов о черных дырах. Каждому типу роботов можно передавать определенные команды, если известно, что данный робот специализируется в конкретной области. Этот стандарт является свободным, но его очень просто осуществить и в нем имеется значительное давление на роботов с попыткой их подчинения.
4.2. Формат файла /robots.txt.
Файл /robots.txt предназначен для указания всем поисковым роботам индексировать информационные сервера так, как определено в этом файле, т.е. только те директории и файлы сервера, которые НЕ описаны в /robots.txt. Это файл должен содержать 0 или более записей, которые связаны с тем или иным роботом (что определяется значением поля agent_id), и указывают для каждого робота или для всех сразу что именно им НЕ НАДО индексировать. Тот, кто пишет файл /robots.txt, должен указать подстроку Product Token поля User-Agent, которую каждый робот выдает на HTTP-запрос индексируемого сервера. Например, нынешний робот Lycos на такой запрос выдает в качестве поля User-Agent:
Lycos_Spider_(Rex)/1.0 libwww/3.1
Если робот Lycos не нашел своего описания в /robots.txt - он поступает так, как считает нужным. При создании файла /robots.txt следует учитывать еще один фактор - размер файла. Поскольку описывается каждый файл, который не следует индексировать, да еще для многих типов роботов отдельно, при большом количестве не подлежащих индексированию файлов размер /robots.txt становится слишком большим. В этом случае следует применять один или несколько следующих способов сокращения размера /robots.txt:
указывать директорию, которую не следует индексировать, и, соответственно, не подлежащие индексированию файлы располагать именно в ней создавать структуру сервера с учетом упрощения описания исключений в /robots.txt указывать один способ индексирования для всех agent_id указывать маски для директорий и файлов
4.3. Записи (records) файла /robots.txt
Общее описание формата записи.
[ # comment string NL ]* User-Agent: [ [ WS ]+ agent_id ]+ [ [ WS ]* # comment string ]? NL [ # comment string NL ]* Disallow: [ [ WS ]+ path_root ]* [ [ WS ]* # comment string ]? NL [ # comment string NL | Disallow: [ [ WS ]+ path_root ]* [ [ WS ]* # comment string ]? NL ]* [ NL ]+
Параметры Описание параметров, применяемых в записях /robots.txt
[...]+ Квадратные скобки со следующим за ними знаком + означают, что в качестве параметров должны быть указаны один или несколько терминов.
Например, после "User-Agent:" через пробел могут быть указаны один или несколько agent_id. [...]* Квадратные скобки со следующим за ними знаком * означают, что в качестве параметров могут быть указаны ноль или несколько терминов. Например, Вы можете писать или не писать комментарии. [...]? Квадратные скобки со следующим за ними знаком ? означают, что в качестве параметров могут быть указаны ноль или один термин. Например, после "User-Agent: agent_id" может быть написан комментарий. ..|.. означает или то, что до черты, или то, что после. WS один из символов - пробел (011) или табуляция (040) NL один из символов - конец строки (015) , возврат каретки (012) или оба этих символа (Enter) User-Agent: ключевое слово (заглавные и прописные буквы роли не играют). Параметрами являются agent_id поисковых роботов. Disallow: ключевое слово (заглавные и прописные буквы роли не играют). Параметрами являются полные пути к неиндексируемым файлам или директориям. # начало строки комментариев, comment string - собственно тело комментария. agent_id любое количество символов, не включающих WS и NL, которые определяют agent_id различных поисковых роботов. Знак * определяет всех роботов сразу. path_root любое количество символов, не включающих WS и NL, которые определяют файлы и директории, не подлежащие индексации.
4.4. Расширенные комментарии формата.
Каждая запись начинается со строки User-Agent, в которой описывается каким или какому поисковому роботу эта запись предназначается. Следующая строка: Disallow. Здесь описываются не подлежащие индексации пути и файлы. КАЖДАЯ запись ДОЛЖНА иметь как минимум эти две строки (lines). Все остальные строки являются опциями. Запись может содержать любое количество строк комментариев. Каждая строка комментария должна начинаться с символа # . Строки комментариев могут быть помещены в конец строк User-Agent и Disallow. Символ # в конце этих строк иногда добавляется для того, чтобы указать поисковому роботу, что длинная строка agent_id или path_root закончена.
Если в строке User- Agent указано несколько agent_id, то условие path_root в строке Disallow будет выполнено для всех одинаково. Ограничений на длину строк User-Agent и Disallow нет. Если поисковый робот не обнаружил в файле /robots.txt своего agent_id, то он игнорирует /robots.txt. Если не учитывать специфику работы каждого поискового робота, можно указать исключения для всех роботов сразу. Это достигается заданием строки
User-Agent: *
Если поисковый робот обнаружит в файле /robots.txt несколько записей с удовлетворяющим его значением agent_id, то робот волен выбирать любую из них. Каждый поисковый робот будет определять абсолютный URL для чтения с сервера с использованием записей /robots.txt. Заглавные и строчные символы в path_root ИМЕЮТ значение. Пример 1:
User-Agent: * Disallow: / User-Agent: Lycos Disallow: /cgi-bin/ /tmp/
В примере 1 файл /robots.txt содержит две записи. Первая относится ко всем поисковым роботам и запрещает индексировать все файлы. Вторая относится к поисковому роботу Lycos и при индексировании им сервера запрещает директории /cgi-bin/ и /tmp/, а остальные - разрешает. Таким образом сервер будет проиндексирован только системой Lycos.
4.5. Определение порядка перемещения по Сети
Определение того, как перемещаться по Сети является относительной проблемой. Учитывая, что большинство серверов организовано иерархически, при первом перемещении вширь по ссылкам от вершины на ограниченной глубине вложенности ссылок, более вероятно быстрее найти набор документов с более высоким уровнем релевантности и услуг, чем при перемещении в глубину вложенности ссылок, и поэтому этот метод намного предпочтительнее для исследования ресурсов. Также при перемещении по ссылкам первого уровня вложенности более вероятно найти домашние страницы пользователей с ссылками к другим, потенциально новым, серверам, и поэтому при этом существует большая вероятность найти новые сайты.
4.6. Подведение итоговых данных
Проиндексировать произвольный документ, находящийся в Сети, очень сложно.
Первые роботы просто сохраняли название документа и якори (anchor) в самом тексте, но новейшие роботы уже используют более продвинутые механизмы и вообще рассматривают полное содержание документа. Эти методы являются хорошими общими мерами и могут автоматически применяться для всех страниц, но, к сожалению, не могут быть столь же эффективны, как индексация страницы самим ее автором. Язык HTML обеспечивает автора документа средством для того, чтобы присоединить к нему общую информацию. Это средство заключается в определении элемента <META>, например " <meta title = "keywords" value = " Обслуживание автомобиля Форда " >. Однако, здесь не определяется никакая семантика для специфических значений атрибутов данного HTML-тэга, что серьезно ограничивает его применение, а поэтому и его полноценность. Это ведет к низкой "точности" относительно общего количества запрошенных документов, которые являются релевантными для конкретного запроса. Включение особенностей типа применения булевских операторов, нахождение весов слов, как это делается в WAIS или обратной связи для релевантности, могут улучшить точность документов, но учитывая, что информация, находящаяся в данный момент в Интернет, чрезвычайно разнообразна, эта проблема продолжает быть серьезной и наиболее эффективные пути ее решения пока не найдены.
Проверка статуса URL
Очень полезная для вебмастера черта поисковой машины - можно ли проверить насколько глубоко проиндексирован его сервер и есть ли он вообще в индексе поисковой машины.
В одних поисковых машинах довольно просто проверить насколько глубоко проидексирован сервер, в других - сложнее. Ниже описаны возможные способы проверки для различных поисковых машин
Alta Vista
В этой поисковой машине проверку статуса URL осуществить довольно просто - достаточно набрать в строке запроса:
url: citforum.ru
url:citforum.ru/win/
url:citforum.ru/win/internet/index.shtml
В первом случае будут выданы все проиндексированные страницы сервера. Во втором - только страницы Windows-кодировки. В третьем - есть ли в индексе AltaVista файл index.shtml из указанной директории
Excite
Так же просто как и в AltaVista проверяется статус URL в поисковой машине Excite. Достаточно набрать URL. Например:
http://citforum.ru/win/database/articles/art_1.shtml
HotBot
Несколько по-другому проверяется статус URL в поисковой машине HotBot. Это делается так:
Infoseek
В поисковой машине Infoseek для проверки статуса URL существует отдельный интерфейс с целым набором настроек:
WebCrawler
WebCrawler предоставляет возможность проверить статус URL на странице:
Rambler
В этой поисковой машине статус URL можно проверить двумя способами.
В разделе путем указания имени сервера в качестве маски в одной из опций
Можно набрать $URL:www.citforum.ru в обычном поле запроса
Aport
Для проверки статуса URL в этой поисковой машине есть специальный запрос url=www.citforum.ru/*
Раскрутка сайта, поисковики и... mod_rewrite
Духанин Роман
Угу. Всем привет! Для кого предназначена эта статья - для веб разработчиков, для которых реально, что вся раскрутка сайта, которая ему (сайту) нужна, заключается в достижение высших позиций в наиболее популярных поисковых машинах по интересующим ключевым словам, ну и для остальных работников рекламы в интернете (для общего развития, так сказать :-)
ОК. Сразу к делу - как известно, не все еще люди научились пользоваться правильными поисковыми машинами типа Google или Yandex, многие (видать, по-старинке) продолжают использовать для поиска в Интернете поисковики НЕправильные. В чем различие между правильным и НЕправильным поисковиком? Навскидку, оных различий много, но одно из основных - это то, что НЕправильные поисковые машины НЕ индексируют сайты c динамическим содержимым . Мы здесь не будем показывать пальцем, но таких поисковиков достаточно много (например тот, который на "Ра" начинается и на "мблер" заканчивается).
И вот допустим, что вы решили создать и раскрутить сайт (реклама в интернете - великая вещь ;-) Да вот незадача - вы хотите иметь на оном сайте и гостевую книгу, и каталог товаров, и... И для этого сайт должен быть динамическим. И адреса у вас в оном каталоге будут типа ...?tovar=good&indexed=false - так что вышеупомянутый "мблер" оставит ваш сайт за бортом :-( Конечно, вы можете сказать - "Да мы раскрутим сайт и безо всякого там Рамблера! Да нам на Ра..." - расскажу вам историю двухнедельной давности:
Прихожу я в одну контору (мы вели переговоры отн. создания трех сайтов). Ну сидим мы общаемся. Вопрос заказчика: А вы сможете вывести нас в первую десятку сайтов, выдаваемых Рамблером по ключевому слову "......" Ну да, конечно, хотя я предпочитаю использовать Гугль, когда ищу по вашей тематике. ??? А что такое Гугль??? Вот так-то! А вы говорите Яндекс :)
Можно, конечно (ежели уж совсем серьезно подойти к рекламе в интернете - а как иначе? :) делать отдельный сайт для каждого отдельного поисковика (и в общем-то это правильно), но тогда вам понадобится создать и раскрутить не один, как минимум 3-5 сайтов, что весьма и весьма трудоемко.
В общем, я расскажу вам об основах того, как сделать, чтобы ваш динамический сайт индексировался Рамблером и другими подобными скриптоненавистническими поисковыми системами.
Данная технология используется на моем новом сайте (внимание, рекламная пауза ;-)
Во первых давайте посмотрим вот на что: каким именно образом робот понимает, что ваш сайт имеет динамическую структуру? Правильно - он смотрит параметр 'href' тэга 'A' и если в оном есть знаки ? или & и если робот НЕправильный, то страницу по данному адресу он индексировать не будет. Таким образом, задача заключается в том, чтобы убрать из строки урла вышеупомянутые символы. А как же тогда передавать параметры скрипту? Как...
Далее по пунктам (ежели что непонятно будет пишите лично - разберемся). Все повествование будет вестись на основе реальной разработки, и на выходе мы получим маленький жизнеспособный скрипт, поняв принципы работы которого, вы сможете написать большой и глючный интернет-магазин ;-)
Давайте сразу четко сформулируем задачу: нам нужно каким-то образом вызвать некий скрипт и передать ему некие параметры, при этом адресная строка должна выглядеть как для нормального, статического сайта. Это просто, если мы передаем скрипту данные из формы - ставим "POST" и все дела. Но мы то с вами должны передать параметры из гиперссылки, то есть через URL, то есть методом GET, то есть в УРЛе будут ? или &, то есть...
ОК. Есть такой файл, называется .htaccess - в нем вы можете задать некотрые директивы, управляющие сервером Apache (сложно писать для "широкой" аудитории - кто-то сейчас читает и думает про себя - чего он тут нам "азбуку жует", а кто-то прочитал предыдущую фразу, и материт меня за "тарабарщину всякую"). Ну и ладно. В общем знать об этом самом .htaccess нужно примерно следующее - разместив оный файл в какой-либо папке на сервере, и написав в нем всякие штуки, мы можем изменить поведение сервера, применительно к данной папке (если, конечно хост провайдер разрешает). Короче:
Помещаем файл с именем .htaccess в корневую папку свего сайта (DocumentRoot) - обычно она называется WWW или www
И пишем в него следующие строки:
RewriteEngine on
RewriteRule ^core.php$ - [L]
RewriteRule .* /core.php
О чем это я? Аааа... ну да - есть такой модуль Apache - mod_rewrite называется. Описание данного модуля, как это обычно говорится, выходит за рамки данной статьи - суть в том, что mod_rewrite делает с путями на сервере, что душе угодно и использует синтаксис регулярных выражений в стиле Perl - интересующиеся могут порыться в интернете в поисках документации к оному. И все же, что мы там понаписали в .htaccess
RewriteEngine on
# Данной директивой .htaccess мы включаем mod_rewrite
RewriteRule ^core.php$ - [L]
# Даем понять серверу, что если запрошен файл с именем core.php (название может быть произвольным) то с оным файлом нужно поступить так, как обычно сервер поступает с предателями... простите с файлами, имеющими расширение .php - передать на обработку дальше (модулю PHP).
RewriteRule .* /core.php
# Внимание! Здесь происходит то, ради чего мы и городим весь огород - теперь, что бы мы не написали в адресной строке - не имеет (пока не имеет) ни какого значения - в любом случае будет вызван скрипт с именем core.php Но! Но в адресной строке набранный адрес остается прежним, то есть переменная окружения REQUEST_URI если набрано, например www.somehost.org/123 будет равна именно этому самому 123 и... И мы можем запросто разобрать эту строку в core.php, таким образом, мы передаем данные прямо в имени файла!!!
Пишем тестовый скрипт и сохраняем как core.php :
function parse($uri){ if($uri){ // вырезаем цифровые значения из строковой переменной $uri в массив $uri_number eregi("[[:digit:]]+",$uri,$uri_number); //выводим первый элемент массива в браузер echo $uri_number[0]; } } // вызываем функцию с глобальной переменной $REQUEST_URI в качестве параметра parse($REQUEST_URI);
Теперь набираем в строке браузера что-нибудь типа http://имя_вашего_хоста/vasia12345.html Уррра!!! Получилось! (у меня все работает по крайней мере :-) Заметьте, что мы вызвали несуществующий файл vasia12345.html - сервер вернул нам OK (т.е.файл найден) - и вывел в браузер цифры 12345. Оные же цифры и буквы (для тех кто в танке ;-) можно передавать в качестве параметров в функции, внутри скрипта и пр.
Рамблер доволен, мы довольны, все довольны! :-))
В заключение, хочу отметить, что описанный метод, далеко не единственный - я знаю по меньшей мере еще три способа избавиться от прелестей метода GET. Но данный путь, на мой взгляд самый гибкий и удобный.
Всего!
Размер
Размер поисковой машины определяется количеством проиндексированных страниц. Приведенные в таблице значения не слишком точны, но могут прояснить некоторые моменты. Например, в поисковой машине с большим размером могут быть проиндексированы почти все ваши страницы, при среднем объеме ваш сервер может быть частично проиндексирован, а при малом объеме ваши страницы могут вообще не попасть в каталоги поисковой машины.
Российские поисковые машины
Небольшая преамбула к этому документу, касающаяся самой молодой и самой перспективной, на мой взгляд, поисковой машины Яndex.
Сейчас на первая страница работает в режиме обработки запроса на естественном языке. Такой возможности нет у других поисковых систем (это больше, чем просто поиск по всем словам, указанным в запросе, а поиск с "пониманием"). В этом режиме вообще нет языка запросов. При этом желающие указывать в запросе логические операторы, могут пользоваться расширенным поиском со страницы
На странице выдачи результатов добавлена возможность <Найти похожие документы>, чего опять же нет у других российских поисковых систем.
Со 2-го февраля 1998 года в поисковой системе Яndex появилась возможность осуществлять повторный поиск только в найденных документах (нужно в случае, если найденно слишком много документов для уточнения запроса). Это некоторый эквивалент опции Refine Альтависты.
| Полнотекстовая | Полнотекстовая | Полнотекстовая | Полнотекстовая | Полнотекстовая | |
| 500.000 | 140.094 | 2.500.000 | 2.000.000 | 2.600.000 | |
| 20 дней | 3-4 недели | 1 раз в неделю | перманентно | раз в сутки (от 10 до 40 тысяч документов) | |
| Нет, в проекте да | Да | Да, при расширенной выдаче результатов | Да | Да | |
| 20 дней | - | 7-14 дней | 1-2 дня | 1-15 дней | |
| 20 дней | - | до 3 месяцев | в зависимости от популярности документов | лимитируется скоростью обновления индекса | |
| 5.000 документов на глубину 150 | 20 документов | неограничена | неограничена | неограничена | |
| Да | Да | Да | Да | Да | |
| Да | Да | Да | Да | Да | |
| Возможно | Нет | Возможно | Возможно | Нет | |
| Нет (в проекте - да) | Нет | Нет | Да | Нет | |
| Да | robots.txt - да
META - нет |
Да | Да | Да | |
| Нет | Пока нет, в проекте - META-Keywords | Нет и не будет | Пока не поддерживаются | Пока не поддерживаются | |
| пока URL | title | title или URL и относительная мера релевантности | title и URL | title | |
| META-таг Description и часть текста документа | Первые строки документа | Первые 512 байт документа исключая meta, javascript, images... Существуют еще две формы вывода описания - короткая и длинная | Выдаются первые 1024 байт текста, мера релевантности, дата создания и объем документа | Предложения, содержащие слова запроса (1, 3 или до 10) | |
| Нет | Явно - нет, косвенно - указав в качестве критерия URL | Да (См. ) | Пока нет | Да (См. ) | |
| www.search.ru | - | StackRambler/1.2 | YandexWeb | Aport |
Составил , ЦИТ. Последние изменения 6 января 1998 года
Я благодарю за помощь (Plug Communication),
(Stack Ltd.),
(Dux),
(Agama), а также и (CompTek)
Spam-штрафы
Все крупные поисковые системы "не любят", когда какой-либо сайт пытается повысить свой рейтинг путем, например, многократного указания себя через Add URL или многократного упоминания одного и того же ключевого слова и т. д. В большинстве случаев подобные действия (spamming, stacking) караются, и рейтинг сайта наоборот падает.
Список использованной литературы
Павел Храмцов "Поиск и навигация в Internet".
How Intranet Search Tools and Spiders Work
Martijn Koster "Robots in the Web: threat or treat?"
Обучение Интернет-профессиям. Search engine Expert.
Андрей Аликберов "Несколько слов о том, как работают роботы поисковых машин".
"Способность к обучению"
Если сервер обновляется часто, то поисковая машина чаще будет его реиндексировать, если редко - реже.
Ссылки. Тексты ссылок
Далее, для того, чтобы конкретизировать тему каждой страницы, ссылки следует расположить таким образом, чтобы страницы одного тематического раздела были связаны между собой (страницы об ожерельях, соответственно, - со страницами об ожерельях и т.д.); важно также правильно использовать текст ссылки.
Google относит текст ссылки к той странице, на которую она ссылается. Таким образом, текст ссылки "браслеты ручной работы" рассматривается как часть страницы, на которую эта ссылка указывает. Если эта страница действительно посвящена браслетам ручной работы, то текст ссылки усиливает значимость темы.
Для того, чтобы проверить, насколько важен текст ссылки, был проведен следующий опыт. На многих страницах размещались ссылки на специально подготовленную страницу, причем текст ссылки был одинаковым. Содержание подготовленной страницы не имело ничего общего с текстом ссылки. Несмотря на это, страница имела PR1. Этот метод стал известен как "Google bombing".
Стандарт исключений для роботов Standard for robot exclusion
Martijn Koster , перевод А. Аликберова
Статус этого документа
Этот документ составлен 30 июля 1994 года по материалам обсуждений в телеконференции robots-request@nexor.co.uk (сейчас конференция перенесена на WebCrawler. Подробности см. Robots pages at WebCrawler ) между большинством производителей поисковых роботов и другими заинтересованными людьми.Также эта тема открыта для обсуждения в телеконференции Technical World Wide Web www-talk@info.cern.ch Сей документ основан на предыдущем рабочем проекте под таким же названием.
Этот документ не является официальным или чьим-либо корпоративным стандартом, и не гарантирует того, что все нынешние и будущие поисковые роботы будут использовать его. В соответствии с ним большинство производителей роботов предлагает возможность защитить Веб-серверы от нежелательного посещения их поисковыми роботами.
Последнюю версию этого документа можно найти по адресу
Введение
Поисковые роботы (wanderers, spiders) - это программы, которые индексируют веб-страницы в сети Internet.
В 1993 и 1994 годах выяснилось, что индексирование роботами серверов порой происходит против желания владельцев этих серверов. В частности, иногда работа роботов затрудняет работу с сервером обычных пользователей, иногда одни и те же файлы индексируются несколько раз. В других случаях роботы индексируют не то, что надо, например, очень "глубокие" виртуальные директории, временную информацию или CGI-скрипты. Этот стандарт призван решить подобные проблемы.
Назначение
Для того, чтобы исключить посещение сервера или его частей роботом необходимо создать на сервере файл, содержащий информацию для управления поведением поискового робота. Этот файл должен быть доступен по протоколу HTTP по локальному URL /robots.txt. Содержание этого файла см. ниже.
Такое решение было принято для того, чтобы поисковый робот мог найти правила, описывающие требуемые от него действия, всего лишь простым запросом одного файла. Кроме того файл /robots.txt легко создать на любом из существующих Веб-серверов.
Выбор именно такого URL мотивирован несколькими критериями:
Имя файла должно было быть одинаковым для любой операционной системы Расширение для этого файля не должно было требовать какой-либо переконфигурации сервера Имя файла должно было быть легко запоминающимся и отражать его назначение Вероятность совпадения с существующими файлами должна была быть минимальной Формат
Формат и семантика файла /robots.txt следующие:
Файл должен содержать одну или несколько записей (records), разделенных одной или несколькими пустыми строками (оканчивающимися CR, CR/NL или NL). Каждая запись должна содержать строки (lines) в форме:
"<field>:<optional_space><value><optional_space>".
Поле <field> является регистронезависимым.
Комментарии могут быть включены в файл в обычной для UNIX форме: символ # означает начало комментария, конец строки - конец комментария.
Запись должна начинаться с одной или нескольких строк User-Agent, следом должна быть одна или несколько строк Disallow, формат которых приведен ниже. Нераспознанные строки игнорируются.
User-Agent
значением <value> этого поля должно являться имя поискового робота, которому в этой записи устанавливаются права доступа. если в записи указано более одного имени робота, то права доступа распространяются для всех указанных имен. заглавные или строчные символы роли не играют если в качестве значения этого поля указан символ "*", то заданные в этой записи права доступа распространяются на любых поисковых роботов, запросивших файл /robots.txt Disallow
значением <value> этого поля должен являться частичный URL, который не должен индексироваться. Это может быть полный путь или частичный; любой URL, начинающийся с такого пути не должен индексироваться. Например, Disallow: /help закрывает и /help.html, и /help/index.html, тогда как
Disallow: /help/- только /help/index.html. если значение Disallow не указано, то это означает, что индексируется все дерево каталогов сервера Любая запись (record) должна состоять хотя бы из одной строки (line) User-Agent и одной - Disallow
Если файл /robots. txt пуст, или не отвечает заданному формату и семантике, или его не существует, любой поисковый робот будет работать по своему алгоритму.
Примеры
Пример 1:
# robots.txt for http://www.site.com User-Agent: * Disallow: /cyberworld/map/ # this is an infinite virtual URL space Disallow: /tmp/ # these will soon disappear В примере 1 закрывается от индексации содержимое директорий /cyberworld/map/ и /tmp/.
Пример 2:
# robots.txt for http://www.site.com User-Agent: * Disallow: /cyberworld/map/ # this is an infinite virtual URL space # Cybermapper knows where to go User-Agent: cybermapper Disallow: В примере 2 закрывается от индексации содержимое директории /cyberworld/map/, однако поисковому роботу cybermapper все разрешено.
Пример 3:
# robots.txt for http://www.site.com User-Agent: * Disallow: / В примере 3 любому поисковому роботу запрещается индексировать сервер.
Примечания переводчика
В настоящее время стандарт несколько изменился, например, можно записывать в строке User-Agent несколько имен роботов, разделенных пробелами или табуляторами.
Адреса авторов
Martijn Koster,
Перевод: Андрей Аликберов,
Стоп-слова
Некоторые поисковые машины не включают определенные слова в свои индексы или могут не включать эти слова в запросы пользователей. Такими словами обычно считаются предлоги или просто очень часто использующиеся слова. А не включают их ради экономии места на носителях.
Например, Altavista игнорирует слово web и для запросов типа web developer будут выданы ссылки только по второму слову. Существуют способы избежать подобного.
Таг LINK
Таг LINK предоставляет документу независимый от среды метод определения отношения данного документа к другим документам и ресурсам Сети. Используется с аргументами REL и REV. С помощью тага LINK можно: создавать в документе специальные навигационные кнопки или меню управлять процессом отображения набора HTML файлов в печатные документы привязывать такие ассоциированные ресурсы, как таблицы стилей и скрипты предоставлять альтернативные формы для данного документа
<LINK rel=help href="http://www.name.com/help.html">
где http://www.name.com/help.html - страница помощи по данному документу.
Атрибуты REL и REV могут также использоваться с тагом A. Таги LINK могут использоваться только в заголовке документа (head)
Атрибут REL
HTML 3.2 REL-таги
top, contents, index, glossary, copyright, next, previous, search
Некоторые из рекомендованных типов взаимосвязей:
rel=top
Данная связь указывает на вершину в некой иерархической структуре, например на
первую, либо титульную страницу в неком наборе документов.
rel=contents
Данная связь указывает на некий файл, где приводится оглавление к данному
документу.
rel=index
Данная связь указывает на другой документ, который можно использовать в целях
индексного поиска по текущему документу.
rel=glossary
Данная связь указывает на некий документ, где содержится глоссарий терминов,
относящихся к текущему документу.
rel=copyright
Данная связь ссылается на текст, где указаны авторские права на данный документ.
rel=next
Данная связь указывает на следующий документ в неком заранее предопределенном
маршруте просмотра. Например, она может использоваться для упреждающей автоматической
загрузки браузером следующей страницы.
rel=previous
Данная связь ссылается на предыдущий документ в неком предопределенном маршруте
просмотра.
rel=help
Данная связь указывает на документ, предлагающий некую помощь, например это может
быть текст, дающий более развернутое описание и предлагающий ссылки на другие
документы по этой теме. Назначение этой связи - оказание помощи тем читателям, кто
потерял свой путь в Web.
rel=search
Данная ссылка ведет к поисковой странице, контролирующей некий набор страниц,
связанных общей темой.
| Многие системы изобретают свои дополнительные значения аргументов REL и REV Таг Schema Этот таг содержит URL документа-шаблона. Действие всех метаданных из документа-шаблона будут распространены на документ с тагом Schema (так работает Dublin Core). <META NAME="VW96.objecttype" CONTENT="Dictionary"> <LINK REL=SCHEMA.VW96 HREF="http://vancouver-webpages.com/VWbot/VW96-schema.html"> ViewCall REL-таги home, bookmark, tickertape, vmail, icon, prefetch, keyn, fastxx AOLpress REL-таги AOLpress использует несколько дополнительных, по сравнению с HTML 3.2, тагов Home, ToC, Index, Glossary, Copyright, Up, Next, Previous, Help, Bookmark, First, Last |
Темы и рейтинг
Вот все, что можно сказать о темах. Но они - не единственный фактор в определении рейтинга. Определяющим фактором для последнего является индекс цитирования - число ссылающихся сайтов на ваш сайт. Чтобы оценить роль PR в какой-либо тематике, посмотрите уровень конкуренции в индексе цитирования Google и примените его принципы ко всем ссылкам сайта, включая ссылки внутри каждого раздела.
Тип поисковой машины
"Полнотекстовые" поисковые машины индексируют каждое слово на веб-странице, исключая лишь некоторые стоп-слова. "Абстрактные" поисковые машины создают некий экстракт каждой страницы.
Для вебмастеров полнотекстовые машины полезней, поскольку любое слово, встречающееся на веб-странице, подвергается анализу при определении его релевантности к запросам пользователей. Однако для абстрактных поисковых машин может случиться, что страницы проиндексированы лучше, чем для полнотекстовых. Это может исходить от алгоритма экстрагирования, например по частоте употребления в странице одних и тех же слов.
Title
Этот параметр показывает как поисковые машины генерируют заголовки ссылок для пользователя в ответ на его запрос.
Тщательно выбирайте ключевые слова.
Фокус двух или трех ключевых слов может оказаться более сильным аргументом в определении релевантности запросу, чем слова в заголовке или документе. Часто ключевые слова имеются в тексте, но не в заголовке документа.
Использование синонимов в ключевых словах не обязательно окажется решающим фактором при определении релевантности. Часто одно "экстра-слово" лучше помогает, чем подборка синонимов. Кстати, это не означает, что плохо записывать несколько таких "экстра-слов".
Удаление старых данных
Параметр, определяющий действия вебмастера при закрытии сервера или перемещении его на другой адрес. Возможны два действия: просто удалить старое содержание и переписать файл robots.txt.
удаление содержимого: когда поисковая машина попытается реиндексировать документы и не найдет их, старые ссылки в индексе будут удалены. В этом случае все зависит от периода обновления данных для поисковой машины.
robots.txt: когда поисковая машина запросит этот файл и "увидит", что сервер весь закрыт от индексации, то все ссылки на файлы этого сервера будут удалены из индекса.
Указанные (submitted) страницы
В идеале поисковые машины должны найти любые страницы любого сервера в результате прохода по ссылкам. Реальная картина выглядит по-другому. Станицы серверов гораздо раньше появляются в индексах поисковых систем, если их прямо указать (Add URL).
Указывайте ключевые страницы Вашего сервера.
Большинство поисковых машин индексируют страницы по гипертекстовым ссылкам из указанной (submitted) страницы. Иногда они, правда, ошибаются, поэтому полезно указывать первые три уровня дерева страниц сервера или те страницы, которые наилучшим образом отражают суть сервера.
В статье можно почерпнуть более подробные сведения об основных поисковых машинах.
Влияние на алгоритм определения релевантности
Поисковые машины обязательно используют расположение и частоту повторения ключевых слов в документе. Однако, дополнительные механизмы увеличения степени релевантности для каждой машины различны. Этот параметр показывает, какие именно механизмы существуют для той или иной машины.
Внутритекстовый и URL- поиск
Как известно, местоположение в Сети конечного документа (файла), однозначно задается его адресной схемой - URL. Если документ размещен не в корневом каталоге сервера, то в URL между именами узла и самого файла появляются еще и названия соответствующих каталогов. Так, для гипотетической Web-страницы rasskazy.html, находящей в подкаталоге Tolstoy каталога proza на сервере www.literature.ru,
URL выглядел бы следующим образом:
URL: http://www.literature.ru/proza/Tolstoy/rasskazy.html
Если поисковая система зарегистрировала указанный выше документ и поддерживает полноценный поиск по элементам адреса, то выйти на данную страницу можно по любому из встретившихся слов, т. е. literature, proza, Tolstoy, rasskazy и даже по их фрагментам.
В зависимости от конкретной ИПС поиск в пределах URL может задаваться различными способами - либо с помощью специальных меню и окон поискового шаблона, как, например, на Рамблере и Northern Light (см. рис. 1 ), либо в режиме командной строки, как на AltaVista (напр., url:literature), Yahoo (u:literature) или Яндексе (url="www.literature*"). Некоторые поисковые машины, в частности HotBot и Рамблер, поддерживают оба альтернативных варианта.
Рис.1. Элементы расширенной формы шаблона поисковых запросов на ИПС Northern Light (www.northernlight.com), поддерживающей поиск по URL (нижнее окно).
Рис.2. Элементы расширенного шаблона Рамблера (www.rambler.ru) со специальным окном для ввода терминов из URL (внизу), которые комбинируются в запросах с терминами из текстового поля.
Большинство систем допускает комбинирование URL- запроса с ключевыми словами, входящими в текст документа (рис. 2). В расширенном поиске AltaVista это может быть выполнено в виде: url:tolstoy AND "Охота пуще неволи" (вторым элементом запроса стоит фраза, являющаяся названием рассказа).
Для старейших в Сети ИПС, работающих с файловыми архивами FTP, поиск по ключевым словам, входящим в названия файлов и каталогов, всегда оставался основной функцией.
Фактически поиск проводился по элементам адреса, представление которого после становления Паутины стало регламентироваться стандартом адресных схем URL. При этом достигалась универсальность индексирования: независимо от внутреннего содержимого файла, его формата - ИПС благополучно регистрировала ресурс. Ясно, что элементы адреса, несущие основную смысловую нагрузку, в то время выбирались с гораздо большей аккуратностью, чем сегодня. Размещать в Сети для свободного доступа файлы данных или программы с такими именами как 1.txt или gr12.exe было признаком дурного тона по отношению к окружающим. Однако по мере накопления объема информации пришлось столкнуться с очевидной проблемой - выйти на релевантный запросу ресурс с помощью скудного набора ключевых слов, входящих в его адрес, становилось все сложнее. Тогда были найдены решения, позволяющие сопровождать отдельные файлы дополнительным текстовым комментарием, который также индексировался, что должно было повысить контрастность отдельного ресурса в ИПС. С приходом в Интернет Всемирной Паутины и ее основной информационной единицы - Web-страницы, для которой текстовая информация продолжает оставаться наиболее значимой, положение дел изменилось. В силу открытости формата Web-документа для свободного индексирования, началось бурное развитие поисковых машин WWW, делающих акцент теперь уже на внутритекстовом поиске. В то же самое время поиск по элементам URL многими поисковыми системами Паутины первоначально вообще не поддерживался. Тем не менее сегодня он присутствует на большинстве ИПС (см. КомпьютерПресс N 8) и заявлен в проекте стандарта SESP для поисковых систем 1999 года в качестве обязательного атрибута. На данный момент URL-поиск становится мощным, а в некоторых случаях и уникальным инструментом решения поисковых задач. Однако с его применением связан ряд особенностей. Здоровое желание автора-разработчика узла сократить до разумного минимума длину адресов, сохранив при этом их информативность, заставляет его использовать в качестве названий каталогов и файлов короткие, но ёмкие и адекватные ресурсам имена.
Вся файловая структура сервера обладает при этом большей стабильностью, чем содержимое отдельных документов, что в какой-то мере определяет область применимости и результативность URL-поиска. Попробуем задуматься над тем, что для нас предпочтительнее, найти в Сети Web-страницу с 20-кратным употреблением в ее тексте слова games (игры) или каталог с таким же именем. Если вас интересуют действующие версии игр, то, видимо, каталог имеет большие перспективы быть полезным. Аналогично и найденный файл unix.html имеет гораздо больше шансов оказаться учебником по операционной системе Unix, чем документ с произвольным названием, в теле которого, пусть даже многократно, встречается то же ключевое слово. Не секрет, что многие Web-мастера задают систему имен узла, делая ее полезной прежде всего для себя самих, а не для посетителей- отсюда в названиях непонятные цифры, сокращения и т.п. В этом отношении проблема разгадывания имен, предназначенных для "внутреннего пользования" нетривиальна и может показаться надуманной. Однако иногда начальных сведений о русурсе и данных о характере его традиционного представления в Сети бывает достаточно для эффективной работы с именами и в этом случае. Подбор возможных элементов адреса путем перебора допустимых терминов, их сокращений и вариантов написания может успешно конкурировать с другими приемами поиска. На практике широко применяется поиск ресурсов на основе самого стабильного элемента URL - доменного имени сервера.
Одним из основных способов найти
Одним из основных способов найти информацию в Internet являются поисковые машины. Поисковые машины каждый день "ползают" по Сети: они посещают веб-страницы и заносят их в гигантские базы данных. Это позволяет пользователю набрать некоторые ключевые слова, нажать "submit" и увидеть, какие страницы удовлетворяют его запросу.
Понимание того как работают поисковые машины просто необходимо вебмастерам. Для них жизненно важна правильная с точки зрения поисковых машин структура документов и всего сервера или сайта. Без этого документы будут недостаточно часто появляться в ответ на запросы пользователей к поисковой машине или даже вовсе могут быть не проиндексированы.
Вебмастера желают повысить рейтинг своих страниц и это понятно: ведь на любой запрос к поисковой машине могут быть выданы сотни и тысячи отвечающих ему ссылок на документы. В большинстве случаев только 10 первых ссылок обладают достаточной релевантностью к запросу.
Естественно, хочется, чтобы документ оказался в первой десятке, поскольку большинство пользователей редко просматривает следующие за первой десяткой ссылки. Иными словами, если ссылка на документ будет одиннадцатой, то это также плохо, как если бы ее не было вовсе.
В данной статье на примере
В данной статье на примере метапоисковой системы MetaPing рассматривается архитектура метапоисковых систем и основные принципы их работы и построения.
Основные протоколы, используемые в Интернет (в дальнейшем также Сеть), не обеспечены достаточными встроенными функциями поиска, не говоря уже о миллионах серверах, находящихся в ней. Протокол HTTP, используемый в Интернет, хорош лишь в отношении навигации, которая рассматривается только как средство просмотра страниц, но не их поиска. То же самое относится и к протоколу FTP, который даже более примитивен, чем HTTP. Из-за быстрого роста информации, доступной в Сети, навигационные методы просмотра быстро достигают предела их функциональных возможностей, не говоря уже о пределе их эффективности. Не указывая конкретных цифр, можно сказать, что нужную информацию уже не представляется возможным получить сразу, так как в Сети сейчас находятся миллиарды документов и все они в распоряжении пользователей Интернет, к тому же сегодня их количество возрастает согласно экспоненциальной зависимости. Количество изменений, которым эта информация подвергнута, огромно и, самое главное, они произошли за очень короткий период времени. Основная проблема заключается в том, что единой полной функциональной системы обновления и занесения подобного объема информации, одновременно доступного всем пользователям Интернет во всем мире, никогда не было. Для того, чтобы структурировать информацию, накопленную в сети Интернет, и обеспечить ее пользователей удобными средствами поиска необходимых им данных, были созданы поисковые системы.
WebCrawler
Открыта 20 апреля 1994 года как исследовательский проект Вашингтонского Университета. В марте 1995 года была приобретена компанией America Online
Существует каталог WebCrawler Select.
Yahoo
Старейший каталог Yahoo был запущен в начале 1994 года. Широко известен, часто используем и наиболее уважаем. В марте 1996 запущен еще один каталог Yahoo - Yahooligans для детей. Появляются все новые и новые региональные и top-каталоги Yahoo.
Поскольку Yahoo основан на подписке пользователей, в нем может не быть некоторых сайтов. Если поиск по Yahoo не дал подходящих результатов, пользователи могут воспользоваться поисковой машиной. Это делается очень просто. Когда делается запрос к Yahoo, каталог переправляет его к любой из основных поисковых машин. Первыми ссылками в списке удовлетворяющих запросу адресов идут адреса из каталога, а затем идут адреса, полученные от поисковых машин, в частности от Altavista.
Забудьте про спамминг.
С одной стороны спамминг - это не этично, с другой - никто кроме вебмастера не сможет точнее определить суть сделанных им документов. Альтернативные формы паблисити на сети описаны ниже.
Для того, чтобы правильно задать
Для того, чтобы правильно задать тему сайта, посвященного различным продуктам, необходимо разбить страницы сайта на разделы, посвященные определенным темам и правильно связать между собой страницы каждого из разделов. Страницы каждого раздела могут все находится в одной директории, но предпочтительней создать подразделы и назвать их в соответствии с продуктом, которому они посвящены. Свяжите главную страницу или карту сайта с одной из страниц каждого раздела. С этой страницы легко будет перейти на любую другую страницу раздела, так как они связаны между собой. Если рассматриваемое изделие имеет множество видов, то удобно создать для них дополнительные подразделы, используя указанную выше методику.
Данная статья, естественно, не претендует
Данная статья, естественно, не претендует на полноту изложения, в ней рассмотрены лишь основные принципы построения метапоисковых систем. Поэтому если после ее прочтения у Вас возникли какие-либо вопросы, Вы можете задать их по e-mail: .
Данная работа, естественно, не претендует ни на полноту, ни на точность изложения. Большая часть материала была взята из иностранных источников, в частности, основой послужили обзоры Мартина Костера (Martijn Koster). Поэтому я не исключаю возможности, что данный документ содержит какие-либо неточности, связанные как с переводом, так и с феноменально быстрым развитием информационных технологий. Однако, я все же надеюсь, что данная статья окажется полезной всем, кого интересует Всемирная Сеть Интернет, ее развитие и будущее. В любом случае я буду рад получить отклики о моей работе по E-Mail:
Зарубежные поисковые машины
| Полнотекстовая | Полнотекстовая | Полнотекстовая | Полнотекстовая | Абстрактная | Полнотекстовая | Полнотекстовая | |
| 30 миллионов | 55 миллионов | 54 миллиона | 20-50 миллионов | 20-25 миллионов | 5 миллионов | 2 миллиона | |
| от 1 дня до 3 месяцев | 1 - 3 недели | не позднее 3 недель | от минут до месяца | ещемесячное обновление | 1 - 4 недели | еженедельное обновление | |
| Да | Нет | Да | Нет | Нет | Нет | Нет | |
| 1 день | 1 неделя | 3 недели | 1 месяц | 1 месяц | 2 - 4 недели | 2 - 4 недели | |
| 1 - 3 месяца | 3 недели | 3 недели | 1 месяц | 1 месяц | 2 4 недели | 2 4 недели | |
| Неограничена | Неограничена | Неограничена | Неограничена | Неограничена | - | Ограничена популярностью того или иного сервера | |
| Нет | Да | Нет | Да | Да | Нет | Нет | |
| Да | Нет | Нет | Да | Да | Нет | Да | |
| Нет | Да | Нет | Да | Да | Нет | Нет | |
| Нет | Нет | Да | Нет | Да | Нет | Да | |
| Да | Нет | Да | Да | Нет | Нет | Нет | |
| robots.txt | robots.txt (в будущем и метаданные) | И то, и другое | robots.txt | robots.txt | robots.txt | И то, и другое | |
| Поддерживает | Поддерживает | - | - | - | - | Поддерживает | |
| Да | Да | Да | Нет | Да | Нет | Нет | |
| Нет | - | Ключевые слова в метаданных | Нет | Нет | Нет | Частота появления ссылок | |
| Да | Да | Да | Да | Да | Да | Да | |
| Да | Нет | Да | Да | Да | Нет | Только NOINDEX таг | |
| Заголовок страницы или No Title | Заголовок страницы или Untitled | Заголовок страницы или URL | Заголовок страницы или первая строка документа | Заголовок страницы или первая строка документа | Первые 100 символов из документа | Заголовок страницы или URL | |
| Метатаг или первые несколько строк из документа | Формируется из наиболее релевантных к запросу фраз документа | Метатаг или первые несколько строк документа | Метатаг или первые 200 символов после тага <body> | Метатаг или экстакт из содержимого страницы | Первые 100 символов документа | Создается из содержания; обещается поддержка метатагов в будущем | |
| Да | Нет | Нет | Нет | Да | Нет | Да | |
| Удалить содержимое и указать новый адрес | Удалить содержимое или переписать robots.txt | Переписать robots.txt | Удалить содержимое и указать новый адрес или переписать robots.txt | - | - | - | |
| Scooter | Architext Spider | Slurp the Web Hound | Side winder | T-rex | - | Spidey |
Информация приведена по состоянию на начало 1998 года.
Защищенные паролями директории и сервера
Некоторые поисковые машины могут индексировать такие сервера, если им указать Username и Password. Зачем это нужно? Чтобы пользователи видели, что есть на Вашем сервере. Это позволяет как минимум узнать, что такая информация есть, и, быть может, они тогда подпишутся на Вашу информацию.
