Быстрая сортировка
Хотя идея Шелла значительно улучшает сортировку вставками, резервы еще остаются. Один из наиболее известных алгоритмов сортировки – быстрая сортировка, предложенная Ч.Хоором. Метод и в самом деле очень быстр, недаром по-английски его так и величают QuickSort к неудовольствию всех спелл-чекеров (“…Шишков прости: не знаю, как перевести”).
Этому методу требуется O(n lg n) в среднем и O(n2) в худшем случае. К счастью, если принять адекватные предосторожности, наихудший случай крайне маловероятен. Быстрый поиск не является устойчивым. Кроме того, ему требуется стек, т.е. он не является и методом сортировки на месте. Дальнейшую информацию можно получить в работе Кормена [2].
Теория
Алгоритм разбивает сортируемый массив на разделы, затем рекурсивно сортирует каждый раздел. В функции Partition (Рис. 2.3) один из элементов массива выбирается в качестве центрального. Ключи, меньшие центрального следует расположить слева от него, те, которые больше, – справа.
|
int function Partition (Array A, int Lb, int Ub); begin select a pivot from A[Lb]…A[Ub]; reorder A[Lb]…A[Ub] such that: all values to the left of the pivot are £ pivot all values to the right of the pivot are ³ pivot return pivot position; end;
procedure QuickSort (Array A, int Lb, int Ub); begin if Lb < Ub then M = Partition (A, Lb, Ub); QuickSort (A, Lb, M – 1); QuickSort (A, M + 1, Ub); end; |
Рис. 2.3: Быстрый поиск
На рис. 2.4(a) в качестве центрального выбран элемент 3. Индексы начинают изменяться с концов массива. Индекс i начинается слева и используется для выбора элементов, которые больше центрального, индекс j начинается справа и используется для выбора элементов, которые меньше центрального. Эти элементы меняются местами – см. рис. 2.4(b). Процедура QuickSort рекурсивно сортирует два подмассива, в результате получается массив, представленный на рис. 2.4(c).

Рис. 2.4: Пример работы алгоритма Quicksort
В процессе сортировки может потребоваться передвинуть центральный элемент. Если нам повезет, выбранный элемент окажется медианой значений массива, т.е. разделит его пополам. Предположим на минутку, что это и в самом деле так. Поскольку на каждом шагу мы делим массив пополам, а функция Partition в конце концов просмотрит все n элементов, время работы алгоритма есть O(n lg n).
В качестве центрального функция Partition может попросту брать первый элемент (A[Lb]). Все остальные элементы массива мы сравниваем с центральным и передвигаем либо влево от него, либо вправо. Есть, однако, один случай, который безжалостно разрушает эту прекрасную простоту. Предположим, что наш массив с самого начала отсортирован. Функция Partition всегда будет получать в качестве центрального минимальный элемент и потому разделит массив наихудшим способом: в левом разделе окажется один элемент, соответственно, в правом останется Ub – Lb элементов. Таким образом, каждый рекурсивный вызов процедуры quicksort всего лишь уменьшит длину сортируемого массива на 1. В результате для выполнения сортировки понадобится n рекурсивных вызовов, что приводит к времени работы алгоритма порядка O(n2). Один из способов побороть эту проблему – случайно выбирать центральный элемент. Это сделает наихудший случай чрезвычайно маловероятным.
Реализация
Реализация алгоритма на Си находится в разделе 4.3. Операторы typedef T и compGT следует изменить так, чтобы они соответствовали данным, хранимым в массиве. По сравнению с основным алгоритмом имеются некоторые улучшения::
· В качестве центрального в функции partition выбирается элемент, расположенный в середине. Такой выбор улучшает оценку среднего времени работы, если массив упорядочен лишь частично. Наихудшая для этой реализации ситуация возникает в случае, когда каждый раз при работе partition.в качестве центрального выбирается максимальный или минимальный элемент.
· Для коротких массивов вызывается insertSort. Из-за рекурсии и других “ накладных расходов” быстрый поиск оказывается не столь уж быстрым для коротких массивов. Поэтому, если в массиве меньше 12 элементов, вызывается сортировка вставками. Пороговое значение не критично – оно сильно зависит от качества генерируемого кода.
· Если последний оператор функции является вызовом этой функции, говорят о хвостовой рекурсии. Ее имеет смысл заменять на итерации – в этом случае лучше используется стек. Это сделано при втором вызове QuickSort на рис. 2.3.
· После разбиения сначала сортируется меньший раздел. Это также приводит к лучшему использованию стека, поскольку короткие разделы сортируются быстрее и им нужен более короткий стек.
В разделе 4.4 вы найдете также qsort – функцию из стандартной библиотеки Си, которая, в соответствии названием, основана на алгоритме quicksort. Для этой реализации рекурсия была заменена на итерации. В таблице 2.1 приводится время и размер стека, затрачиваемые до и после описанных улучшений.
|
Time (ms) |
stacksize |
|||
|
count |
before |
after |
before |
after |
|
16 |
103 |
51 |
540 |
28 |
|
256 |
1,630 |
911 |
912 |
112 |
|
4,096 |
34,183 |
20,016 |
1,908 |
168 |
|
65,536 |
658,003 |
470,737 |
2,436 |
252 |
Хеш-таблицы
Для работы с словарем требуются поиск, вставка и удаление. Один из наиболее эффективных способов реализации словаря – хеш-таблицы. Среднее время поиска элемента в них есть O(1), время для наихудшего случая – O(n). Прекрасное изложение хеширования можно найти в работах Кормена[2] и Кнута[1]. Чтобы читать статьи на эту тему, вам понадобится владеть соответствующей терминологией. Здесь описан метод, известный как связывание или открытое хеширование[3]. Другой метод, известный как замкнутое хеширование[3] иëè заêðûòàÿ адресация[1], здесь не обсуждаются. Ну, как?
Теория
Хеш-таблица – это обычный массив с необычной адресацией, задаваемой хеш-функцией. Например, на hashTable рис. 3.1 – это массив из 8 элементов. Каждый элемент представляет собой указатель на линейный список, хранящий числа. Хеш-функция в этом примере просто делит ключ на 8 и использует остаток как индекс в таблице. Это дает нам числа от 0 до 7 Поскольку для адресации в hashTable нам и нужны числа от 0 до 7, алгоритм гарантирует допустимые значения индексов.
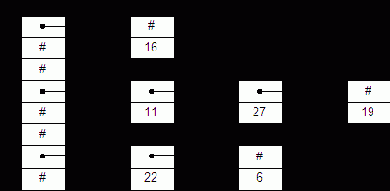
Рис. 3.1: Хеш-таблица
Чтобы вставить в таблицу новый элемент, мы хешируем ключ, чтобы определить список, в который его нужно добавить, затем вставляем элемент в начало этого списка. Например, чтобы добавить 11, мы делим 11 на 8 и получаем остаток 3. Таким образом, 11 следует разместить в списке, на начало которого указывает hashTable[3]. Чтобы найти число, мы его хешируем и проходим по соответствующему списку. Чтобы удалить число, мы находим его и удаляем элемент списка, его содержащий.
Если хеш-функция распределяет совокупность возможных ключей равномерно по множеству индексов, то хеширование эффективно разбивает множество ключей. Наихудший случай – когда все ключи хешируются в один индекс. При этом мы работаем с одним линейным списком, который и вынуждены последовательно сканировать каждый раз, когда что-нибудь делаем. Отсюда видно, как важна хорошая хеш-функция. Здесь мы рассмотрим лишь несколько из возможных подходов.
При иллюстрации методов предполагается, что unsigned char располагается в 8 бèòах, unsigned short int – в 16, unsigned long int – в 32.
· Деление (размер таблицы hashTableSize – простое число). Этот метод использован в последнем примере. Хеширующее значение hashValue, изменяющееся от 0 до (hashTableSize - 1), равно остатку от деления ключа на размер хеш-таблицы.
Вот как это может выглядеть:
typedef int hashIndexType;
hashIndexType hash(int Key) {
return Key % hashTableSize;
}
Для успеха этого метода очень важен выбор подходящего значения hashTableSize. Если, например, hashTableSize равняется двум, то для четных ключей хеш-значения будут четными, для нечетных – нечетными. Ясно, что это нежелательно – ведь если все ключи окажутся четными, они попадут в один элемент таблицы. Аналогично, если все ключи окажутся четными, то hashTableSize,
равное степени двух, попросту возьмет часть битов Key в качестве индекса. Чтобы получить более случайное распределение ключей, в качестве hashTableSize
нужно брать простое число, не слишком близкое к степени двух.
· Мультипликативный метод (размер таблицы hashTableSize есть степень 2n).
Значение Key умножается на константу, затем от результата берется необходимое число битов. В качестве такой константы Кнут[1] рекомендует золотое сечение

/* 8-bit index */
typedef unsigned char hashIndexType;
static const hashIndexType K = 158;
/* 16-bit index */
typedef unsigned short int hashIndexType;
static const hashIndexType K = 40503;
/* 32-bit index */
typedef unsigned long int hashIndexType;
static const hashIndexType K = 2654435769;
/* w=bitwidth(hashIndexType), size of table=2**m */
static const int S = w - m;
hashIndexType hashValue = (hashIndexType)(K * Key) >> S;
Пусть, например, размер таблицы hashTableSize равен 1024 (210). Тогда нам достаточен 16-битный индекс и S будет присвоено значение 16 – 10 = 6. В итоге получаем:
typedef unsigned short int hashIndexType;
hashIndexType hash(int Key) {
static const hashIndexType K = 40503;
static const int S = 6;
return (hashIndexType)(K * Key) >> S;
}
· Аддитивный метод для строк переменной длины (размер таблицы равен 256). Для строк переменной длины вполне разумные результаты дает сложение по модулю 256. В этом случае результат hashValue заключен между 0 и 244.
typedef unsigned char hashIndexType;
hashIndexType hash(char *str) {
hashIndexType h = 0;
while (*str) h += *str++;
return h;
}
· Исключающее ИЛИ для строк переменной длины (размер таблицы равен 256). Этот метод аналогичен аддитивному, но успешно различает схожие слова и анаграммы (аддитивный метод даст одно значение для XY и YX). Метод, как легко догадаться, заключается в том, что к элементам строки последовательно применяется операция “исключающее или”. В нижеследующем алгоритме добавляется случайная компонента, чтобы еще улучшить результат.
typedef unsigned char hashIndexType;
unsigned char Rand8[256];
hashIndexType hash(char *str) {
unsigned char h = 0;
while (*str) h = Rand8[h ^ *str++];
return h;
}
Здесь Rand8 – таблица из 256 восьмибитовых случайных чисел. Их точный порядок не критичен. Корни этого метода лежат в криптографии; он оказался вполне эффективным [4].
· Исключающее ИЛИ для строк переменной длины (размер таблицы £ 65536). Если мы хешируем строку дважды, мы получим хеш-значение для таблицы любой длины до 65536.
Когда строка хешируется во второй раз, к первому символу прибавляется 1. Получаемые два 8-битовых числа объединяются в одно 16-битовое.
typedef unsigned short int hashIndexType;
unsigned char Rand8[256];
hashIndexType hash(char *str) {
hashIndexType h;
unsigned char h1, h2;
if (*str == 0) return 0;
h1 = *str; h2 = *str + 1;
str++;
while (*str) {
h1 = Rand8[h1 ^ *str];
h2 = Rand8[h2 ^ *str];
str++;
}
/* h is in range 0..65535 */
h = ((hashIndexType)h1 << 8)|(hashIndexType)h2;
/* use division method to scale */
return h % hashTableSize
}
Размер хеш-таблицы должен быть достаточно велик, чтобы в ней оставалось разумное число пустых мест. Как видно из таблицы 3.1, чем меньше таблица, тем больше среднее время поиска ключа в ней. Хеш-таблицу можно рассматривать как совокупность связанных списков. По мере того, как таблица растет, увеличивается количество списков и, соответственно, среднее число узлов в каждом списке уменьшается. Пусть количество элементов равно n. Если размер таблицы равен 1, то таблица вырождается в один список длины n. Если размер таблицы равен 2 и хеширование идеально, то нам придется иметь дело с двумя списками по n/100 элементов в каждом. Как мы видим в таблице 3.1, имеется значительная свободы в выборе длины таблицы.
|
size |
time |
size |
time |
|
1 |
869 |
128 |
9 |
|
2 |
432 |
256 |
6 |
|
4 |
214 |
512 |
4 |
|
8 |
106 |
1024 |
4 |
|
16 |
54 |
2048 |
3 |
|
32 |
28 |
4096 |
3 |
|
64 |
15 |
8192 |
3 |
Сортируются 4096 элементов.
Реализация
Реализация алгоритма на Си находится в разделе 4.5. Операторы typedef T и compGT следует изменить так, чтобы они соответствовали данным, хранимым в массиве. Для работы программы следует также определить hashTableSize и отвести место под hashTable. В хеш-функции hash использован метод деления.Функция insertNode отводит память под новый узел и вставляет его в таблицу. Функция deleteNode удаляет узел и освобождает память, где он располагался. Функция findNode ищет в таблице заданный ключ.
Коды для бинарных деревьев
typedef int T; /* type of item to be sorted */
#define compLT(a,b) (a < b)
#define compEQ(a,b) (a == b)
typedef struct Node_ {
struct Node_ *left; /* left child */
struct Node_ *right; /* right child */
struct Node_ *parent; /* parent */
T data; /* data stored in node */
} Node;
Node *root = NULL; /* root of binary tree */
Node *insertNode(T data) {
Node *x, *current, *parent;
/***********************************************
* allocate node for data and insert in tree *
***********************************************/
/* find x's parent */
current = root;
parent = 0;
while (current) {
if (compEQ(data, current->data)) return (current);
parent = current;
current = compLT(data, current->data) ?
current->left : current->right;
}
/* setup new node */
if ((x = malloc (sizeof(*x))) == 0) {
fprintf (stderr, "insufficient memory (insertNode)\n");
exit(1);
}
x->data = data;
x->parent = parent;
x->left = NULL;
x->right = NULL;
/* insert x in tree */
if(parent)
if(compLT(x->data, parent->data))
parent->left = x;
else
parent->right = x;
else
root = x;
return(x);
}
void deleteNode(Node *z) {
Node *x, *y;
/*****************************
* delete node z from tree *
*****************************/
/* y will be removed from the parent chain */
if (!z || z == NULL) return;
/* find tree successor */
if (z->left == NULL || z->right == NULL)
y = z;
else {
y = z->right;
while (y->left != NULL) y = y->left;
}
/* x is y's only child */
яяя if (y->left != NULL)
яяяяяяя x = y->left;
яяя else
яяяяяяя x = y->right;
яяя /* remove y from the parent chain */
яяя if (x) x->parent = y->parent;
яяя if (y->parent)
яяяяяяя if (y == y->parent->left)
яяяяяяяяяяя y->parent->left = x;
яяяяяяя else
яяяяяяяяяяя y->parent->right = x;
яяя else
яяяяяяя root = x;
яяя /* y is the node we're removing */
яяя /* z is the data we're removing */
яяя /* if z and y are not the same, replace z with y. */
яяя if (y != z) {
яяяяяяя y->left = z->left;
яяяяяяя if (y->left) y->left->parent = y;
яяяяяяя y->right = z->right;
яяяяяяя if (y->right) y->right->parent = y;
яяяяяяя y->parent = z->parent;
яяяяяяя if (z->parent)
яяяяяяяяяяя if (z == z->parent->left)
яяяяяяяяяяяяяяя z->parent->left = y;
яяяяяяяяяяя else
яяяяяяяяяяяяяяя z->parent->right = y;
яяяяяяя else
яяяяяяяяяяя root = y;
яяяяяяя free (z);
яяя } else {
яяяяяяя free (y);
яяя }
}
Node *findNode(T data) {
яя /*******************************
яяя *я find node containing dataя *
яяя *******************************/
яяя Node *current = root;
яяя while(current != NULL)
яяяяяяя if(compEQ(data, current->data))
яяяяяяяяяяя return (current);
яяяяяяя else
яяяяяяяяяяя current = compLT(data, current->data) ?
яяяяяяяяяяяяяяя current->left : current->right;
яяя return(0);
}
Коды для быстрого поиска (функции Quicksort)
typedef int T; /* type of item to be sorted */
typedef int tblIndex; /* type of subscript */
#define CompGT(a,b) (a > b)
tblIndex partition(T *a, tblIndex lb, tblIndex ub) {
T t, pivot;
tblIndex i, j, p;
/*******************************
* partition array a[lb..ub] *
*******************************/
/* select pivot and exchange with 1st element */
p = lb + ((ub - lb)>>1);
pivot = a[p];
a[p] = a[lb];
/* sort lb+1..ub based on pivot */
i = lb+1;
j = ub;
while (1) {
while (i < j && compGT(pivot, a[i])) i++;
while (j >= i && compGT(a[j], pivot)) j--;
if (i >= j) break;
t = a[i];
a[i] = a[j];
a[j] = t;
j--; i++;
}
/* pivot belongs in a[j] */
a[lb] = a[j];
a[j] = pivot;
return j;
}
void quickSort(T *a, tblIndex lb, tblIndex ub) {
tblIndex m;
/**************************
* sort array a[lb..ub] *
**************************/
while (lb < ub) {
/* quickly sort short lists */
if (ub - lb <= 12) {
insertSort(a, lb, ub);
return;
}
/* partition into two segments */
m = partition (a, lb, ub);
/* sort the smallest partition */
/* to minimize stack requirements */
if (m - lb <= ub - m) {
quickSort(a, lb, m - 1);
lb = m + 1;
} else {
quickSort(a, m + 1, ub);
ub = m - 1;
}
}
}
Коды для хеш-таблиц
typedef int T; /* type of item to be sorted */
#define compEQ(a,b) (a == b)
typedef struct Node_ {
struct Node_ *next; /* next node */
T data; /* data stored in node */
} Node;
typedef int hashTableIndex;
Node **hashTable;
int hashTableSize;
hashTableIndex hash(T data) {
/***********************************
* hash function applied to data *
***********************************/
return (data % hashTableSize);
}
Node *insertNode(T data) {
Node *p, *p0;
hashTableIndex bucket;
/************************************************
* allocate node for data and insert in table *
************************************************/
/* insert node at beginning of list */
bucket = hash(data);
if ((p = malloc(sizeof(Node))) == 0) {
fprintf (stderr, "out of memory (insertNode)\n");
exit(1);
}
p0 = hashTable[bucket];
hashTable[bucket] = p;
p->next = p0;
p->data = data;
return p;
}
void deleteNode(T data) {
Node *p0, *p;
hashTableIndex bucket;
/********************************************
* delete node containing data from table *
********************************************/
/* find node */
p0 = 0;
bucket = hash(data);
p = hashTable[bucket];
while (p && !compEQ(p->data, data)) {
p0 = p;
p = p->next;
}
if (!p) return;
/* p designates node to delete, remove it from list */
if (p0)
/* not first node, p0 points to previous node */
p0->next = p->next;
else
/* first node on chain */
hashTable[bucket] = p->next;
free (p);
}
Node *findNode (T data) {
Node *p;
/*******************************
* find node containing data *
*******************************/
p = hashTable[hash(data)];
while (p && !compEQ(p->data, data))
p = p->next;
return p;
}
Коды для красно-черных деревьев
typedef int T; /* type of item to be sorted */
#define compLT(a,b) (a < b)
#define compEQ(a,b) (a == b)
/* Red-Black tree description */
typedef enum { BLACK, RED } nodeColor;
typedef struct Node_ {
struct Node_ *left; /* left child */
struct Node_ *right; /* right child */
struct Node_ *parent; /* parent */
nodeColor color; /* node color (BLACK, RED) */
T data; /* data stoRED in node */
} Node;
#define NIL &sentinel /* all leafs are sentinels */
Node sentinel = { NIL, NIL, 0, BLACK, 0};
Node *root = NIL; /* root of Red-Black tree */
void rotateLeft(Node *x) {
/**************************
* rotate node x to left *
**************************/
Node *y = x->right;
/* establish x->right link */
x->right = y->left;
if (y->left != NIL) y->left->parent = x;
/* establish y->parent link */
if (y != NIL) y->parent = x->parent;
if (x->parent) {
if (x == x->parent->left)
x->parent->left = y;
else
x->parent->right = y;
} else {
root = y;
}
/* link x and y */
y->left = x;
if (x != NIL) x->parent = y;
}
void rotateRight(Node *x) {
/****************************
* rotate node x to right *
****************************/
Node *y = x->left;
/* establish x->left link */
x->left = y->right;
if (y->right != NIL) y->right->parent = x;
/* establish y->parent link */
if (y != NIL) y->parent = x->parent;
if (x->parent) {
if (x == x->parent->right)
x->parent->right = y;
else
x->parent->left = y;
} else {
root = y;
яяя }
яяя /* link x and y */
яяя y->right = x;
яяя if (x != NIL) x->parent = y;
}
void insertFixup(Node *x) {
яя /*************************************
яяя *я maintain Red-Black tree balanceя *
яяя *я after inserting node xяяяяяяяяяя *
яяя *************************************/
яяя /* check Red-Black properties */
яяя while (x != root && x->parent->color == RED) {
яяяяяяя /* we have a violation */
яяяяяяя if (x->parent == x->parent->parent->left) {
яяяяяяяяяяя Node *y = x->parent->parent->right;
яяяяяяяяяяя if (y->color == RED) {
яяяяяяяяяяяяяяя /* uncle is RED */
яяяяяяяяяяяяяяя x->parent->color = BLACK;
яяяяяяяяяяяяяяя y->color = BLACK;
яяяяяяяяяяяяяяя x->parent->parent->color = RED;
яяяяяяяяяяяяяяя x = x->parent->parent;
яяяяяяяяяяя } else {
яяяяяяяяяяяяяяя /* uncle is BLACK */
яяяяяяяяяяяяяяя if (x == x->parent->right) {
яяяяяяяяяяяяяяяяяяя /* make x a left child */
яяяяяяяяяяяяяяяяяяя x = x->parent;
яяяяяяяяяяяяяяяяяяя rotateLeft(x);
яяяяяяяяяяяяяяя }
яяяяяяяяяяяяяяя /* recolor and rotate */
яяяяяяяяяяяяяяя x->parent->color = BLACK;
яяяяяяяяяяяяяяя x->parent->parent->color = RED;
яяяяяяяяяяяяяяя rotateRight(x->parent->parent);
яяяяяяяяяяя }
яяяяяяя } else {
яяяяяяяяяяя /* mirror image of above code */
яяяяяяяяяяя Node *y = x->parent->parent->left;
яяяяяяяяяяя if (y->color == RED) {
яяяяяяяяяяяяяяя /* uncle is RED */
яяяяяяяяяяяяяяя x->parent->color = BLACK;
яяяяяяяяяяяяяяя y->color = BLACK;
яяяяяяяяяяяяяяя x->parent->parent->color = RED;
яяяяяяяяяяяяяяя x = x->parent->parent;
яяяяяяяяяяя } else {
яяяяяяяяяяяяяяя /* uncle is BLACK */
яяяяяяяяяяяяяяя if (x == x->parent->left) {
яяяяяяяяяяяяяяяяяяя x = x->parent;
яяяяяяяяяяяяяяяяяяя rotateRight(x);
яяяяяяяяяяяяяяя }
яяяяяяяяяяяяяяя x->parent->color = BLACK;
яяяяяяяяяяяяяяя x->parent->parent->color = RED;
яяяяяяяяяяяяяяя rotateLeft(x->parent->parent);
яяяяяяяяяяя }
яяяяяяя }
яяя }
яяя root->color = BLACK;
}
Node *insertNode(T data) {
яяя Node *current, *parent, *x;
яя /***********************************************
яяя *я allocate node for data and insert in treeя *
яяя ***********************************************/
яяя /* find where node belongs */
яяя current = root;
яяя parent = 0;
яяя while (current != NIL) {
яяяяяяя if (compEQ(data, current->data)) return (current);
яяяяяяя parent = current;
яяяяяяя current = compLT(data, current->data) ?
яяяяяяяяяяя current->left : current->right;
яяя }
яяя /* setup new node */
яяя if ((x = malloc (sizeof(*x))) == 0) {
яяяяяяя printf ("insufficient memory (insertNode)\n");
яяяяяяя exit(1);
яяя }
яяя x->data = data;
яяя x->parent = parent;
яяя x->left = NIL;
яяя x->right = NIL;
яяя x->color = RED;
яяя /* insert node in tree */
яяя if(parent) {
яяяяяяя if(compLT(data, parent->data))
яяяяяяяяяяя parent->left = x;
яяяяяяя else
яяяяяяяяяяя parent->right = x;
яяя } else {
яяяяяяя root = x;
яяя }
яяя insertFixup(x);
яяя return(x);
}
void deleteFixup(Node *x) {
яя /*************************************
яяя *я maintain Red-Black tree balanceя *
яяя *я after deleting node xяяяяяяяяяяя *
яяя *************************************/
яяя while (x != root && x->color == BLACK) {
яяяяяяя if (x == x->parent->left) {
яяяяяяяяяяя Node *w = x->parent->right;
яяяяяяяяяяя if (w->color == RED) {
яяяяяяяяяяяяяяя w->color = BLACK;
яяяяяяяяяяяяяяя x->parent->color = RED;
яяяяяяяяяяяяяяя rotateLeft (x->parent);
я яяяяяяяяяяяяяяw = x->parent->right;
яяяяяяяяяяя }
яяяяяяяяяяя if (w->left->color == BLACK && w->right->color == BLACK) {
яяяяяяяяяяяяяяя w->color = RED;
яяяяяяяяяяяяяяя x = x->parent;
яяяяяяяяяяя } else {
яяяяяяяяяяяяяяя if (w->right->color == BLACK) {
яяяяяяяяяяяяяяяяяяя w->left->color = BLACK;
яяяяяяяяяяяяяяяяяяя w->color = RED;
яяяяяяяяяяяяяяяяяяя rotateRight (w);
яяяяяяяяяяяяяяяяяяя w = x->parent->right;
яяяяяяяяяяяяяяя }
яяяяяяяяяяяяяяя w->color = x->parent->color;
яяяяяяяяяяяяяяя x->parent->color = BLACK;
яяяяяяяяяяяяяяя w->right->color = BLACK;
яяяяяяяяяяяяяяя rotateLeft (x->parent);
яяяяяяяяяяяяяяя x = root;
яяяяяяяяяяя }
яяяяяяя } else {
яяяяяяяяяяя Node *w = x->parent->left;
яяяяяяяяяяя if (w->color == RED) {
яяяяяяяяяяяяяяя w->color = BLACK;
яяяяяяяяяяяяяяя x->parent->color = RED;
яяяяяяяяяяяяяяя rotateRight (x->parent);
яяяяяяяяяяяяяяя w = x->parent->left;
яяяяяяяяяяя }
яяяяяяяяяяя if (w->right->color == BLACK && w->left->color == BLACK) {
яяяяяяяяяяяяяяя w->color = RED;
яяяяяяяяяяяяяяя x = x->parent;
яяяяяяяяяяя } else {
яяяяяяяяяяяяяяя if (w->left->color == BLACK) {
яяяяяяяяяяяяяяяяяяя w->right->color = BLACK;
яяяяяяяяяяяяяяяяяяя w->color = RED;
яяяяяяяяяяяяяяяяяяя rotateLeft (w);
яяяяяяяяяяяяяяяяяяя w = x->parent->left;
яяяяяяяяяяяяяяя }
яяяяяяяяяяяяяяя w->color = x->parent->color;
яяяяяяяяяяяяяяя x->parent->color = BLACK;
яяяяяяяяяяяяяяя w->left->color = BLACK;
яяяяяяяяяяяяяяя rotateRight (x->parent);
яяяяяяяяяяяяяяя x = root;
яяяяяяяяяяя }
яяяяяяя }
яяя }
яяя x->color = BLACK;
}
void deleteNode(Node *z) {
яяя Node *x, *y;
яя /*****************************
яяя *я delete node z from treeя *
яяя *****************************/
яяя if (!z || z == NIL) return;
яяя if (z->left == NIL || z->right == NIL) {
яяяяяяя /* y has a NIL node as a child */
яяяяяяя y = z;
яяя } else {
яяяяяяя /* find tree successor with a NIL node as a child */
яяяяяяя y = z->right;
яяяяяяя while (y->left != NIL) y = y->left;
яяя }
яяя /* x is y's only child */
яяя if (y->left != NIL)
яяяяяяя x = y->left;
яяя else
яяяяяяя x = y->right;
яяя /* remove y from the parent chain */
яяя x->parent = y->parent;
яяя if (y->parent)
яяяяяяя if (y == y->parent->left)
яяяяяяяяяяя y->parent->left = x;
яяяяяяя else
яяяяяяяяяяя y->parent->right = x;
яяя else
яяяяяяя root = x;
яяя if (y != z) z->data = y->data;
яяя if (y->color == BLACK)
яяяяяяя deleteFixup (x);
яяя free (y);
}
Node *findNode(T data) {
яя /*******************************
яяя *я find node containing dataя *
яяя *******************************/
яяя Node *current = root;
яяя while(current != NIL)
яяяяяяя if(compEQ(data, current->data))
яяяяяяяяяяя return (current);
яяяяяяя else
яяяяяяяяяяя current = compLT (data, current->data) ?
яяяяяяяяяяяяяяя current->left : current->right;
яяя return(0);
}
Коды для разделенных списков
typedef int T; /* type of item to be sorted */
#define compLT(a,b) (a < b)
#define compEQ(a,b) (a == b)
/*
* levels range from (0 .. MAXLEVEL)
*/
#define MAXLEVEL 15
typedef struct Node_ {
T data; /* user's data */
struct Node_ *forward[1]; /* skip list forward pointer */
} Node;
typedef struct {
Node *hdr; /* list Header */
int listLevel; /* current level of list */
} SkipList;
SkipList list; /* skip list information */
#define NIL list.hdr
Node *insertNode(T data) {
int i, newLevel;
Node *update[MAXLEVEL+1];
Node *x;
/***********************************************
* allocate node for data and insert in list *
***********************************************/
/* find where data belongs */
x = list.hdr;
for (i = list.listLevel; i >= 0; i--) {
while (x->forward[i] != NIL
&& compLT(x->forward[i]->data, data))
x = x->forward[i];
update[i] = x;
}
x = x->forward[0];
if (x != NIL && compEQ(x->data, data)) return(x);
/* determine level */
newLevel = 0;
while (rand() < RAND_MAX/2) newLevel++;
if (newLevel > MAXLEVEL) newLevel = MAXLEVEL;
if (newLevel > list.listLevel) {
for (i = list.listLevel + 1; i <= newLevel; i++)
update[i] = NIL;
list.listLevel = newLevel;
}
/* make new node */
if ((x = malloc(sizeof(Node) +
newLevel*sizeof(Node *))) == 0) {
printf ("insufficient memory (insertNode)\n");
exit(1);
}
x->data = data;
/* update forward links */
for (i = 0; i <= newLevel; i++) {
x->forward[i] = update[i]->forward[i];
update[i]->forward[i] = x;
яя я}
яяя return(x);
}
void deleteNode(T data) {
яяя int i;
яяя Node *update[MAXLEVEL+1], *x;
яя /*******************************************
яяя *я delete node containing data from listя *
яяя *******************************************/
яяя /* find where data belongs */
яяя x = list.hdr;
яяя for (i = list.listLevel; i >= 0; i--) {
яяяяяяя while (x->forward[i] != NIL
яяяяяяяяя && compLT(x->forward[i]->data, data))
яяяяяяяяяяя x = x->forward[i];
яяяяяяя update[i] = x;
яяя }
яяя x = x->forward[0];
яяя if (x == NIL || !compEQ(x->data, data)) return;
яяя /* adjust forward pointers */
яяя for (i = 0; i <= list.listLevel; i++) {
яяяяяяя if (update[i]->forward[i] != x) break;
яяяяяяя update[i]->forward[i] = x->forward[i];
яяя }
яяя free (x);
яяя /* adjust header level */
яяя while ((list.listLevel > 0)
яяя && (list.hdr->forward[list.listLevel] == NIL))
яяяяяяя list.listLevel--;
}
Node *findNode(T data) {
яяя int i;
яяя Node *x = list.hdr;
яя /*******************************
яяя *я find node containing dataя *
яяя *******************************/
яяя for (i = list.listLevel; i >= 0; i--) {
яяяяяяя while (x->forward[i] != NIL
яяяяяяяяя && compLT(x->forward[i]->data, data))
яяяяяяяяяяя x = x->forward[i];
яяя }
яяя x = x->forward[0];
яяя if (x != NIL && compEQ(x->data, data)) return (x);
яяя return(0);
}
void initList() {
яяя int i;
яя /**************************
яяя *я initialize skip listя *
яяя **************************/
яяя if ((list.hdr = malloc(sizeof(Node) + MAXLEVEL*sizeof(Node *))) == 0) {
яяяяяяя printf ("insufficient memory (initList)\n");
яяяяяяя exit(1);
яяя }
яяя for (i = 0; i <= MAXLEVEL; i++)
яяяяяяя list.hdr->forward[i] = NIL;
яяя list.listLevel = 0;
}
Коды для сортировки Шелла
typedef int T; /* type of item to be sorted */
typedef int tblIndex; /* type of subscript */
#define compGT(a,b) (a > b)
void shellSort(T *a, tblIndex lb, tblIndex ub) {
tblIndex n, h, i, j;
T t;
/**************************
* sort array a[lb..ub] *
**************************/
/* compute largest increment */
n = ub - lb + 1;
h = 1;
if (n < 14)
h = 1;
else if (sizeof(tblIndex) == 2 && n > 29524)
h = 3280;
else {
while (h < n) h = 3*h + 1;
h /= 3;
h /= 3;
}
while (h > 0) {
/* sort-by-insertion in increments of h */
for (i = lb + h; i <= ub; i++) {
t = a[i];
for (j = i-h; j >= lb && compGT(a[j], t); j -= h)
a[j+h] = a[j];
a[j+h] = t;
}
/* compute next increment */
h /= 3;
}
}
Коды для сортировки вставками
typedef int T; /* type of item to be sorted */
typedef int tblIndex; /* type of subscript */
#define compGT(a,b) (a > b)
void insertSort(T *a, tblIndex lb, tblIndex ub) {
T t;
tblIndex i, j;
/**************************
* sort array a[lb..ub] *
**************************/
for (i = lb + 1; i <= ub; i++) {
t = a[i];
/* Shift elements down until */
/* insertion point found. */
for (j = i-1; j >= lb && compGT(a[j], t); j--)
a[j+1] = a[j];
/* insert */
a[j+1] = t;
}
}
Коды для стандартной реализации быстрого поиска
#include <limits.h>
#define MAXSTACK (sizeof(size_t) * CHAR_BIT)
static void exchange(void *a, void *b, size_t size) {
size_t i;
/******************
* exchange a,b *
******************/
for (i = sizeof(int); i <= size; i += sizeof(int)) {
int t = *((int *)a);
*(((int *)a)++) = *((int *)b);
*(((int *)b)++) = t;
}
for (i = i - sizeof(int) + 1; i <= size; i++) {
char t = *((char *)a);
*(((char *)a)++) = *((char *)b);
*(((char *)b)++) = t;
}
}
void qsort(void *base, size_t nmemb, size_t size,
int (*compar)(const void *, const void *)) {
void *lbStack[MAXSTACK], *ubStack[MAXSTACK];
int sp;
unsigned int offset;
lbStack[0] = (char *)base;
ubStack[0] = (char *)base + (nmemb-1)*size;
for (sp = 0; sp >= 0; sp--) {
char *lb, *ub, *m;
char *P, *i, *j;
lb = lbStack[sp];
ub = ubStack[sp];
while (lb < ub) {
/* select pivot and exchange with 1st element */
offset = (ub - lb) >> 1;
P = lb + offset - offset % size;
exchange (lb, P, size);
/* partition into two segments */
i = lb + size;
j = ub;
while (1) {
while (i < j && compar(lb, i) > 0) i += size;
while (j >= i && compar(j, lb) > 0) j -= size;
if (i >= j) break;
exchange (i, j, size);
j -= size;
i += size;
}
/* pivot belongs in A[j] */
exchange (lb, j, size);
m = j;
/* keep processing smallest segment, and stack largest */
if (m - lb <= ub - m) {
if (m + size < ub) {
lbStack[sp] = m + size;
ubStack[sp++] = ub;
}
ub = m - size;
} else {
if (m - size > lb) {
lbStack[sp] = lb;
ubStack[sp++] = m - size;
}
lb = m + size;
}
}
}
}
Красно-черные деревья
Двоичные деревья работают лучше всего, когда они сбалансированы, когда длина пути от корня до любого из листьев находится в определенных пределах, связанных с числом узлов. Красно-черные деревья – один из способов балансировки деревьев. Название происходит от стандартной раскраски узлов таких деревьев в красный и черный цвета. Цвета узлов используются при балансировке дерева. Во время операций вставки и удаления поддеревья может понадобиться повернуть, чтобы достигнуть сбалансированности дерева. Оценкой как среднего время, так и наихудшего является O(lg n).
Этот раздел – один из наиболее трудных в данной книжке. Если вы ошалеете от вращений деревьев, попробуйте перейти к следующему разделу о разделенных списках. Прекрасно написанные разделы о красно-черных деревьях вы найдете у Кормена[2].
Теория
Красно-черное дерево – это бинарное дерево с следующими свойствами[2]:
1. Каждый узел покрашен либо в черный, либо в красный цвет.
2. Листьями объявляются NIL-узлы (т.е. “виртуальные” узлы, наследники узлов, которые обычно называют листьями; на них “указывают” NULL указатели). Листья покрашены в черный цвет.
3. Если узел красный, то оба его потомка черны.
4. На всех ветвях дерева, ведущих от его корня к листьям, число черных узлов одинаково.
Количество черных узлов на ветви от корня до листа называется черной высотой дерева. Перечисленные свойства гарантируют, что самая длинная ветвь от корня к листу не более чем вдвое длиннее любой другой ветви от корня к листу. Чтобы понять, почему это так, рассмотрим дерево с черной высотой 2. Кратчайшее возможное расстояние от корня до листа равно двум – когда оба узла черные. Длиннейшее расстояние от корня до листа равно четырем – узлы при этом покрашены (от корня к листу) так: красный®черный®красный®черный. Сюда нельзя добавить черные узлы, поскольку при этом нарушится свойство 4, из которого вытекает корректность понятия черной высоты.
Поскольку согласно свойству 3 у красных узлов непременно черные наследники, в подобной последовательности недопустимы и два красных узла подряд. Таким образом, длиннейший путь, который мы можем сконструировать, состоит из чередования красных и черных узлов, что и приводит нас к удвоенной длине пути, проходящего только через черные узлы. Все операции над деревом должны уметь работать с перечисленными свойствами. В частности, при вставке и удалении эти свойства должны сохраниться.
Вставка
Чтобы вставить узел, мы сначала ищем в дереве место, куда его следует добавить. Новый узел всегда добавляется как лист, поэтому оба его потомка являются NIL-узлами и предполагаются черными. После вставки красим узел в красный цвет. После этого смотрим на предка и проверяем, не нарушается ли красно-черное свойство. Если необходимо, мы перекрашиваем узел и производим поворот, чтобы сбалансировать дерево.
Вставив красный узел, мы сохраняем свойство черной высоты (свойство 4). Однако, при этом может оказаться нарушенным свойство 3. Это свойство состоит в том, что оба потомка красного узла обязательно черны. В нашем случае оба потомка нового узла черны по определению (поскольку они являются NIL-узлами), так что рассмотрим ситуацию, когда предок нового узла красный: при этом будет нарушено свойство 3. Достаточно рассмотреть следующие два случая:
· Красный предок, красный “дядя”. Ситуацию красный-красный иллюстрирует рис. 3.6. У нового узла X предок и “дядя” оказались красными. Простое перекрашивание избавляет нас от красно-красного нарушения. После перекраски нужно проверить “дедушку” нового узла (узел B), поскольку он может оказаться красным. Обратите внимание на распространение влияния красного узла на верхние узлы дерева. В самом конце корень мы красим в черный цвет корень дерева. Если он был красным, то при этом увеличивается черная высота дерева.
· Красный предок, черный “дядя”. На рис. 3.7 представлен другой вариант красно-красного нарушения – “дядя” нового узла оказался черным.
Здесь узлы может понадобиться вращать, чтобы скорректировать поддеревья. В этом месте алгоритм может остановиться из-за отсутствия красно-красных конфликтов и вершина дерева (узел A)
окрашивается в черный цвет. Обратите внимание, что если узел X был в начале правым потомком, то первым применяется левое вращение, которое делает этот узел левым потомком.
Каждая корректировка, производимая при вставке узла, заставляет нас подняться в дереве на один шаг. В этом случае до остановки алгоритма будет сделано 1 вращение (2, если узел был правым потомком). Метод удаления аналогичен.

Рис. 3.6: Вставка – Красный предок, красный “дядя”

Рис. 3.7: Вставка – красный предок, черный “дядя”
Реализация
Реализация работы с красно-черными деревьями на Си находится в разделе 4.7. Операторы typedef T, а также сравнивающие compLT и compEQ следует изменить так, чтобы они соответствовали данным, хранимым в узлах дерева. В каждом узле Node хранятся указатели left, right на двух потомков и parent на предка. Цвет узла хранится в поле color и может быть либо RED, либо BLACK. Собственно данные хранятся в поле data. Все листья дерева являются “сторожевыми” (sentinel), что сильно упрощает коды. Узел root является корнем дерева и в самом начале является сторожевым.
Функция insertNode запрашивает память под новый узел, устанавливает нужные значения его полей и вставляет в дерево. Соответственно, она вызывает insertFixup, которая следит за сохранением красно-черных свойств. Функция deleteNode удаляет узел из дерева. Она вызывает deleteFixup, которая восстанавливает красно-черные свойства. Функция findNode ищет в дереве нужный узел.
Литература
[1] Donald E. Knuth. The Art of Computer Programming, volume 3. Massachusetts:
Addison-Wesley, 1973. Есть русский перевод: Д.Кнут. Искусство программирования для ЭВМ. Т.3. Изд-во “Мир”, М.1978.
[2] Thomas H. Cormen, Charles E. Leiserson, and Ronald L. Rivest. Introduction to Algo-
rithms. New York: McGraw-Hill, 1992.
[3] Alfred V. Aho, John E. Hopcroft, and Jeffrey D. Ullman. Data Structures and Algorithms. Massachusetts: Addison-Wesley, 1983.
[4] Peter K. Pearson. Fast hashing of variable-length text strings. Communications of the
ACM, 33(6):677-680, June 1990.
[5] William Pugh. Skip lists: A probabilistic alternative to balanced trees. Communications
of the ACM, 33(6):668-676, June 1990.
Поиск в бинарных деревьях
В разделе 1 мы использовали двоичный поиск для поиска данных в массиве. Этот метод чрезвычайно эффективен, поскольку каждая итерация вдвое уменьшает число элементов, среди которых нам нужно продолжать поиск. Однако, поскольку данные хранятся в массиве, операции вставки и удаления элементов не столь эффективны. Двоичные деревья позволяют сохранить эффективность всех трех операций – если работа идет с “случайными” данными. В этом случае время поиска оценивается как O(lg n). Наихудший случай – когда вставляются упорядоченные данные. В этом случае оценка время поиска – O(n). Подробности вы найдете в работе Кормена [2].
Теория
Двоичное дерево – это дерево, у которого каждый узел имеет не более двух наследников. Пример бинарного дерева приведен на рис. 3.2. Предполагая, что Key содержит значение, хранимое в данном узле, мы можем сказать, что бинарное дерево обладает следующим свойством: у всех узлов, расположенных слева от данного узла, значение соответствующего поля меньше, чем Key, у всех узлов, расположенных справа от него, – больше. Вершину дерева называют его корнем, узлы, у которых отсутствуют оба наследника, называются листьями. Корень дерева на рис. 3.2 содержит 20, а листья – 4, 16, 37 и 43. Высота дерева – это длина наидлиннейшего из путей от корня к листьям. В нашем примере высота дерева равна 2.

Рис. 3.2: Двоичное дерево
Чтобы найти в дереве какое-то значение, мы стартуем из корня и движемся вниз. Например, для поиска числа 15, мы замечаем, что 16 < 20, и потому идем влево. При втором сравнении имеем 16 > 7, так что мы движемся вправо. Третья попытка успешна – мы находим элемент с ключом, равным 15.
Каждое сравнение вдвое уменьшает количество оставшихся элементов. В этом отношении алгоритм похож на двоичный поиск в массиве. Однако, все это верно только в случаях, когда наше дерево сбалансировано. На рис. 3.3 показано другое дерево, содержащее те же элементы. Несмотря на то, что это дерево тоже бинарное, поиск в нем похож, скорее, на поиск в односвязном списке, время поиска увеличивается пропорционально числу запоминаемых элементов.

Рис. 3.3: Несбалансированное бинарное дерево
Вставка и удаление
Чтобы лучше понять, как дерево становится несбалансированным, посмотрим на процесс вставки пристальнее. Чтобы вставить 18 в дерево на рис. 3.2 мы ищем это число. Поиск приводит нас в узел 16, где благополучно завершается. Поскольку 18 > 16, мы попросту добавляет узел 18 в качестве правого потомка узла 16 (рис. 3.4).
Теперь мы видим, как возникает несбалансированность дерева. Если данные поступают в возрастающем порядке, каждый новый узел добавляется справа от последнего вставленного. Это приводит к одному длинному списку. Обратите внимание: чем более “случайны” поступающие данные, тем более сбалансированным получается дерево.
Удаления производятся примерно так же – необходимо только позаботиться о сохранении структуры дерева. Например, если из дерева на рис. 3.4 удаляется узел 20, его сначала нужно заменить на узел 37. Это даст дерево, изображенное на рис. 3.5. Рассуждения здесь примерно следующие. Нам нужно найти потомка узла 20, справа от которого расположены узлы с большими значениями. Таким образом, нам нужно выбрать узел с наименьшим значением, расположенный справа от узла 20. Чтобы найти его, нам и нужно сначала спуститься на шаг вправо (попадаем в узел 38), а затем на шаг влево (узел 37); эти двухшаговые спуски продолжаются, пока мы не придем в концевой узел, лист дерева.
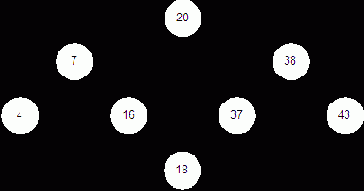
Рис. 3.4: Бинарное дерево после добавления узла 18

Рис. 3.5: Бинарное дерево после удаления узла 20
Реализация
Реализация алгоритма на Си находится в разделе 4.6. Операторы typedef T и compGT следует изменить так, чтобы они соответствовали данным, хранимым в дереве. Каждый узел Node содержит также указатели left, right на левого и правого потомков, а также указатель parent на предка. Собственно данные хранятся в поле data. Адрес узла, являющегося корнем дерева хранится в укзателе root, значение которого в самом начале, естественно, NULL. Функция insertNode запрашивает память под новый узел и вставляет узел в дерево, т.е.устанавливает нужные значения нужных указателей. Функция deleteNode, напротив, удаляет узел из дерева (т.е. устанавливает нужные значения нужных указателей), а затем освобождает память, которую занимал узел. Функция findNode ищет в дереве узел, содержащий заданное значение.
Разделенные списки
Разделенные списки – это связные списки, которые позволяют вам прыгнуть (skip) к нужному элементу. Это позволяет преодолеть ограничения последовательного поиска, являющегося основным источником неэффективного поиска в списках. В то же время вставка и удаление остаются сравнительно эффективными. Оценка среднего времени поиска в таких списках есть O(lg n). Для наихудшего случая оценкой является O(n), но худший случай крайне маловероятен. Отличное введение в разделенные списки вы найдете у Пью [5].
Теория
Идея, лежащая в основе разделенных списков, очень напоминает метод, используемый при поиске имен в адресной книжке. Чтобы найти имя, вы помечаете буквой страницу, откуда начинаются имена, начинающиеся с этой буквы. На рис. 3.8, например, самый верхний список представляет обычный односвязный список. Добавив один “уровень” ссылок, мы ускорим поиск. Сначала мы пойдем по ссылкам уровня 1, затем, когда дойдем по нужного отрезка списка, пойдем по ссылкам нулевого уровня.
Эта простая идея может быть расширена – мы можем добавить нужное число уровней. Внизу на рис. 3.8 мы видим второй уровень, который позволяет двигаться еще быстрее первого. При поиске элемента мы двигаемся по этому уровню, пока не дойдем до нужного отрезка списка. Затем мы еще уменьшаем интервал неопределенности, двигаясь по ссылкам 1-го уровня. Лишь после этого мы проходим по ссылкам 0-го уровня.
Вставляя узел, нам понадобится определить количество исходящих от него ссылок. Эта проблема легче всего решается с использованием случайного механизма: при добавлении нового узла мы “бросаем монету”, чтобы определить, нужно ли добавлять еще слой. Например, мы можем добавлять очередные слои до тех пор, пока выпадает “решка”. Если реализован только один уровень, мы имеем дело фактически с обычным списком и время поиска есть O(n). Однако, если имеется достаточное число уровней, разделенный список можно считать деревом с корнем на высшем уровне, а для дерева время поиска есть O(lg n).
Поскольку реализация разделенных списков включает в себя случайный процесс, для времени поиска в них устанавливаются вероятностные границы.
При обычных условиях эти границы довольно узки. Например, когда мы ищем элемент в списке из 1000 узлов, вероятность того, что время поиска окажется в 5 раз больше среднего, можно оценить как 1/ 1,000,000,000,000,000,000[5].

Рис. 3.8:Устройство разделенного списка
Реализация
Реализация работы с разделенными списками на Си находится в разделе 4.8. Операторы typedef T, а также compLT и compEQ следует изменить так, чтобы они соответствовали данным, хранимым в узлах списка. Кроме того, понадобится выбрать константу MAXLEVEL; ее значение выбирается в зависимости от ожидаемого объема данных.
Функция initList вызывается в самом начале. Она отводит память под заголовок списка и инициализирует его поля. Признаком того, что список пуст, Функция insertNode создает новый узел и вставляет его в список. Конечно, insertNode сначала отыскивает место в списке, куда узел должен быть вставлен. В массиве update функция учитывает встретившиеся ссылки на узлы верхних уровней. Эта информация в дальнейшем используется для корректной установки ссылок нового узла. Для этого узла, с помощью генератора случайных чисел, определяется значение newLevel, после чего отводится память для узла. Ссылки вперед устанавливаются по информации, содержащей в массиве update. Функция deleteNode удаляет узлы из списка и освобождает занимаемую ими память. Она реализована аналогично функции findNode и так же ищет в списке удаляемый узел.
Словарь
| Term | Термин |
| sort by insertion | сортировка вставками |
| array | массив |
| linked list | линейный список |
| comparison | сравнение |
| in-place | на месте (без дополнительных массивов) |
| stable sort | устойчивая сортировка |
| underflow | вырождение |
| overflow | переполнение |
| red-black tree | красно-черное дерево |
| skip list | разделенный список |
| rotation | вращение |
[1] Терминология Д.Кнута (т.1,п.2.3.1): postorder. В оригинале данной работы этот же порядок назван in-order.
Сортировка Шелла
Метод, предложенный Дональдом Л. Шеллом, является неустойчивой сортировкой по месту. Эффективность метода Шелла объясняется тем, что сдвигаемые элементы быстро попадают на нужные места. Среднее время для сортировки Шелла равняется O(n1.25), для худшего случая оценкой является O(n1.5). Дальнейшие ссылки см. в книжке Кнута [1].
Теория
На рис. 2.2(a) был приведен пример сортировки вставками. Мы сначала вынимали 1, затем сдвигали 3 и 5 на одну позицию вниз, после чего вставляли 1. Таким образом, нам требовались два сдвига. В следующий раз нам требовалось два сдвига, чтобы вставить на нужное место 2. На весь процесс нам требовалось 2+2+1=5 сдвигов.
На рис. 2.2(b) иллюстрируется сортировка Шелла. Мы начинаем, производя сортировку вставками с шагом 2. Сначала мы рассматриваем числа 3 и 1: извлекаем 2, сдвигаем 3 на 1 позицию с шагом 2, вставляем 2. Затем повторяем то же для чисел 5 и 2: извлекаем 2, сдвигаем вниз 5, вставляем 2. И т.д. Закончив сортировку с шагом 2, производим ее с шагом 1, т.е. выполняем обычную сортировку вставками. Всего при этом нам понадобится 1 + 1+ 1 = 3 сдвига. Таким образом, использовав вначале шаг, больший 1, мы добились меньшего числа сдвигов.

Рис. 2.2: Сортировка Шелла
Можно использовать самые разные схемы выбора шагов. Как правило, сначала мы сортируем массив с большим шагом, затем уменьшаем шаг и повторяем сортировку. В самом конце сортируем с шагом 1. Хотя этот метод легко объяснить, его формальный анализ довольно труден. В частности, теоретикам не удалось найти оптимальную схему выбора шагов. Кнут[1] провел множество экспериментов и следующую формулу выбора шагов (h) для массива длины N:

Вот несколько первых значений h:

Чтобы отсортировать массив длиной 100, прежде всего найдем номер s, для которого hs ³ 100. Согласно приведенным цифрам, s = 5. Нужное нам значение находится двумя строчками выше. Таким образом, последовательность шагов при сортировке будет такой: 13-4-1. Ну, конечно, нам не нужно хранить эту последовательность: очередное значение h находится из предыдущего по формуле

Реализация
Реализацию сортировки Шелла на Си вы найдете в разделе 4.2. Оператор typedef T и оператор сравнения compGT следует изменить так, чтобы они соответствовали данным, хранимым в массиве. Основная часть алгоритма – сортировка вставками с шагом h.
Сортировка вставками
Один из простейших способов отсортировать массив – сортировка вставками. В обычной жизни мы сталкиваемся с этим методом при игре в карты. Чтобы отсортировать имеющиеся в вас карты, вы вынимаете карту, сдвигаете оставшиеся карты, а затем вставляете карту на нужное место. Процесс повторяется до тех пор, пока хоть одна карта находится не на месте. Как среднее, так и худшее время для этого алгоритма – O(n2). Дальнейшую информацию можно получить в книжке Кнута [1].
Теория
На рис.2.2(a) мы вынимаем элемент 3. Затем элементы, расположенные выше, сдвигаем вниз – до тех пор, пока не найдем место, куда нужно вставить 3. Это процесс продолжается на рис.Ðèñ. 2.1(b) для числа 1. Наконец, на рис.2.1 (c) мы завершаем сортировку, поместив 2 на нужное место.
Если длина нашего массива равна n, нам нужно пройтись по n – 1 элементам. Каждый раз нам может понадобиться сдвинуть n – 1 других элементов. Вот почему этот метод требует довольно-таки много времени.
Сортировка вставками относится к числу методов сортировки по месту. Другими словами, ей не требуется вспомогательная память, мы сортируем элементы массива, используя только память, занимаемую самим массивом. Кроме того, она является устойчивой – если среди сортируемых ключей имеются одинаковые, после сортировки они остаются в исходном порядке.

Рис. 2.1: Сортировка вставками
Реализация
Реализацию сортировки вставками на Си вы найдете в разделе 4.1. Оператор typedef T и оператор сравнения compGT следует изменить так, чтобы они соответствовали данным, хранимым в таблице.
Сравнение методов
В данном разделе мы сравним описанные алгоритмы сортировки: вставками, Шелла и быструю сортировку. Есть несколько факторов, влияющих на выбор алгоритма в каждой конкретной ситуации:
· Устойчивость. Напомним, что устойчивая сортировка не меняет взаимного расположения элементов с равными ключами. Сортировка вставками – единственный из рассмотренных алгоритмов, обладающих этим свойством.
· Память. Сортировке на месте не требуется дополнительная память. Сортировка вставками и Шелла удовлетворяют этому условию. Быстрой сортировке требуется стек для организации рекурсии. Однако, требуемое этому алгоритму место можно сильно уменьшить, повозившись с алгоритмом.
· Время. Время, нужное для сортировки наших данных, легко становится астрономическим (см. таблицу 1.1). Таблица 2.2 позволяет сравнить временные затраты каждого из алгоритмов по количеству исполняемых операторов..
| Method | statements | average time | worst-case time |
| insertion sort | 9 | O(n2) | O(n2) |
| shell sort | 17 | O(n1.25) | O(n1.5) |
| quicksort | 21 | O(n lg n) | O(n2) |
Таблица 2.2:Сравнение методов сортировки
· Время, затраченное каждым из алгоритмов на сортировку случайного набора данных, представлено в таблице 2.3.
| count | insertion | shell | quicksort |
| 16 | 39 ms | 45 ms | 51 ms |
| 256 | 4,969 ms | 1,230 ms | 911 ms |
| 4,096 | 1.315 sec | .033 sec | .020 sec |
| 65,536 | 416.437 sec | 1.254 sec | .461 sec |
Таблица 2.3: Время сортировки
Вероятность иметь ссылку уровня 2 равна j. В общем, количество ссылок на узел равно
 |
· Время. Алгоритм должен быть эффективным. Это особенно важно, когда ожидаются большие объемы данных. В таблице 3.2 сравниваются времена поиска для каждого алгоритма. Обратите внимание на то, что наихудшие случаи для хеш-таблиц и разделенных списков чрезвычайно маловероятны. Экспериментальные данные описаны ниже.
· Простота. Если алгоритм короток и прост, при его реализации и/или использовании ошибки будут допущены с меньшей вероятностью. Кроме того, это облегчает проблемы сопровождения программ. Количества операторов, исполняемых в каждом алгоритме, также содержатся в таблице 3.2.
|
метод |
операторы |
среднее время |
время в худшем случае |
|
хеш-таблицы |
26 |
O(1) |
O(n) |
|
несбалансированные деревья |
41 |
O(lg n) |
O(n) |
|
красно-черные деревья |
120 |
O(lg n) |
O(lg n) |
|
разделенные списки |
55 |
O(lg n) |
O(n) |
В таблице 3.3 приведены времена, требуемые для вставки, поиска и удаления 65536 (216) случайных элементов. В этих экспериментах размер хеш-таблицы равнялся10009, для разделенных списков допускалось до 16 уровней ссылок. Конечно, в реальных ситуациях времена могут отличаться от приведенных здесь, однако, таблица дает достаточно информации для выбора подходящего алгоритма.
|
метод |
вставка |
поиск |
удаление |
|
хеш-таблицы |
18 |
8 |
10 |
|
несбалансированные деревья |
37 |
17 |
26 |
|
красно-черные деревья |
40 |
16 |
37 |
|
разделенные списки |
48 |
31 |
35 |
В таблице 3.4 приведены средние времена поиска для двух случаев: случайных данных, и упорядоченных, значения которых поступали в возрастающем порядке. Упорядоченные данные являются наихудшим случаем для несбалансированных деревьев, поскольку дерево вырождается в обычный односвязный список.
Приведены времена для “одиночного” поиска. Если бы нам понадобилось найти все 65536 элементов, то красно-черныму дереву понадобилось бы 6 секунд, а несбалансированному – около 1 часа.
|
Элементов |
хеш-таблицы |
несбалансированные деревья |
красно-черные деревья |
разделенные
списки |
|
|
16 |
4 |
3 |
2 |
5 |
|
|
случайные |
256 |
3 |
4 |
4 |
9 |
|
данные |
4,096 |
3 |
7 |
6 |
12 |
|
65,536 |
8 |
17 |
16 |
31 |
|
|
16 |
3 |
4 |
2 |
4 |
|
|
упорядоченные |
256 |
3 |
47 |
4 |
7 |
|
данные |
4,096 |
3 |
1,033 |
6 |
11 |
|
65,536 |
7 |
55,019 |
9 |
15 |
с исследования того, как эти
Поиск, вставка и удаление, как известно, – основные операции при работе с данными. Мы начнем с исследования того, как эти операции реализуются над сами известными объектами – массивами и (связанными) списками.
Массивы
На рис.1.1 показан массив из семи элементов с числовыми значениями. Чтобы найти в нем нужное нам число, мы можем использовать линейный поиск – его алгоритм приведен на рис. 1.2. Максимальное число сравнений при таком поиске – 7; оно достигается в случае, когда нужное нам значение находится в элементе A[6]. Если известно, что данные отсортированы, можно применить двоичный поиск (рис. 1.3). Переменные Lb и Ub содержат, соответственно, левую и правую границы отрезка массива, где находится нужный нам элемент. Мы начинаем всегда с исследования среднего элемента отрезка. Если искомое значение меньше среднего элемента, мы переходим к поиску в верхней половине отрезка, где все элементы меньше только что проверенного. Другими словами, значением Ub становится (M – 1) и на следующей итерации мы работаем с половиной массива. Таким образом, в результате каждой проверки мы двое сужаем область поиска. Так, в нашем примере, после первой итерации область поиска – всего лишь три элемента, после второй остается всего лишь один элемент. Таким образом, если длина массива равна 6, нам достаточно трех итераций, чтобы найти нужное число.

Рис. 1.1: Массив
Двоичный поиск – очень мощный метод. Если, например, длина массива равна 1023, после первого сравнения область сужается до 511 элементов, а после второй – до 255. Легко посчитать, что для поиска в массиве из 1023 элементов достаточно 10 сравнений.
Кроме поиска нам необходимо бывает вставлять и удалять элементы. К сожалению, массив плохо приспособлен для выполнения этих операций. Например, чтобы вставить число 18 в массив на рис. 1.1, нам понадобится сдвинуть элементы A[3]…A[6] вниз – лишь после этого мы сможем записать число 18 в элемент A[3]. Аналогичная проблема возникает при удалении элементов.
Для повышения эффективности операций вставки/удаления предложены связанные списки.
|
int function SequentialSearch (Array A , int Lb , int Ub , int Key ); begin for i = Lb to Ub do if A ( i ) = Key then return i ; return –1; end; |
|
int function BinarySearch (Array A , int Lb , int Ub , int Key ); begin do forever M = ( Lb + Ub )/2; if ( Key < A[M]) then Ub = M – 1; else if (Key > A[M]) then Lb = M + 1; else return M ; if (Lb > Ub ) then return –1; end; |
Односвязные списки
На рис. 1. 4 те же числа, что и раньше, хранятся в виде связанного списка; слово “связанный” часто опускают. Предполагая, что X и P являются указателями, число 18 можно вставить в такой список следующим образом:
X->Next = P->Next;
P->Next = X;
Списки позволяют осуществить вставку и удаление очень эффективно. Поинтересуемся, однако, как найти место, куда мы будем вставлять новый элемент, т.е. каким образом присвоить нужное значение указателю P. Увы, для поиска нужной точки придется пройтись по элементам списка. Таким образом, переход к спискам позволяет уменьшить время вставки/удаления элемента за счет увеличения времени поиска.

Рис. 1.4: Односвязный список
Оценки времени исполнения
Для оценки производительности алгоритмов можно использовать разные подходы. Самый бесхитростный –просто запустить каждый алгоритм на нескольких задачах и сравнить время исполнения. Другой способ – оценить время исполнения. Например, мы можем утверждать, что время поиска есть O(n) (читается так: о большое от n). Это означает, что при больших n время поиска не сильно больше, чем количество элементов. Когда используют обозначение O(), имеют в виду не точное время исполнения, а только его предел сверху, причем с точностью до постоянного множителя.
Когда говорят, например, что алгоритму требуется время порядка O(n2), имеют в виду, что время исполнения задачи растет не быстрее, чем квадрат количества элементов. Чтобы почувствовать, что это такое, посмотрите таблицу 1.1, где приведены числа, иллюстрирующие скорость роста для нескольких разных функций. Скорость роста O(lg n) характеризует алгоритмы типа двоичного поиска. Логарифм по основанию 2, lg, увеличивается на 1, когда n удваивается. Вспомните – каждое новое сравнение позволяет нам искать в вдвое большем списке. Именно поэтому говорят, что время работы при двоичном поиске растет как lg n.
|
n |
lg n |
n lg n |
n1.25 |
n2 |
|
1 |
0 |
0 |
1 |
1 |
|
16 |
4 |
64 |
32 |
256 |
|
256 |
8 |
2,048 |
1,024 |
65,536 |
|
4,096 |
12 |
49,152 |
32,768 |
16,777,216 |
|
65,536 |
16 |
1,048,565 |
1,048,476 |
4,294,967,296 |
|
1,048,476 |
20 |
20,969,520 |
33,554,432 |
1,099,301,922,576 |
|
16,775,616 |
24 |
402,614,784 |
1,073,613,825 |
281,421,292,179,456 |
Если считать, что числа в таблице 1.1 соответствуют микросекундам, то для задачи с 1048476 элементами алгоритму с временем работы O(lg n) потребуется 20 микросекунд, алгоритму с временем работы O(n1.25) – порядка 33 секунд, алгоритму с временем работы O(n2) – более 12 дней. В нижеследующем тексте для каждого алгоритма приведены соответствующие O-оценки. Более точные формулировки и доказательства можно найти в приводимых литературных ссылках.
Итак¼
Как мы видели, если массив отсортирован, то искать его элементы нужно с помощью двоичного поиска. Однако, не забудем, массив кто-то должен отсортировать! В следующем разделе мы исследует разные способы сортировки массива. Оказывается, эта задача встречается достаточно часто и требует заметных вычислительных ресурсов, поэтому сортирующие алгоритмы исследованы вдоль и поперек, известны алгоритмы, эффективность которых достигла теоретического предела.
Связанные списки позволяют эффективно вставлять и удалять элементы, но поиск в них последователен и потому отнимает много времени. Имеются алгоритмы, позволяющие эффективно выполнять все три операции, мы обсудим из в разделе о словарях.
