Идентификация литералов и строк
Уже давно
Утихло поле боя,
Но сорок тысяч
Воинов Китая
Погибли здесь,
Пожертвовав собою...
Ду Фо "Оплакиваю поражение при Чэньтао"
Казалось бы, что может быть сложного в идентификации строк? Если то, на что ссылается указатель (см. "Идентификация указателейконстант и смещений") выглядит как строка, - это и есть строка! Более того, в подавляющем большинстве случаев строки обнаруживаются и идентифицируются тривиальным просмотром дампа программы (при условии, конечно, что они не зашифрованы, но шифровка – тема отдельного разговора). Так-то, оно так, да не все столь просто!
Задача "номер один" – автоматизированное выявление строк в программе, - ведь не пролистывать же мегабайтовые дампы вручную? Существует множество алгоритмов идентификации строк. Самый простой (но не самый надежный) основан на двух следующих тезисах:
1) строка состоит из ограниченного ассортимента символов. В грубом приближении это – цифры, буквы алфавита (включая проблел), знаки препинания и служебные символы наподобие табуляции или возврата каретки;
2) строка должна состоять по крайней мере из нескольких символов.
Условимся считать минимальную длину строки равной N байтам, тогда для автоматического выявления всех строк достаточно отыскать все последовательности из N и более "строковых" символов. Весь вопрос в том, чему должна быть равна N, и какие символы включать в "строковые".
Если N мало, порядка трех-четырех байт, то мы получим очень большое количество ложных срабатываний. Напротив, когда N велико, порядка шести-восьми байт, число ложных срабатываний близко к нулю и ими можно пренебречь, но все короткие строки, например "OK", "YES", "NO" окажутся нераспознаны! Другая проблема – помимо знакоцифровых символов в строках встречаются и элементы псевдографики (особенно часты они в консольных приложениях), и всякие там "мордашки", "стрелки", "карапузики" – словом почти вся таблица ASCII.
Чем же тогда строка отличается от случайной последовательности байт? Частотный анализ бессилен – ему для нормальной работы требуется как минимум сотня байт текста, а мы говорим о строках из двух-трех символов!
Зайдем с другого конца – если в программе есть строка, значит, на нее кто-нибудь да ссылается. А раз так – можно поискать среди непосредственных значений указатель на распознанную строку. И, если он будет найден, шансы на то, что это действительно именно строка, а не случайная последовательность байт резко возрастают. Все просто, не так ли?
Просто, да не совсем! Рассмотрим следующим пример:
BEGIN
WriteLn('Hello, Sailor!');
END.
Листинг 131
Откомпилирует его любым подходящим Pascal-компилятором (например, Delphi или Free Pascal) и, загрузив откомпилированный файл в дизассемблер, пройдемся вдоль сегмента данных. Вскоре на глаза попадется следующее:
.data:00404040 unk_404040 db 0Eh ;
.data:00404041 db 48h ; H
.data:00404042 db 65h ; e
.data:00404043 db 6Ch ; l
.data:00404044 db 6Ch ; l
.data:00404045 db 6Fh ; o
.data:00404046 db 2Ch ; ,
.data:00404047 db 20h ;
.data:00404048 db 53h ; S
.data:00404049 db 61h ; a
.data:0040404A db 69h ; i
.data:0040404B db 6Ch ; l
.data:0040404C db 6Fh ; o
.data:0040404D db 72h ; r
.data:0040404E db 21h ; !
.data:0040404F db 0 ;
.data:00404050 word_404050 dw 1332h
Листинг 132
Вот она, искомая строка! (В том, что это строка – у нас никаких сомнений нет). Попробуем найти: кто на нее ссылается? В IDA Pro для этого следует нажать <ALT-I> и в поле поиска ввести смещение начала строки – "0x404041"…
Как это "ничего не найдено – Search Failed"? А что же тогда передается функции WriteLn? Может быть, это глюк IDA? Просматриваем дизассемблерный текст вручную – результат вновь нулевой.
Причина нашей неудачи в том, что в начале Pascal- строк идет байт, содержащий длину этой строки. Действительно, в дампе по смещению 0x404040
находится значение 0xE
(четырнадцать в десятичной системе исчисления). А сколько символов строке "Hello, Sailor!"? Считаем: один, два, три… четырнадцать! Вновь нажимаем <ALT-I> и ищем непосредственный операнд, равный 0x404040. И, в самом деле, находим:
.text:00401033 push 404040h
.text:00401038 push [ebp+var_4]
.text:0040103B push 0
.text:0040103D call FPC_WRITE_TEXT_SHORTSTR
.text:00401042 push [ebp+var_4]
.text:00401045 call FPC_WRITELN_END
.text:0040104A push offset loc_40102A
.text:0040104F call FPC_IOCHECK
.text:00401054 call FPC_DO_EXIT
.text:00401059 leave
.text:0040105A retn
Листинг 133
Отказывается, мало идентифицировать строку – еще, как минимум, требуется определить ее границы.
Наиболее популярны следующие типы строк: Си-строки, завершающиеся нулем; DOS-строки, завершающиеся символом "$"; Pascal-строки, предваряемые одним-, двух- или четырехбайтным полем, содержащим длину строки. Рассмотрим каждый из этих типов подробнее:
::Си-строки, так же именуемые ASCIIZ-строками (от Zero – нуль на конце) – весьма распространенный тип строк, широко использующийся в операционных системах семейств Windows и UNIX. Символ "\0" (не путать с "0") имеет специальное предназначение и трактуется по-особому – как завершитель строки. Длина ASCIIZ-строк практически ничем не ограничена – ну разве что размером адресного пространства, выделенного процессу или протяженностью сегмента. Соответственно, в Windows 9x\NT максимальный размер ASCIIZ-строки лишь немногим менее 2 гигабайт, а в Windows 3.1 и MS-DOS – около 64 килобайт. Фактическая длина ASCIIZ-строк лишь на байт длиннее исходной ASCII-строки.
Несмотря на перечисленные выше достоинства, Си-строкам присущи и некоторые недостатки. Во-первых, ASCIIZ-строка не может содержать нулевых байт, и поэтому, она не пригодна для обработки бинарных данных. Во-вторых, операции копирования, сравнения и контакции Си-строк сопряжены со значительными накладными расходами – современным процессорам не выгодно работать с отдельными байтами, – им желательно иметь дело с двойными словами. Но, увы, длина ASCIIZ-строк наперед неизвестна и ее приходится вычислять "на лету", проверяя каждый байт на символ завершения. Правда, разработчики некоторых компиляторов идут на хитрость – они завершают строку семью
нулями, - что позволяет работать с двойными словами, а это на порядок быстрее. Почему семью, а не четырьмя? Ведь в двойном слове байтов четыре! Да, верно, четыре, но подумайте, что произойдет, если последний значимый символ строки придется на первый байт двойного слова? Верно, его конец заполнят три нулевых байта, но двойное слово из-за вмешательства первого символа уже не будет равно нулю! Вот поэтому, следующему двойному слову надо предоставить еще четыре нулевых байта, тогда оно гарантировано будет равно нулю. Впрочем, семь служебных байт на каждую строку – это уже перебор!
::DOS-строки. В MS-DOS функция вывода строки воспринимает знак '$' как символ завершения, поэтому в программистских кулуарах такие строки называют "DOS-строками". Термин не совсем корректен – все остальные функции MS-DOS работают исключительно с ASCIIZ-строками! Причина выбора столь странного выбора символа-разделителя восходит к тем древнейшим временам, когда никакого графического интерфейса еще и в помине не существовало, а консольный терминал считался весьма продвинутой системой взаимодействия с пользователем. Клавиша <Enter> не могла служить завершителем строки, т.к. под час приходилось вводить в программу несколько строк сразу. Комбинации <Ctrl-Z>, или <Alt-000> так же не годились – на многих клавиатурах тех лет отсутствовали такие регистры! С другой стороны, компьютеры использовались главным образом для инженерных, а не бухгалтерских расчетов, и символ "бакса" был самым мало употребляемым символом – вот и решили использовать его для сигнализации о завершении пользователем ввода и как символ-завершитель строки. (Да, символ завершитель вводился пользователем, а не добавлялся программой, как это происходит с ASCIIZ-строками).
В настоящее время DOS- строки практически вышли из употребления и читатель вряд ли с ними столкнется…
::Pascal-строки. Pascal-строки не имеют завершающего символа, - вместо этого они предваряются специальным полем, содержащим длину этой строки. Достоинства этого подхода: – возможность хранения любых символов в строке (в том числе и нулевых байт!) и высокая скорость обработки строковых переменных. Вместо постоянной проверки каждого байта на завершающий символ, происходит лишь одно обращение к памяти – загрузка длины строки. Ну, а раз длина строки известна, можно работать не с байтами, а двойными словами – "родным" типом данных 32-разрядных процессоров. Весь вопрос в том – сколько байт отвести под поле размера. Один? Что ж, экономно, но тогда максимальная длина строки будет ограничена 255 символами, что во многих случаях оказывается явно недостаточно! Этот тип строк используют практически все Pascal-компиляторы (например, Borland Turbo Pascal, Free Pascal), поэтому-то такие строки и называют "Pascal-строками" или, если более точно, "короткими Pascal-строками".
::Delphi-строки. Осознавая очевидную смехотворность ограничения длины Pascal-строк 255 символами, разработчики Delphi расширили поле размера до двух байт, увеличив, тем самым максимально возможную длину до 65.535 символов. Хотя, такой тип строк поддерживают и другие компиляторы (тот же Free Pascal к примеру), в силу сложившейся традиции их принято именовать Delphi-строками или "Pascal-строками с двухбайтным полем размера – двухбайтными Pascal-строками".
Ограничение в шестьдесят с гаком килобайт и "ограничением" язык назвать не поворачивается. Большинство строк имеют гораздо меньшую длину, а для обработки больших массивов данных (текстовых файлов, к примеру) если куча (динамическая память) и ряд специализированных функций. Накладные же расходы (два служебных байта на каждую строковую переменную) не столь велики, чтобы их брать в расчет. Словом, Delphi-строки, сочетая в себе лучше стороны Си- и Pascal-строк (практически неограниченную длину и высокую скорость обработки соответственно), представляются самым удобным и практичным типом.
::Wide-Pascal строки. "Широкие" Pascal- строки отводят на поле размера аж четыре байта, "ограничивая" максимально возможную длину 4.294.967.295 символами или 4 гигабайтами, что даже больше того количества памяти, которое Windows NT\9x выделяют в "личное пользование" прикладному процессу! Однако за эту роскошь приходится дорого платить, отдавая каждой строке четыре "лишние" байта, три из которых в большинстве случаев будут попросту пустовать. Накладные расходы на коротких строках становятся весьма велики, поэтому, тип Wide-Pascal практически не используется.
::Комбинированные типы. Некоторые компиляторы используют комбинированный Си+Pascal тип, что позволяет им с одной стороны, достичь высокой скорости обработки строк и хранить в строках любые символы, а с другой – обеспечить совместимость с огромным количеством Си-библиотек, "заточенных" под ASCIIZ-строки. Каждая комбинированная строка принудительно завершается нулем, но этот нуль в саму строку не входит и штатные библиотеки (операторы) языка работают с ней как с Pascal-строкой. При вызове же функций Си-библиотек, компилятор передает им указатель не на истинное начало строки, а на первый символ строки.
__::Другие завершающие символы.

Рисунок 21 0х014 Осиновые типы строк
::Определение типа строк. По внешнему виду строки определить ее тип весьма затруднительно. Наличие завершающего нуля в конце строки еще не повод считать ее ASCIIZ-строкой (Pascal-компиляторы в конец строк частенько дописывают один или несколько нулей для выравнивания данных по кратным адресам), а совпадение предшествующего строке байта с ее длинной может действительно быть лишь случайным совпадением.
Грубо тип строки определяется по роду компилятора (Си или Pascal), а точно – по алгоритму обработки этой строки (т.е. анализом манипулирующего с ней кода). Рассмотрим следующий пример:
VAR
s0, s1 : String;
BEGIN
s0 :='Hello, Sailor!';
s1 :='Hello, World!';
IF s0=s1 THEN WriteLN('OK') ELSE Writeln('Woozl');
END.
Листинг 134 Пример, демонстрирующий идентификацию типа строк
Откомпилировав его компилятором Free Pascal, заглянем в сегмент данных. Там мы найдем следующую строку:
.data:00404050 aHelloWorld db 0Dh,'Hello, World!',0 ; DATA XREF: _main+2B^o
Не правда ли, она очень похожа на ASCIIZ-строку? Кому не известен используемый компилятор, тому и на ум не придет, что 0xD – это поле длины, а не символ переноса! Чтобы проверить нашу гипотезу на счет типа, перейдем по перекрестной ссылке, любезно обнаруженной IDA Pro, или самостоятельно найдем в дизассемблированном тексте непосредственный операнд 0x404050
(смещение строки).
push offset _S1 ; Передаем указатель на строку-приемник
push offset aHelloWorld ;"\rHello, World!" Передаем указатель на строку-источник
push 0FFh ; Макс. длина строки
call FPC_SHORTSTR_COPY
Так-с, указатель на строку передается функции FPC_SHORTSTR_COPY. Из прилагаемой к Free Pascal документации можно узнать, что эта функция работает с короткими Pascal - строками, стало быть, байт 0xD
никакой не символ переноса, а длина строки. А чтобы мы делали, если бы у нас отсутствовала документация на Free Pascal? (В самом же деле, невозможно раздобыть все-все-все компиляторы!). Кстати, штатная поставка IDA Pro, вплоть до версии 4.17 включительно, не содержит сигнатур FPP-библиотек и их приходится создавать самостоятельно.
В тех случаях, когда строковая функция неопознана или отсутствует ее описание, путь один – исследовать код на предмет выяснения алгоритма его работы. Ну что, засучим рукава и приступим?
FPC_SHORTSTR_COPY proc near ; CODE XREF: sub_401018+21p
arg_0 = dword ptr 8 ; Макс. длина строки
arg_4 = dword ptr 0Ch ; Исходная строка
arg_8 = dword ptr 10h ; Целевая строка
push ebp
mov ebp, esp
; Открываем кадр стека
push eax
push ecx
; Сохраняем регистры
cld
; Сбрасываем флаг направления
; т.е. заставляем команды LODS, STOS, MOVS
инкрементировать регистр-указатель
mov edi, [ebp+arg_8]
; Загружаем в регистр EDI значение аргумента arg_8 (смещение целевого буфера)
mov esi, [ebp+arg_4]
; Загружаем в регистр ESI значение аргумента arg_4 (смещение исходной строки)
xor eax, eax
; Обнуляем регистр EAX
mov ecx, [ebp+arg_0]
; Загружаем в ECX значение аргумента arg_0 (макс. допустимая длина строки)
lodsb
; Загружаем в AL первый байт исходной строки, на которую указывает регистр ESI
; и увеличиваем ESI на единицу
cmp eax, ecx
; Сравниваем первый символ строки с макс. возможной длиной строки
; Уже ясно, что первой символ строки – длина, однако, притворимся, что мы
; не знаем назначения аргумента arg_0, и продолжим анализ
jbe short loc_401168
; if (ESI[0] <= arg_0) goto loc_401168
mov eax, ecx
; Копируем в EAX значение ECX
loc_401168: ; CODE XREF: sub_401150+14j
stosb
; Записываем первый байт исходной строки в целевой буфер
; и увеличиваем EDI на единицу
cmp eax, 7
; Сравниваем длину строки с константой 0x7
jl short loc_401183
; Длина строки меньше семи байт?
; Тогда и копируем ее побайтно!
mov ecx, edi
; Загружаем в ECX значение указателя на целевой буфер, увеличенный на единицу
; (его увеличила команда STOSB при записи байта)
neg ecx
; Дополняем ECX до нуля, NEG(0xFFFF) = 1;
; ECX :=1
and ecx, 3
; Оставляем в ECX три младший бита, остальные – сбрасываем
; ECX :=1
sub eax, ecx
; Отнимаем от EAX (содержит первый байт строки) "кастрированный" ECX
repe movsb
; Копируем ECX байт из исходной строки в целевой буфер, передвигая ESI
и EDI
; В нашем случае мы копируем 1 байт
mov ecx, eax
; Теперь ECX содержит значение первого байта строки, уменьшенное на единицу
and eax, 3
; Оставляем в EAX три младший бита, остальные – сбрасываем
shr ecx, 2
; Циклическим сдвигом, делим ECX на четыре (22=4)
repe movsd
; Копируем ECX двойных байтов из ESI в EDI
; Теперь становится ясно, что ECX
– содержит длину строки, а, поскольку,
; в ECX загружается значение первого байта строки, можно с полной уверенностью
; сказать, что первый байт строки (причем именно, байт, а не слово) содержит
; длину этой строки
; Таким образом, это – короткая Pascal - строка
;
loc_401183: ; CODE XREF: sub_401150+1Cj
mov ecx, eax
; Если длина строки менее семи байт, то EAX
содержит длину строки для ее
; побайтного копирования (см. условный переход jbe short loc_401168)
; В противном случае EAX содержит остаток "хвоста" строки, который не смог
; заполнить собой последнее двойное слово
; В общем, так или иначе, в ECX загружается количество байт для копирования
repe movsb
; Копируем ECX байт из ESI в EDI
pop ecx
pop eax
; Восстанавливаем регистры
leave
; Закрываем кадр стека
retn 0Ch
FPC_SHORTSTR_COPY endp
Листинг 135
А теперь познакомимся с Си-строками, для чего нам пригодится следующий пример:
#include <stdio.h>
#include <string.h>
main()
{
char s0[]="Hello, World!";
char s1[]="Hello, Sailor!";
if (strcmp(&s0[0],&s1[0])) printf("Woozl\n"); else printf("OK\n");
}
Листинг 136
Откомпилируем его любым подходящим Си-компилятором, например, Borland C++ 5.0 (внимание – Microsoft Visual C++ для этой цели не подходит, см. "Turbo-инициализация строковых переменных"), и поищем наши строки в сегменте данных.
Долго искать не приходится – вот они:
DATA:00407074 aHelloWorld db 'Hello, World!',0 ; DATA XREF: _main+16^o
DATA:00407082 aHelloSailor db 'Hello, Sailor!',0 ; DATA XREF: _main+22^o
DATA:00407091 aWoozl db 'Woozl',0Ah,0 ; DATA XREF: _main+4F^o
DATA:00407098 aOk db 'OK',0Ah,0 ; DATA XREF: _main+5C^o
Обратите внимание: строки следуют вплотную друг к другу – каждая из них завершается символом нуля, и значение первого байта строки не совпадает с ее длиной. Несомненно, перед нами ASCIIZ-строки, однако, не мешает лишний раз убедиться в этом, тщательно проанализировав манипулирующий с ними код:
_main proc near ; DATA XREF: DATA:00407044o
var_20 = byte ptr -20h
var_10 = byte ptr -10h
push ebp
mov ebp, esp
; Открываем кадр стека
add esp, 0FFFFFFE0h
; Резервируем место для локальных переменных
mov ecx, 3
; Заносим в регистр ECX значение 0x3
lea eax, [ebp+var_10]
; Загружаем в EAX указатель на локальный буфер var_10
lea edx, [ebp+var_20]
; Загружаем в EDX указатель на локальный буфер var_20
push esi
; Сохраняем регистр ESI
; Именно сохраняем, а не передаем функции, т.к. ESI
еще не был инициализирован!
push edi
; Сохраняем регистр EDI
lea edi, [ebp+var_10]
; Загружаем в EDI указатель на локальный буфер var_10
mov esi, offset aHelloWorld ; "Hello, World!"
; IDA
распознала в непосредственном операнде смещение строки "Hello,World!"
; А если бы и не распознала – это бы сделали мы сами, основываясь на том, что:
; 1) непосредственный операнд совпадает со смещением строки
; 2) следующая команда неявно использует ESI
для косвенной адресации памяти,
; следовательно, в ESI загружается указатель
repe movsd
; Копируем ECX двойных слов из ESI в EDI
; Чему равно ECX? Оно равно 0x3
; Для перевода из двойных слов в байты умножаем 0x3 на 0x4 и получаем 0xC,
; что на байт короче копируемой строки "Hello,World!", на которую указывает ESI
movsw
; Копируем последний байт строки "Hello, World!" вместе с завершающим нулем
lea edi, [ebp+var_20]
; Загружаем в регистр EDI указатель на локальный буфер var_20
mov esi, offset aHelloSailor ; "Hello, Sailor!"
; Загружаем в регистр ESI указатель на строку "Hello, Sailor!"
mov ecx, 3
; Загружаем в ECX количество полных двойных слов в строке "Hello, Sailor!"
repe movsd
; Копируем 0x3 двойных слова
movsw
; Копируем слово
movsb
; Копируем последний завершающий байт
; // Функция сравнения строк
loc_4010AD: ; CODE XREF: _main+4Bj
mov cl, [eax]
; Загружаем в CL содержимое очередного байта строки "Hello, World!"
cmp cl, [edx]
; CL
равен содержимому очередного байта строки "Hello, Sailor!"?
jnz short loc_4010C9
; Если символы обоих строк не равны, переходим к метке loc_4010C9
test cl, cl
jz short loc_4010D8
; Регистр CL равен нулю? (В строке встретился нулевой символ?)
; если так, то прыгаем на loc_4010D8
; Теперь мы можем безошибочно определить тип строки –
; во-первых, первый байт строки содержит первый символ строки,
; а не хранит ее длину,
; во-вторых, каждый байт строки проверяется на завершающий нулевой символ
; Значит, это ASCIIZ-строки!
mov cl, [eax+1]
; Загружаем в CL следующий символ строки "Hello, World!"
cmp cl, [edx+1]
; Сравниваем его со следующим символом "Hello, Sailor!"
jnz short loc_4010C9
; Если символы не равны – закончить сравнение
add eax, 2
; Переместить указатель строки "Hello, World!" на два символа вперед
add edx, 2
; Переместить указатель строки "Hello, Sailor!" на два символа вперед
test cl, cl
jnz short loc_4010AD
; Повторять сравнение пока не будет достигнут символ-завершитель строки
loc_4010C9: ; CODE XREF: _main+35j _main+41j
jz short loc_4010D8
; см. "Идентификация if – then - else"
; // Вывод строки "Woozl"
push offset aWoozl ; format
call _printf
pop ecx
jmp short loc_4010E3
loc_4010D8: ; CODE XREF: _main+39j _main+4Dj
; // Вывод строки "OK"
push offset aOk ; format
call _printf
pop ecx
loc_4010E3: ; CODE XREF: _main+5Aj
xor eax, eax
; Функция возвращает ноль
pop edi
pop esi
; Восстанавливаем регистры
mov esp, ebp
pop ebp
; Закрываем кадр стека
retn
_main endp
Листинг 137
___строки одного типа
Turbo- инициализация строковых переменных. Не всегда, однако, различить строки так просто. Чтобы убедиться в этом, достаточно откомпилировать предыдущий пример компилятором Microsoft Visual C++, и заглянуть в полученный файл любым подходящим дизассемблером, скажем IDA Pro.
Так, переходим в секцию данных, прокручиваем ее вниз то тех пор, пока не устанет рука (а когда устанет – кирпич на Page Down!) и… Woozl! – никаких следов присутствия строк "Hello, Sailor!" и "Hello, World!". Зато обращает на себя внимание какая-то странная гряда двойных слов – смотрите:
.data:00406030 dword_406030 dd 6C6C6548h ; DATA XREF: main+6^r
.data:00406034 dword_406034 dd 57202C6Fh ; DATA XREF: main +E^r
.data:00406038 dword_406038 dd 646C726Fh ; DATA XREF: main +17^r
.data:0040603C word_40603C dw 21h ; DATA XREF: main +20^r
.data:0040603E align 4
.data:00406040 dword_406040 dd 6C6C6548h ; DATA XREF: main +2A^r
.data:00406044 dword_406044 dd 53202C6Fh ; DATA XREF: main +33^r
.data:00406048 dword_406048 dd 6F6C6961h ; DATA XREF: main +3C^r
.data:0040604C word_40604C dw 2172h ; DATA XREF: main +44^r
.data:0040604E byte_40604E db 0 ; DATA XREF: main +4F^r
Чтобы это значило? Это не указатели – они никуда не указывают, это не переменные типа int – мы не объявляли таких в программе.
Жмем <F4> для перехода в hex-режим и что мы видим? Вот они наши строки, вот они родимые:
.data:00406030 48 65 6C 6C 6F 2C 20 57-6F 72 6C 64 21 00 00 00 "Hello, World!..."
.data:00406040 48 65 6C 6C 6F 2C 20 53-61 69 6C 6F 72 21 00 00 "Hello, Sailor!.."
.data:00406050 57 6F 6F 7A 6C 0A 00 00-4F 4B 0A 00 00 00 00 00 "Woozl0..OK0....."
Хм, почему же тогда IDA Pro их посчитала двойными словами? Ответить на вопрос поможет анализ манипулирующего со строкой кода, но прежде чем приступить к его исследованию, превратим эти двойные слова в нормальную ASCIIZ - строку. (<U> для преобразования двойных слов в цепочку бестиповых байт и <A> для преобразования ее в строку). Затем подведем курсор к первой перекрестной ссылке и, нажмем <Enter>:
main proc near ; CODE XREF: start+AFp
var_20 = byte ptr -20h
var_1C = dword ptr -1Ch
var_18 = dword ptr -18h
var_14 = word ptr -14h
var_12 = byte ptr -12h
var_10 = byte ptr -10h
var_C = dword ptr -0Ch
var_8 = dword ptr -8
var_4 = word ptr -4
; Откуда взялось столько локальных переменных?!
push ebp
mov ebp, esp
; Открываем кадр стека
sub esp, 20h
; Резервируем память для локальных переменных
mov eax, dword ptr aHelloWorld ; "Hello, World!"
; Загружаем в EAX... нет, не указатель на строку "Hello, World!", а
; четыре первых байта этой строки! Теперь понятно, почему ошиблась IDA Pro
; и оригинальный код (до преобразования строки в строку) выглядел так:
; mov eax, dword_406030
; Не правда ли, не очень наглядно? И если бы, мы изучали не свою, а чужую
; программу, этот трюк дизассемблера ввел бы нас в заблуждение!
mov dword ptr [ebp+var_10], eax
; Копируем четыре первых байта строки в локальную переменную var_10
mov ecx, dword ptr aHelloWorld+4
; Загружаем байты с четвертого по восьмой строки "Hello, World!" в ECX
mov [ebp+var_C], ecx
; Копируем их в локальную переменную var_C. Но мы-то уже знаем, что это
; никакая не переменная var_C, а часть строкового буфера
mov edx, dword ptr aHelloWorld+8
; Загружаем байты с восьмого по двенадцатый строки "Hello, World!" в EDX
mov [ebp+var_8], edx
; Копируем их в локальную переменную var_8, точнее – в строковой буфер
mov ax, word ptr aHelloWorld+0Ch
; Загружаем оставшийся двух-байтовый хвост строки в AX
mov [ebp+var_4], ax
; Записываем его в локальную переменную var_4
; Итак, строка копируется по частям в следующие локальные переменные:
; int var_10; int var_0C; int var_8; short int var_4
; следовательно, на самом деле есть только одна локальная переменная –
; char var_10[14]
mov ecx, dword ptr aHelloSailor ; "Hello, Sailor!"
; Проделываем ту же самую операцию копирования над строкой "Hello, Sailor!"
mov dword ptr [ebp+var_20], ecx
mov edx, dword ptr aHelloSailor+4
mov [ebp+var_1C], edx
mov eax, dword ptr aHelloSailor+8
mov [ebp+var_18], eax
mov cx, word ptr aHelloSailor+0Ch
mov [ebp+var_14], cx
mov dl, byte_40604E
mov [ebp+var_12], dl
; Копируем строку "Hello, Sailor!" в локальную переменную char var_20[14]
lea eax, [ebp+var_20]
; Загружаем в регистр EAX указатель на локальную переменную var_20
; которая (как мы помним) содержит строку "Hello, Sailor!"
push eax ; const char *
; Передаем ее функции strcmp
; Из этого можно заключить, что var_20 – действительно хранит строку,
; а не значение типа int
lea ecx, [ebp+var_10]
; Загружаем в регистр ECX указатель на локальную переменную var_10,
; хранящую строку "Hello, World!"
push ecx ; const char *
; Передаем ее функции srtcmp
call _strcmp
add esp, 8
; strcmp("Hello, World!", "Hello, Sailor!")
test eax, eax
jz short loc_40107B
; Строки равны?
; // Вывод на экран строки "Woozl"
push offset aWoozl ; "Woozl\n"
call _printf
add esp, 4
jmp short loc_401088
; // Вывод на экран строки "OK"
loc_40107B: ; CODE XREF: sub_401000+6Aj
push offset aOk ; "OK\n"
call _printf
add esp, 4
loc_401088: ; CODE XREF: sub_401000+79j
mov esp, ebp
pop ebp
; Закрываем кадр стека
retn
main endp
Листинг 138
___о поддержке строк IDA
___"\r\n\a\v\b\t\x1B"
" !\"#$%&'()*+,-./0123456789:;<=>?"
"@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\\]^_"
"`abcdefghijklmnopqrstuvwxyz{|}~"
"АБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯ"
"абвгдежзийклмноп---¦+¦¦¬¬¦¦¬---¬"
"L+T+-+¦¦Lг¦T¦=+¦¦TTLL-г++----¦¦-"
"рстуфхцчшщъыьэюя";
___обработка строк операторами и функцими
___строки фиксированной длины
___паскль пихает строки в сегмента кода
Идентификация локальных стековых переменных
…общая масса бактерий гораздо больше, чем наша с вами суммарная масса. Бактерии - основа жизни на земле…
А.П. Капица
Локальные переменные размещаются в стеке
(так же называемым автоматической памятью) и удаляются оттуда вызываемой функцией по ее завершению. Рассмотрим подробнее: как это происходит. Сначала в стек затягиваются аргументы, передаваемые функции (если они есть), а сверху на них кладется адрес возврата, помещаемый туда инструкцией CALL вызывающей эту функцию. Получив управление, функция открывает кадр стека – сохраняет прежнее значение регистра EBP и устанавливает его равным регистру ESP (регистр указатель вершины стека). "Выше" (т.е. в более младших адресах) EBP находится свободная область стека, ниже – служебные данные (сохраненный EBP, адрес возврата) и аргументы.
Сохранность области стека, расположенная выше указателя вершины стека (регистра ESP), не гарантируется от затирания и искажения. Ее беспрепятственно могут использовать, например, обработчики аппаратных прерываний, вызываемые в непредсказуемом месте в непредсказуемое время. Да и использование стека самой функцией (для сохранения ль регистров или передачи аргументов) приведет к его искажению. Какой из этой ситуации выход? – принудительно переместить указатель вершины стека вверх, тем самым "занимая" данную область стека. Сохранность память, находящейся "ниже" ESP гарантируется (имеется ввиду – гарантируется от непреднамеренных искажений), - очередной вызов инструкции PUSH занесет данные на вершину стека, не затирая локальные переменные.
По окончании же своей работы, функция обязана вернуть ESP на прежнее место, иначе функция RET снимет со стека отнюдь не адрес возврата, а вообще не весь что (значение самой "верхней" локальной переменной) и передаст управление "в космос"…
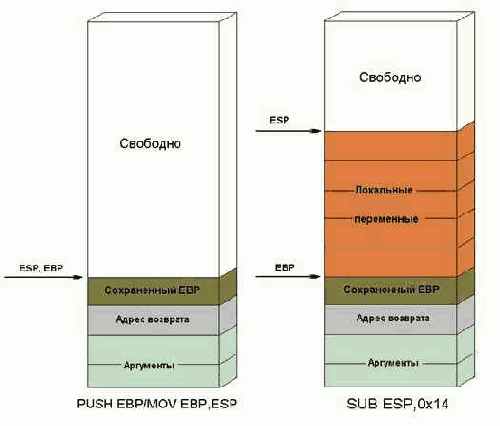
Рисунок 15 0х00E Механизм размещения локальных переменных в стеке. На левой картинке показано состояние стека на момент вызова функции.
Детали технической реализации. Существует множество вариаций реализации выделения и освобождения памяти под локальные переменные. Казалось бы, чем плохо очевидное SUB ESP,xxx на входе и ADD ESP, xxx
на выходе? А вот Borland C++ (и некоторые другие компиляторы) в стремлении отличиться ото всех остальных резервируют память не уменьшением, а увеличением ESP… да, на отрицательное число (которое по умолчанию большинством дизассемблеров отображается как очень большое положительное). Оптимизирующие компиляторы при отводе небольшого количества памяти заменяют SUB
на PUSH reg, что на несколько байт короче. Последнее создает очевидные проблемы идентификации – попробуй, разберись, то ли перед нами сохранение регистров в стеке, то ли передача аргументов, то ли резервирование памяти для локальных переменных (подробнее см. "идентификация механизма выделения памяти").
Алгоритм освобождения памяти так же неоднозначен. Помимо увеличения регистра указателя вершины стека инструкцией ADD ESP, xxx
(или в особо извращенных компиляторах его увеличения на отрицательное число), часто встречается конструкция "MOV ESP, EBP". (Мы ведь помним, что при открытии кадра стека ESP копировался в EBP, а сам EBP в процессе исполнения функции не изменялся). Наконец, память может быть освобождена инструкцией POP, выталкивающей локальные переменные одну за другой в какой ни будь ненужный регистр (понятное дело, такой способ оправдывает себя лишь на небольшом количестве локальных переменных).
|
Действие |
Варианты реализации |
||
|
Резервирование памяти |
SUB ESP, xxx |
ADD ESP,–xxx |
PUSH reg |
|
Освобождение памяти |
ADD ESP, xxx |
SUB ESP,–xxx |
POP reg |
|
MOV ESP, EBP |
Идентификация механизма выделения памяти. Выделение памяти инструкциями SUB и ADD
непротиворечиво и всегда интерпретируется однозначно. Если же выделение памяти осуществляется командой PUSH, а освобождение – POP, эта конструкция становится неотличима от простого освобождения/сохранения регистров в стеке.
Ситуация серьезно осложняется тем, что в функции присутствуют и "настоящие" команды сохранения регистров, сливаясь с командами выделения памяти. Как узнать: сколько байт резервируется для локальных переменных, и резервируются ли они вообще (может, в функции локальных переменных и нет вовсе)?
Ответить на этот вопрос позволяет поиск обращений к ячейкам памяти, лежащих "выше" регистра EBP, т.е. с отрицательными относительными смещениями. Рассмотрим два примера, приведенные на листинге 110.
PUSH EBP PUSH EBP
PUSH ECX PUSH ECX
xxx xxx
xxx MOV [EBP-4],0x666
xxx xxx
POP ECX POP ECX
POP EBP POP EBP
RET RET
Листинг 110
В левом из них никакого обращения к локальным переменным не происходит вообще, а в правом наличествует конструкция "MOV [EBP-4],0x666", копирующая значение 0x666 в локальную переменную var_4. А раз есть локальная переменная, для нее кем-то должна быть выделена память. Поскольку, инструкций SUB ESP, xxx
и ADD ESP, – xxx в теле функций не наблюдается – "подозрение" падает на PUSH ECX, т.к. сохраненное содержимое регистра ECX располагается в стеке на четыре байта "выше" EBP. В данном случае "подозревается" лишь одна команда – PUSH ECX, поскольку PUSH EBP на роль "резерватора" не тянет, но как быть, если "подозреваемых" несколько?
Определить количество выделенной памяти можно по смещению самой "высокой" локальной переменной, которую удается обнаружить в теле функции. То есть, отыскав все выражения типа [EBP-xxx] выберем наибольшее смещение "xxx" – в общем случае оно равно количеству байт выделенной под локальные переменные памяти. В частностях же встречаются объявленные, но не используемые локальные переменные. Им выделяется память (хотя оптимизирующие компиляторы просто выкидывают такие переменные за ненадобностью), но ни одного обращения к ним не происходит, и описанный выше алгоритм подсчета объема резервируемой памяти дает заниженный результат.
Впрочем, эта ошибка никак не сказывается на результатах анализа программы.
Инициализация локальных переменных. Существует два способа инициализации локальных переменных: присвоение необходимого значение инструкцией MOV (например, "MOV [EBP-04], 0x666") и непосредственное заталкивания значения в стек инструкцией PUSH
( например, PUSH 0x777). Последнее позволяет выгодно комбинировать выделение памяти под локальные переменные с их инициализацией (разумеется, только в том случае, если этих переменных немного).
Популярные компиляторы в подавляющем большинстве случаев выполняют операцию инициализации с помощью MOV, а PUSH
более характер для ассемблерных извращений, встречающихся, например, в защитах в попытке сбить с толку хакера. Ну, если такой примем и собьет хакера, то только начинающего.
Размещение массивов и структур. Массивы и структуры размещаются в стеке последовательно в смежных ячейках памяти, при этом меньший индекс массива (элемент структуры) лежит по меньшему адресу, но, - внимание, - адресуется большим модулем смещения относительно регистра указателя кадра стека. Это не покажется удивительными, если вспомнить, что локальные переменные адресуются отрицательными смещениями, следовательно, [EBP-0x4] > [EBP-0x10].
Путаницу усиливает то обстоятельство, что, давая локальными переменным имена, IDA опускает знак минус. Поэтому, из двух имен, скажем, var_4 и var_10, по меньшему адресу лежит то, чей индекс больше! Если var_4 и var_10 – это два конца массива, то с непривычки возникает непроизвольное желание поместить var_4 в голову, а var_10 в "хвост" массива, хотя на самом деле все наоборот!
Выравнивание в стеке. В некоторых случаях элементы структуры, массива и даже просто отдельные переменные требуется располагать по кратным адресам. Но ведь значение указателя вершины заранее не определено и неизвестно компилятору. Как же он, не зная фактического значения указателя, сможет выполнить это требование? Да очень просто – возьмет и откинет младшие биты ESP!
Легко доказать, если младший бит равен нулю, число – четное. Чтобы быть уверенным, что значение указателя вершины стека делится на два без остатка, достаточно лишь сбросить его младший бит. Сбросив два бита, мы получим значение заведомо кратное четырем, три – восьми и т.д.
Сброс битов в подавляющем большинстве случаев осуществляется инструкцией AND. Например, "AND ESP, FFFFFFF0" дает ESP кратным шестнадцати. Как было получено это значение? Переводим "0xFFFFFFF0" в двоичный вид, получаем – "11111111 11111111 11111111 11110000". Видите четыре нуля на конце? Значит, четыре младших бита любого числа будут маскированы, и оно разделиться без остатка на 24 = 16.
___Как IDA идентифицирует локальные переменные.
Хотя с локальными переменными мы уже неоднократно встречались при изучении прошлых примеров, не помешает это сделать это еще один раз:
#include <stdio.h>
#include <stdlib.h>
int MyFunc(int a, int b)
{
int c; // Локальная переменная типа int
char x[50] // Массив (демонстрирует схему размещения массивов в памяти_
c=a+b; // Заносим в 'c' сумму аргументов 'a
и 'b'
ltoa(c,&x[0],0x10) ; // Переводим сумму 'a' и 'b' в строку
printf("%x == %s == ",c,&x[0]); // Выводим строку на экран
return c;
}
main()
{
int a=0x666; // Объявляем локальные переменные 'a' и 'b' для того, чтобы
int b=0x777; // продемонстрировать механизм их иницилизации компилятором
int c[1]; // Такие извращения понадобовились для того, чтобы запретит
// отимизирующему компилятору помещать локальную переменную
// в регистр (см. "Идентификация регистровых переменных")
// Т.к. функции printf
передается указатель на 'c', а
// указатель на регистр быть передан не может, компилятор
// вынужен оставить переменную в памяти
c[0]=MyFunc(a,b);
printf("%x\n",&c[0]);
return 0;
}
Листинг 111 Демонстрация идентификации локальных переменных
Результат компиляции компилятора Microsoft Visual C++6.0 с настройками по умолчанию должен выглядеть так:
MyFunc proc near ; CODE XREF: main+1Cp
var_38 = byte ptr -38h
var_4 = dword ptr –4
; Локальные переменные располагаются по отрицательному смещению относительно EBP,
; а аргументы функции – по положительному.
; Заметьте также, чем "выше" расположена переменная, тем больше модуль ее смещения
arg_0 = dword ptr 8
arg_4 = dword ptr 0Ch
push ebp
mov ebp, esp
; Открываем кадр стека
sub esp, 38h
; Уменьшаем значение ESP на 0x38, резервируя 0x38 байт под локальные переменные
mov eax, [ebp+arg_0]
; загружаем а EAX значение аргумента arg_0
; О том, что это аргумент, а не нечто иное, говорит его положительное
; смещение относительно регистра EBP
add eax, [ebp+arg_4]
; складываем EAX со значением аргумента arg_0
mov [ebp+var_4], eax
; А вот и первая локальная переменная!
; На то, что это именно локальная переменная, указывает ее отрицательное
; смещение относительно регистра EBP. Почему отрицательное? А посмотрите,
; как IDA определила "var_4"
; По моему личному мнению, было бы намного нагляднее если бы отрицательные
; смещения локальных переменных подчеркивались более явно.
push 10h ; int
; Передаем функции ltoa значение 0x10 (тип системы исчисления)
lea ecx, [ebp+var_38]
; Загружаем в ECX указатель на локальную переменную var_38
; Что это за переменная? Прокрутим экран дизассемблера немного вверх,
; там где содержится описание локальных переменных, распознанных IDA
; var_38 = byte ptr -38h
; var_4 = dword ptr –4
;
; Ближайшая нижняя переменная имеет смещение –4, а var_38, соответственно, -38
; Вычитая из первого последнее получаем размер var_38
; Он, как нетрудно подсчитать, будет равен 0x34
; С другой стороны, известно, что функция ltoa
ожидает указатель на char*
; Таким образом, в комментарии к var_38 можно записать "char s[0x34]"
; Это делается так: в меню "Edit" открываем подменю "Functions", а в нем –
; пункт "Stack variables" или нажимаем "горячую" комбинацию <Ctrl-K>
; Открывается окно с перечнем всех распознанных локальных переменных.
; Подводим курсор к "var_34" и нажимаем <;> для ввода повторяемого комментария
; и пишем нечто вроде "char s[0x34]". Теперь <Ctrl-Enter> для завершения ввода
; и <Esc> для закрытия окна локальных переменных.
; Все! Теперь возле всех обращений к var_34 появляется введенный нами
; комментарий
;
push ecx ; char *
; Передаем функции ltoa указатель на локальный буфер var_38
mov edx, [ebp+var_4]
; Загружаем в EDX значение локальной переменной var_4
push edx ; __int32
; Передаем значение локальной переменной var_38 функции ltoa
; На основании прототипа этой функции IDA
уже определила тип переменной – int
; Вновь нажмем <Ctrl-K> и прокомментируем var_4
call __ltoa
add esp, 0Ch
; Переводим содержимое var_4 в шестнадцатеричную систему исчисления,
; записанную в строковой форме, возвращая ответ в локальном буфере var_38
lea eax, [ebp+var_38] ; char s[0x34]
; Загружаем в EAX указатель на локальный буфер var_34
push eax
; Передаем указатель на var_34 функции printf для вывода содержимого на экран
mov ecx, [ebp+var_4]
; Копируем в ECX значение локальной переменной var_4
push ecx
; Передаем функции printf значение локальной переменной var_4
push offset aXS ; "%x == %s == "
call _printf
add esp, 0Ch
mov eax, [ebp+var_4]
; Возвращаем в EAX значение локальной переменной var_4
mov esp, ebp
; Освобождаем память, занятую локальными переменными
pop ebp
; Восстанавливаем прежнее значение EBP
retn
MyFunc endp
main proc near ; CODE XREF: start+AFp
var_C = dword ptr -0Ch
var_8 = dword ptr -8
var_4 = dword ptr –4
push ebp
mov ebp, esp
; Открываем кадр стека
sub esp, 0Ch
; Резервируем 0xC байт памяти для локальных переменных
mov [ebp+var_4], 666h
; Инициализируем локальную переменную var_4, присваивая ей значение 0x666
mov [ebp+var_8], 777h
; Инициализируем локальную переменную var_8, присваивая ей значение 0x777
; Смотрите: локальные переменные расположены в памяти в обратном порядке
; их обращения к ним! Не объявления, а именно обращения!
; Вообще-то, порядок расположения не всегда бывает именно таким, - это
; зависит от компилятора, поэтому, полагаться на него никогда не стоит!
mov eax, [ebp+var_8]
; Копируем в регистр EAX значение локальной переменной var_8
push eax
; Передаем функции MyFunc значение локальной переменной var_8
mov ecx, [ebp+var_4]
; Копируем в ECX значение локальной переменной var_4
push ecx
; Передаем MyFunc значение локальной переменной var_4
call MyFunc
add esp, 8
; Вызываем MyFunc
mov [ebp+var_C], eax
; Копируем возращенное функцией значение в локальную переменную var_C
lea edx, [ebp+var_C]
; Загружаем в EDX указатель на локальную переменную var_C
push edx
; Передаем функции printf указатель на локальную переменную var_C
push offset asc_406040 ; "%x\n"
call _printf
add esp, 8
xor eax, eax
; Возвращаем нуль
mov esp, ebp
; Освобожаем память, занятую локальными переменными
pop ebp
; Закрываем кадр стека
retn
main endp
Листинг 112
Не очень сложно, правда? Что ж, тогда рассмотрим результат компиляции этого примера компилятором Borland C++ 5.0 – это будет немного труднее!
MyFunc proc near ; CODE XREF: _main+14p
var_34 = byte ptr -34h
; Смотрите, - только одна локальная переменная! А ведь мы объявляли целых три...
; Куда же они подевались?! Это хитрый компилятор поместил их в регистры, а не стек
; для более быстрого к ним обращения
; (подробнее см. "Идентификация регистровых и временных переменных")
push ebp
mov ebp, esp
; Открываем кадр стека
add esp, 0FFFFFFCC
; Резервируем... нажимаем <-> в IDA, превращая число в знаковое, получаем "–34"
; Резервируем 0x34 байта под локальные переменные
; Обратите внимание: на этот раз выделение памяти осуществляется не SUB, а ADD!
push ebx
; Сохраняем EBX в стеке или выделяем память локальным переменным?
; Поскольку память уже выделена инструкцией ADD, то в данном случае
; команда PUSH действительно сохраняет регистр в стеке
lea ebx, [edx+eax]
; А этим хитрым сложением мы получаем сумму EDX
и EAX
; Поскольку, EAX и EDX не инициализировались явно, очевидно, через них
; были переданы аргументы (см. "Идентификация аргументов функций")
push 10h
; Передаем функции ltoa выбранную систему исчисления
lea eax, [ebp+var_34]
; Загружаем в EAX указатель на локальный буфер var_34
push eax
; Передаем функции ltoa указатель на буфер для записи результата
push ebx
; Передаем сумму (не указатель!) двух аргументов функции MyFunc
call _ltoa
add esp, 0Ch
lea edx, [ebp+var_34]
; Загружаем в EDX указатель на локальный буфер var_34
push edx
; Передаем функции printf указатель на локальный буфер var_34, содержащий
; результат преобразования суммы аргументов MyFunc
в строку
push ebx
; Передаем сумму аргументов функции MyFunc
push offset aXS ; format
call _printf
add esp, 0Ch
mov eax, ebx
; Возвращаем сумму аргументов в EAX
pop ebx
; Выталкиваем EBX из стека, восстанавливая его прежнее значение
mov esp, ebp
; Освобождаем память, занятную локальными переменными
pop ebp
; Закрываем кадр стека
retn
MyFunc endp
; int __cdecl main(int argc,const char **argv,const char *envp)
_main proc near ; DATA XREF: DATA:00407044o
var_4 = dword ptr –4
; IDA
распознала по крайней мере одну локальную переменную –
; возьмем это себе на заметку.
argc = dword ptr 8
argv = dword ptr 0Ch
envp = dword ptr 10h
push ebp
mov ebp, esp
; Открываем кадр стека
push ecx
push ebx
push esi
; Сохраняем регистры в стеке
mov esi, 777h
; Помещаем в регистр ESI значение 0x777
mov ebx, 666h
; Помещаем в регистр EBX значение 0x666
mov edx, esi
mov eax, ebx
; Передаем функции MyFunc аргументы через регистры
call MyFunc
; Вызываем MyFunc
mov [ebp+var_4], eax
; Копируем результат, возвращенный функцией MyFunc
в локальную переменную var_4
; Стоп! Какую такую локальную переменную?! А кто под нее выделял память?!
; Не иначе – как из одна команд PUSH. Только вот какая?
; Смотрим на смещение переменной – она лежит на четыре байта выше EBP, а эта
; область памяти занята содержимым регистра, сохраненного первым PUSH,
; следующим за открытием кадра стека.
; (Соответственно, второй PUSH кладет значение регистра по смещению –8 и т.д.)
; А первой была команда PUSH ECX, - следовательно, это не никакое не сохранение
; регистра в стеке, а резервирование памяти под локальную переменную
; Поскольку, обращений к локальным переменным var_8 и var_C не наблюдается,
; команды PUSH EBX и PUSH ESI, по-видимому, действительно сохраняют регистры
lea ecx, [ebp+var_4]
; Загружаем в ECX указатель на локальную переменную var_4
push ecx
; Передаем указатель на var_4 функции printf
push offset asc_407081 ; format
call _printf
add esp, 8
xor eax, eax
; Возвращаем в EAX нуль
pop esi
pop ebx
; Восстанавливаем значения регистров ESI
и EBX
pop ecx
; Освобождаем память, выделенную локальной переменной var_4
pop ebp
; Закрываем кадр стека
retn
_main endp
Листинг 113
__дописать модификация локальной переменной из другого потока
FPO - Frame Pointer Omission Традиционно для адресации локальных переменных используется регистр EBP. Учитывая, что регистров общего назначения всего семь, "насовсем" отдавать один из них локальным переменным очень не хочется. Нельзя найти какое-нибудь другое, более элегантное решение?
Хорошенько подумав, мы придем к выводу, что отдельный регистр для адресации локальных переменных вообще не нужен, - достаточно (не без ухищрений, правда) одного лишь ESP – указателя стека.
Единственная проблема – плавающий кадр стека. Пусть после выделения памяти под локальные переменные ESP указывает на вершину выделенного региона. Тогда, переменная buff
(см. рис 17) окажется расположена по адресу ESP+0xC. Но стоит занести что-нибудь в стек (аргумент вызываемой функции или регистр на временное сохранение), как кадр "уползет" и buff окажется расположен уже не по ESP+0xC, а – ESP+0x10!
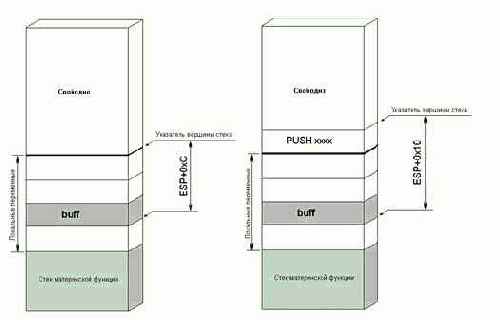
Рисунок 17 0х004 Адресация локальных переменных через регистр ESP приводит к образованию плавающего кадра стека
Современные компиляторы умеют адресовать локальные переменные через ESP, динамически отслеживая его значение (правда, при условии, что в теле функции нет хитрых ассемблерных вставок, изменяющих значение ESP непредсказуемым образом).
Это чрезвычайно затрудняет изучение кода, поскольку теперь невозможно, ткнув пальцем в произвольное место кода, определить к какой именно локальной переменной происходит обращение, - приходится "прочесывать" всю функцию целиком, внимательно следя за значением ESP (и нередко впадая при этом в грубые ошибки, пускающие всю работу насмарку).
К счастью, дизассемблер IDA умеет обращаться с такими переменными, но хакер тем и отличается от простого смертного, что никогда всецело не полагается на автоматику, а сам
стремиться понять, как это работает!
Рассмотрим наш старый добрый simple.c, откомпилировав его с ключом "/O2" – оптимизация по скорости. Тогда компилятор будет стремиться использовать все регистры и адресовать локальные переменные через ESP, что нам и надо.
>cl sample.c /O2
00401000: 83 EC 64 sub esp,64h
Выделяем память для локальных переменных. Обратите внимание – теперь уже нет команд PUSH EBP\MOV EBP,ESP!
00401003: A0 00 69 40 00 mov al,[00406900] ; mov al,0
00401008: 53 push ebx
00401009: 55 push ebp
0040100A: 56 push esi
0040100B: 57 push edi
Сохраняем регистры
0040100C: 88 44 24 10 mov byte ptr [esp+10h],al
Заносим в локальную переменную [ESP+0x10] (назовем ее buff) значение ноль
00401010: B9 18 00 00 00 mov ecx,18h
00401015: 33 C0 xor eax,eax
00401017: 8D 7C 24 11 lea edi,[esp+11h]
Устанавливаем EDI на локальную переменную [ESP+0x11] (неинициализированный хвост buff)
0040101B: 68 60 60 40 00 push 406060h ; "Enter password"
Заносим в стек смещение строки "Enter password". Внимание! Регистр ESP теперь уползает на 4 байта "вверх"
00401020: F3 AB rep stos dword ptr [edi]
00401022: 66 AB stos word ptr [edi]
00401024: 33 ED xor ebp,ebp
00401026: AA stos byte ptr [edi]
Обнуляем буфер
00401027: E8 F4 01 00 00 call 00401220
Вывод строки "Enter password" на экран. Внимание!
Аргументы все еще не вытолкнуты из стека!
0040102C: 68 70 60 40 00 push 406070h
Заносим в стек смещение указателя на указатель stdin. Внимание! ESP еще уползает на четыре байта вверх.
00401031: 8D 4C 24 18 lea ecx,[esp+18h]
Загружаем в ECX указатель на переменную [ESP+0x18]. Еще один буфер? Да как бы не так! Это уже знакомая нам переменная [ESP+0x10], но "сменившая облик" за счет изменения ESP. Если из 0x18
вычесть 8 байт на которые уполз ESP – получим 0x10, - т.е. нашу старую знакомую – [ESP+0x10]!
Крохотную процедуру из десятка строк "проштудировать" несложно, но вот на программе в миллион строк можно и лапти скинуть! Или… воспользоваться IDA. Посмотрите на результат ее работы:
.text:00401000 main proc near ; CODE XREF: start+AFvp
.text:00401000
.text:00401000 var_64 = byte ptr -64h
.text:00401000 var_63 = byte ptr -63h
IDA обнаружила две локальные переменные, расположенные относительно кадра стека по смещениям 63 и 64, оттого и названных соответственно: var_64 и var_63.
.text:00401000 sub esp, 64h
.text:00401003 mov al, byte_0_406900
.text:00401008 push ebx
.text:00401009 push ebp
.text:0040100A push esi
.text:0040100B push edi
.text:0040100C mov [esp+74h+var_64], al
IDA автоматически подставляет имя локальной переменной к ее смещению в кадре стека
.text:00401010 mov ecx, 18h
.text:00401015 xor eax, eax
.text:00401017 lea edi, [esp+74h+var_63]
Конечно, IDA не смогла распознать инициализацию первого байта буфера и ошибочно приняла его за отдельную переменную, – но это не ее вина, а компилятора! Разобраться – сколько переменных тут в действительности может только человек!
.text:0040101B push offset aEnterPassword ; "Enter password:"
.text:00401020 repe stosd
.text:00401022 stosw
.text:00401024 xor ebp, ebp
.text:00401026 stosb
.text:00401027 call sub_0_401220
.text:0040102C push offset off_0_406070
.text:00401031 lea ecx, [esp+7Ch+var_64]
Обратите внимание – IDA правильно распознала обращение к нашей переменной, хотя ее смещение – 0x7C – отличается от 0x74!
Идентификация математических операторов
"…если вы обессилены, то не удивительно, что вся ваша жизнь -- не развлечение. У вас… так много вычислений, расчетов, которые необходимо сделать в вашей жизни, что она просто не может быть развлечением."
Ошо "Пустая Лодка"
Беседы по высказываниям Чжуан Цзы
Идентификация оператора "+". В общем случае оператор "+" транслируется либо в машинную инструкцию ADD, "перемалывающую" целочисленные операнды, либо в инструкцию FADDx, обрабатывающую вещественные значения. Оптимизирующие компиляторы могут заменять "ADD xxx, 1" более компактной командой "INC xxx", а конструкцию "c = a + b + const" транслировать в машинную инструкцию "LEA c, [a + b + const]". Такой трюк позволяет одним махом складывать несколько переменных, возвратив полученную сумму в любом регистре общего назначения, – не обязательно в левом слагаемом как это требует мнемоника команды ADD. Однако, "LEA" не может быть непосредственно декомпилирована в оператор "+", поскольку она используется не только для оптимизированного сложения (что, в общем-то, побочный продукт ее деятельности), но и по своему непосредственному назначению – вычислению эффективного смещения. (подробнее об этом см. "Идентификация констант и смещений", "Идентификация типов"). Рассмотрим следующий пример:
main()
{
int a, b,c;
c = a + b;
printf("%x\n",c);
c=c+1;
printf("%x\n",c);
}
Листинг 204 Демонстрация оператора "+"
Результат его компиляции компилятором Microsoft Visual C++ 6.0 с настройками по умолчанию должен выглядеть так:
main proc near ; CODE XREF: start+AFp
var_c = dword ptr -0Ch
var_b = dword ptr -8
var_a = dword ptr -4
push ebp
mov ebp, esp
; Открываем кадр стека
sub esp, 0Ch
; Резервируем память для локальных переменных
mov eax, [ebp+var_a]
; Загружаем в EAX значение переменной var_a
add eax, [ebp+var_b]
; Складываем EAX со значением переменной var_b
и записываем результат в EAX
mov [ebp+var_c], eax
; Копируем сумму var_a
и var_b в переменную var_c, следовательно:
; var_c = var_a + var_b
mov ecx, [ebp+var_c]
push ecx
push offset asc_406030 ; "%x\n"
call _printf
add esp, 8
; printf("%x\n", var_c)
mov edx, [ebp+var_c]
; Загружаем в EDX значение переменной var_c
add edx, 1
; Складываем EDX со значением 0х1, записывая результат в EDX
mov [ebp+var_c], edx
; Обновляем var_c
; var_c = var_c +1
mov eax, [ebp+var_c]
push eax
push offset asc_406034 ; "%x\n"
call _printf
add esp, 8
; printf("%\n",var_c)
mov esp, ebp
pop ebp
; Закрываем кадр стека
retn
main endp
Листинг 205
А теперь посмотрим, как будет выглядеть тот же самый пример, скомпилированный с ключом "/Ox" (максимальная оптимизация):
main proc near ; CODE XREF: start+AFp
push ecx
; Резервируем место для одной локальной переменной
; (компилятор посчитал, что три переменные можно ужать в одну и это дейст. так)
mov eax, [esp+0]
; Загружаем в EAX значение переменной var_a
mov ecx, [esp+0]
; Загружаем в EAX значение переменной var_b
; (т.к .переменная не инициализирована загружать можно откуда угодно)
push esi
; Сохраняем регистр ESI в стеке
lea esi, [ecx+eax]
; Используем LEA для быстрого сложения ECX и EAX с последующей записью суммы
; в регистр ESI
; "Быстрое сложение" следует понимать не в смысле, что команда LEA выполняется
; быстрее чем ADD, - количество тактов той и другой одинаково, но LEA
; позволяет избавиться от создания временной переменной для сохранения
; промежуточного результата сложения, сразу направляя результат в ESI
; Таким образом, эта команда декомпилируется как
; reg_ESI = var_a + var_b
push esi
push offset asc_406030 ; "%x\n"
call _printf
; printf("%x\n", reg_ESI)
inc esi
; Увеличиваем ESI на единицу
; reg_ESI = reg_ESI + 1
push esi
push offset asc_406034 ; "%x\n"
call _printf
add esp, 10h
; printf("%x\n", reg_ESI)
pop esi
pop ecx
retn
main endp
Листинг 206
Остальные компиляторы (Borland C++, WATCOM C) генерируют приблизительно идентичный код, поэтому, приводить результаты бессмысленно – никаких новых "изюминок" они в себе не несут.
Идентификация оператора "–". В общем случае оператор "– " транслируется либо в машинную инструкцию SUB
(если операнды – целочисленные значения), либо в инструкцию FSUBx (если операнды – вещественные значения). Оптимизирующие компиляторы могут заменять "SUB xxx, 1" более компактной командой "DEC xxx", а конструкцию "SUB a, const" транслировать в "ADD a, -const", которая ничуть не компактнее и ни сколь не быстрей (и та, и другая укладываться в один так), однако, хозяин (компилятор) – барин. Покажем это на следующем примере:
main()
{
int a,b,c;
c = a - b;
printf("%x\n",c);
c = c - 10;
printf("%x\n",c);
}
Листинг 207 Демонстрация идентификации оператора "-"
Не оптимизированный вариант будет выглядеть приблизительно так:
main proc near ; CODE XREF: start+AFp
var_c = dword ptr -0Ch
var_b = dword ptr -8
var_a = dword ptr -4
push ebp
mov ebp, esp
; Открываем кадр стека
sub esp, 0Ch
; Резервируем память под локальные переменные
mov eax, [ebp+var_a]
; Загружаем в EAX значение переменной var_a
sub eax, [ebp+var_b]
; Вычитаем из var_a
значением переменной var_b, записывая результат в EAX
mov [ebp+var_c], eax
; Записываем в var_c
разность var_a и var_b
; var_c = var_a – var_b
mov ecx, [ebp+var_c]
push ecx
push offset asc_406030 ; "%x\n"
call _printf
add esp, 8
; printf("%x\n", var_c)
mov edx, [ebp+var_c]
; Загружаем в EDX значение переменной var_c
sub edx, 0Ah
; Вычитаем из var_c
значение 0xA, записывая результат в EDX
mov [ebp+var_c], edx
; Обновляем var_c
; var_c = var_c – 0xA
mov eax, [ebp+var_c]
push eax
push offset asc_406034 ; "%x\n"
call _printf
add esp, 8
; printf("%x\n",var_c)
mov esp, ebp
pop ebp
; Закрываем кадр стека
retn
main endp
Листинг 208
А теперь рассмотрим оптимизированный вариант того же примера:
main proc near ; CODE XREF: start+AFp
push ecx
; Резервируем место для локальной переменной var_a
mov eax, [esp+var_a]
; Загружаем в EAX значение локальной переменной var_a
push esi
; Резервируем место для локальной переменной var_b
mov esi, [esp+var_b]
; Загружаем в ESI значение переменной var_b
sub esi, eax
; Вычитаем из var_a
значение var_b, записывая результат в ESI
push esi
push offset asc_406030 ; "%x\n"
call _printf
; printf("%x\n", var_a – var_b)
add esi, 0FFFFFFF6h
; Добавляем
к ESI (разности var_a и
var_b) значение 0хFFFFFFF6
; Поскольку, 0xFFFFFFF6 == -0xA, данная строка кода выглядит так:
; ESI = (var_a – var_b) + (– 0xA) = (var_a – var_b) – 0xA
push esi
push offset asc_406034 ; "%x\n"
call _printf
add esp, 10h
; printf("%x\n", var_a – var_b – 0xA)
pop esi
pop ecx
; Закрываем кадр стека
retn
main endp
Листинг 209
Остальные компиляторы (Borland, WATCOM) генерируют практически идентичный код, поэтому здесь не рассматриваются.
Идентификация оператора "/". В общем случае оператор "/" транслируется либо в машинную инструкцию "DIV" (беззнаковое целочисленное деление), либо в "IDIV" (целочисленное деление со знаком), либо в "FDIVx" (вещественное деление).
Если делитель кратен степени двойки, то "DIV" заменяется на более быстродействующую инструкцию битового сдвига вправо "SHR a, N", где a – делимое, а N – показатель степени с основанием два.
Несколько сложнее происходит быстрое деление знаковых чисел. Совершенно недостаточно выполнить арифметический сдвиг вправо (команда арифметического сдвига вправо SAR
заполняет старшие биты с учетом знака числа), ведь если модуль делимого меньше модуля делителя, то арифметический сдвиг вправо сбросит все значащие биты в "битовую корзину", в результате чего получиться 0xFFFFFFFF, т.е. –1, в то время как правильный ответ – ноль. Вообще же, деление знаковых чисел арифметическим сдвигом вправо дает округление в большую сторону, что совсем не входит в наши планы. Для округления знаковых чисел в меньшую сторону необходимо перед выполнением сдвига добавить к делимому число , где N
– количество битов, на которые сдвигается число при делении. Легко видеть, что это приводит к увеличению всех сдвигаемых битов на единицу и переносу в старший разряд, если хотя бы один из них не равен нулю.
Следует отметить: деление очень медленная операция, гораздо более медленная чем умножение (выполнение DIV
может занять свыше 40 тактов, в то время как MUL обычно укладываться в 4), поэтому, продвинутые оптимизирующие компиляторы заменяют деление умножением. Существует множество формул подобных преобразований, вот, например, она (самая популярная из них):
, где N – разрядность числа. Выходит, грань между умножением и делением очень тока, а их идентификация довольно сложна. Рассмотрим следующий пример:
main()
{
int a;
printf("%x %x\n",a / 32, a / 10);
}
Листинг 210 Идентификация оператора "/"
Результат его компиляции компилятором Microsoft Visual C++ с настройками по умолчанию должен выглядеть так:
main proc near ; CODE XREF: start+AFp
var_a = dword ptr -4
push ebp
mov ebp, esp
; Открываем кадр стека
push ecx
; Резервируем память для локальной переменной
mov eax, [ebp+var_a]
; Копируем в EAX значение переменной var_a
cdq
; Расширяем EAX до четверного слова EDX:EAX
mov ecx, 0Ah
; Заносим в ECX значение 0xA
idiv ecx
; Делим (учитывая знак) EDX:EAX
на 0xA, занося частное в EAX
; EAX = var_a / 0xA
push eax
; Передаем результат вычислений функции printf
mov eax, [ebp+var_a]
; Загружаем в EAX значение var_a
cdq
; Расширяем EAX до четверного слова EDX:EAX
and edx, 1Fh
; Выделяем пять младших бит EDX
add eax, edx
; Складываем знак числа для выполнения округления отрицательных значений
; в меньшую сторону
sar eax, 5
; Арифметический сдвиг вправо на 5 позиций
; эквивалентен делению числа на 25 = 32
; Таким образом, последние четыре инструкции расшифровываются как:
; EAX = var_a / 32
; Обратите внимание: даже при выключенном режиме оптимизации компилятор
; оптимизировал деление
push eax
push offset aXX ; "%x %x\n"
call _printf
add esp, 0Ch
; printf("%x %x\n", var_a / 0xA, var_a / 32)
mov esp, ebp
pop ebp
; Закрываем кадр стека
retn
main endp
Листинг 211
А теперь, засучив рукава и глотнув пустырника (или валерьянки) рассмотрим оптимизированный вариант того же примера:
main proc near ; CODE XREF: start+AFp
push ecx
; Резервируем память для локальной переменной var_a
mov ecx, [esp+var_a]
; Загружаем в ECX значение переменной var_a
mov eax, 66666667h
; Так, что это за зверское число?!
; В исходном коде ничего подобного и близко не было!
imul ecx
; Умножаем это зверское число на переменную var_a
; Обратите внимание: именно умножаем, а не делим.
; Однако притворимся на время, что у нас нет исходного кода примера, потому
; ничего странного в операции умножения мы не видим
sar edx, 2
; Выполняем арифметический сдвиг всех битов EDX
на две позиции вправо, что
; в первом приближении эквивалентно его делению на 4
; Однако ведь в EDX находятся старшее двойное слово результата умножения!
; Поэтому, три предыдущих команды фактически расшифровываются так:
; EDX = (66666667h * var_a) >> (32 + 2) = (66666667h * var_a) / 0x400000000
;
; Понюхайте эту строчку – не пахнет ли паленым? Как так не пахнет?! Смотрите:
; (66666667h * var_a) / 0x400000000 = var_a * 66666667h / 0x400000000 =
; = var_a * 0,10000000003492459654808044433594
; Заменяя по всем правилам математики умножение на деление и одновременно
; выполняя округление до меньшего целого получаем:
; var_a * 0,1000000000 = var_a * (1/0,1000000000) = var_a/10
;
; Согласитесь, от такого преобразования код стал намного понятнее!
; Как можно распознать такую ситуацию в чужой программе, исходный текст которой
; неизвестен? Да очень просто – если встречается умножение, а следом за ним
; сдвиг вправо, обозначающий деление, то каждый нормальный математик сочтет
; своим долгом такую конструкцию сократить, по методике показанной выше!
mov eax, edx
; Копируем полученное частное в EAX
shr eax, 1Fh
; Сдвигаем на 31 позицию вправо
add edx, eax
; Складываем: EDX = EDX + (EDX >> 31)
; Чтобы это значило? Нетрудно понять, что после сдвига EDX
на 31 бит вправо
; в нем останется лишь знаковый бит числа
; Тогда – если число отрицательно, мы добавляем к результату деления один,
; округляя его в меньшую сторону. Таким образом, весь этот хитрый код
; обозначает ни что иное как тривиальную операцию знакового деления:
; EDX = var_a / 10
; Не слишком ли много кода для одного лишь деления? Конечно, программа
; здорово "распухает", зато весь этот код выполняется всего лишь за 9 тактов,
; в то время как в не оптимизированном варианте аж за 28!
; /* Измерения проводились на процессоре CLERION
с ядром P6, на других
; процессорах количество тактов может отличается */
; Т.е. оптимизация дала более чем трехкратный выигрыш, браво Microsoft!
mov eax, ecx
; Вспомним: что находится в ECX? Ох, уж эта наша дырявая память, более дырявая
; чем дуршлаг без дна… Прокручиваем экран дизассемблера вверх. Ага, в ECX
; последний раз разгружалось значение переменной var_a
push edx
; Передаем функции printf результат деления var_a
на 10
cdq
; Расширяем EAX (var_a) до четверного слова EDX:EAX
and edx, 1Fh
; Выбираем младшие 5 бит регистра EDX, содержащие знак var_a
add eax, edx
; Округляем до меньшего
sar eax, 5
; Арифметический сдвиг на 5 эквивалентен делению var_a на 32
push eax
push offset aXX ; "%x %x\n"
call _printf
add esp, 10h
; printf("%x %x\n", var_a / 10, var_a / 32)
retn
main endp
Листинг 212
Ну, а другие компиляторы, насколько они продвинуты в плане оптимизации? Увы, ни Borland, ни WATCOM не умеют заменять деление более быстрым умножением для чисел отличных от степени двойки. В подтверждении тому рассмотрим результат компиляции того же примера компилятором Borland C++:
_main proc near ; DATA XREF: DATA:00407044o
push ebp
mov ebp, esp
; Открываем кадр стека
push ebx
; Сохраняем EBX
mov eax, ecx
; Копируем в EAX содержимое неинициализированной регистровой переменной ECX
mov ebx, 0Ah
; Заносим в EBX значение 0xA
cdq
; Расширяем EAX до четверного слова EDX:EAX
idiv ebx
; Делим ECX на 0xA (долго делим – тактов 20, а то и больше)
push eax
; Передаем полученное значение функции printf
test ecx, ecx
jns short loc_401092
; Если делимое не отрицательно, то переход на loc_401092
add ecx, 1Fh
; Если делимое положительно, то добавляем к нему 0x1F для округления
loc_401092: ; CODE XREF: _main+11j
sar ecx, 5
; Сдвигом на пять позиций вправо делим число на 32
push ecx
push offset aXX ; "%x %x\n"
call _printf
add esp, 0Ch
; printf("%x %x\n", var_a / 10, var_a / 32)
xor eax, eax
; Возвращаем ноль
pop ebx
pop ebp
; Закрываем кадр стека
retn
_main endp
Листинг 213
Идентификация оператора "%". Специальной инструкции для вычисления остатка в наборе команд микропроцессоров серии 80x86 нет, - вместо этого остаток вместе с частным возвращается инструкциями деления DIV, IDIV
и FDIVx
(см. идентификация оператора "/").
Если делитель представляет собой степень двойки (2N = b), а делимое беззнаковое число, то остаток будет равен N младшим битам делимого числа. Если же делимое – знаковое, необходимо установить все биты, кроме первых N равными знаковому биту для сохранения знака числа. Причем, если N первых битов равно нулю, все биты результата должны быть сброшены независимо от значения знакового бита.
Таким образом, если делимое – беззнаковое число, то выражение a % 2N
транслируется в конструкцию: "AND a, N", в противном случае трансляция становится неоднозначна – компилятор может вставлять явную проверку на равенство нулю с ветвлением, а может использовать хитрые математические алгоритмы, самый популярный из которых выглядит так: DEC x\ OR x, -N\ INC x. Весь фокус в том, что если первые N бит числа x равны нулю, то все биты результата кроме старшего, знакового бита, будут гарантированно равны одному, а OR x, -N
принудительно установит в единицу и старший бит, т.е. получится значение, равное, –1. А INC –1 даст ноль! Напротив, если хотя бы один из N младших битов равен одному, заема из старших битов не происходит и INC x
возвращает значению первоначальный результат.
Продвинутые оптимизирующие компиляторы могут путем сложных преобразований заменять деление на ряд других, более быстродействующих операций. К сожалению, алгоритмов для быстрого вычисления остатка для всех делителей не существует и делитель должен быть кратен , где k и t – некоторые целые числа.
Тогда остаток можно вычислить по следующей формуле:
Да, эта формула очень сложна и идентификация оптимизированного оператора "%" может быть весьма и весьма непростой, особенно учитывая патологическую любовь оптимизаторов к изменению порядка команд.
Рассмотрим следующий пример:
main()
{
int a;
printf("%x %x\n",a % 16, a % 10);
}
Листинг 214 Идентификация оператора "%"
Результат его компиляции компилятором Microsoft Visual C++ с настройками по умолчанию должен выглядеть так:
main proc near ; CODE XREF: start+AFp
var_4 = dword ptr -4
push ebp
mov ebp, esp
; Открываем кадр стека
push ecx
; Резервируем память для локальной переменной
mov eax, [ebp+var_a]
; Заносим в EAX значение переменной var_a
cdq
; Расширяем EAX до четвертного слова EDX:EAX
mov ecx, 0Ah
; Заносим в ECX значение 0xA
idiv ecx
; Делим EDX:EAX
(var_a) на ECX (0xA)
push edx
; Передаем остаток от деления var_a на 0xA функции printf
mov edx, [ebp+var_a]
; Заносим в EDX значение переменной var_a
and edx, 8000000Fh
; "Вырезаем" знаковый бит и четыре младших бита числа
; в четырех младших битах содержится остаток от деления EDX
на 16
jns short loc_401020
; Если число не отрицательно, то прыгаем на loc_401020
dec edx
or edx, 0FFFFFFF0h
inc edx
; Последовательность сия, как говорилось выше характера для быстрого
; расчета отставка знакового числа
; Следовательно, последние шесть инструкций расшифровываются как:
; EDX = var_a % 16
loc_401020: ; CODE XREF: main+19j
push edx
push offset aXX ; "%x %x\n"
call _printf
add esp, 0Ch
; printf("%x %x\n",var_a % 0xA, var_a % 16)
mov esp, ebp
pop ebp
; Закрываем кадр стека
retn
main endp
Листинг 215
Любопытно, что оптимизация не влияет на алгоритм вычисления остатка.
Увы, ни Microsoft Visual C++, ни остальные известные мне компиляторы не умеют вычислять остаток умножением.
Идентификация оператора "*".
В общем случае оператор "*" транслируется либо в машинную инструкцию "MUL" (беззнаковое целочисленное умножение), либо в "IMUL" (целочисленное умножение со знаком), либо в "FMULx" (вещественное умножение). Если один из множителей кратен степени двойки, то "MUL" ("IMUL") обычно заменяется командой битового сдвига влево "SHL" или инструкцией "LEA", способной умножать содержимое регистров на 2, 4 и 8. Обе последних команды выполняются за один такт, в то время как MUL
требует в зависимости от модели процессора от двух до девяти тактов. К тому же LEA
за тот же такт успевает сложить результат умножение с содержимым регистра общего назначения и/или константой в придачу. Это позволяет умножать на 3, 5 и 9 просто добавляя к умножаемому регистру его значение. Ну, разве это не сказка? Правда, у LEA есть один недочет – она может вызывать остановку AGI, в конечном счете "съедающую" весь выигрыш в быстродействии на нет.
Рассмотрим следующий пример:
main()
{
int a;
printf("%x %x %x\n",a * 16, a * 4 + 5, a * 13);
}
Листинг 216 Идентификация оператора "*"
Результат его компиляции компилятором Microsoft Visual C++ с настройками по умолчанию должен выглядеть так:
main proc near ; CODE XREF: start+AFp
var_a = dword ptr -4
push ebp
mov ebp, esp
; Открываем кадр стека
push ecx
; Резервируем место для локальной переменной var_a
mov eax, [ebp+var_a]
; Загружаем в EAX значение переменной var_a
imul eax, 0Dh
; Умножаем var_a
на 0xD, записывая результат в EAX
push eax
; Передаем функции printf произведение var_a * 0xD
mov ecx, [ebp+var_a]
; Загружаем в ECX значение var_a
lea edx, ds:5[ecx*4]
; Умножаем ECX на 4 и добавляем к полученному результату 5, записывая его в EDX
; И все это выполняется за один такт!
push edx
; Передаем функции printf результат var_a * 4 + 5
mov eax, [ebp+var_a]
; Загружаем в EAX значение переменной var_a
shl eax, 4
; Умножаем var_a на
16
push eax
; Передаем функции printf произведение var_a * 16
push offset aXXX ; "%x %x %x\n"
call _printf
add esp, 10h
; printf("%x %x %x\n", var_a * 16, var_a * 4 + 5, var_a * 0xD)
mov esp, ebp
pop ebp
; Закрываем кадр стека
retn
main endp
Листинг 217
За вычетом вызова функции printf и загрузки переменной var_a из памяти на все про все требуется лишь три
такта процессора. А что будет, если скомпилировать этот пример с ключиком "/Ox"? А будет вот что:
main proc near ; CODE XREF: start+AFp
push ecx
; Выделяем память для локальной переменной var_a
mov eax, [esp+var_a]
; Загружаем в EAX значение переменной var_a
lea ecx, [eax+eax*2]
; ECX = var_a * 2 + var_a = var_a * 3
lea edx, [eax+ecx*4]
; EDX = (var_a * 3)* 4 + var_a = var_a * 13!
; Вот так компилятор ухитрился умножить var_a на 13,
; причем всего за один (!) такт. Да, обе инструкции LEA
прекрасно спариваются
; на Pentium MMX и Pentium Pro!
lea ecx, ds:5[eax*4]
; ECX = EAX*4 + 5
push edx
push ecx
; Передаем
функции printf var_a * 13 и var_a * 4 +5
shl eax, 4
; Умножаем var_a на
16
push eax
push offset aXXX ; "%x %x %x\n"
call _printf
add esp, 14h
; printf("%x %x %x\n", var_a * 16, var_a * 4 + 5, var_a * 13)
retn
main endp
Листинг 218
Этот код, правда, все же не быстрее предыдущего, не оптимизированного, и укладывается в те же три такта, но в других случаях выигрыш может оказаться вполне ощутимым.
Другие компиляторы так же используют LEA для быстрого умножения чисел. Вот, к примеру, Borland поступает так:
_main proc near ; DATA XREF: DATA:00407044o
lea edx, [eax+eax*2]
; EDX = var_a*3
mov ecx, eax
; Загружаем в ECX неинициализированную регистровую переменную var_a
shl ecx, 2
; ECX = var_a * 4
push ebp
; Сохраняем EBP
add ecx, 5
; Добавляем к var_a
* 4 значение 5
; Borland
не использует LEA
для сложения. А жаль…
lea edx, [eax+edx*4]
; EDX = var_a + (var_a *3) *4 = var_a * 13
; А вот в этом Borland и MS единодушны :-)
mov ebp, esp
; Открываем кадр стека
; Да, да… вот так посреди функции и открываем…
; Выше, кстати, "потерянная" команда push EBP
push edx
; Передаем printf произведение var_a
* 13
shl eax, 4
; Умножаем ((var_a
*4) + 5) на 16
; Что такое?! Да, это глюк компилятора, посчитавшего: раз переменная var_a
; неинициализирована, то ее можно и не загружать…
push ecx
push eax
push offset aXXX ; "%x %x %x\n"
call printf
add esp, 10h
xor eax, eax
pop ebp
retn
_main endp
Листинг 219
Хотя "визуально" Borland генерирует более "тупой" код, его выполнение укладывается в те же три такта процессора. Другое дело WATCOM, показывающий удручающе отсталый результат на фоне двух предыдущих компиляторов:
main proc near
push ebx
; Сохраняем EBX в стеке
mov eax, ebx
; Загружаем в EAX значение неинициализированной регистровой переменной var_a
shl eax, 2
; EAX = var_a * 4
sub eax, ebx
; EAX = var_a * 4 – var_a = var_a * 3
; Вот каков WATCOM! Сначала умножает "с запасом", а потом лишнее отнимает!
shl eax, 2
; EAX = var_a * 3 * 4 = var_a * 12
add eax, ebx
; EAX = var_a * 12 + var_a = var_a * 13
; Вот так, да? Четыре инструкции, в то время как "ненавистный" многим
; Microsoft Visual C++ вполне обходится и двумя!
push eax
; Передаем printf значение var_a
* 13
mov eax, ebx
; Загружаем в EAX значение неинициализированной регистровой переменной var_a
shl eax, 2
; EAX = var_a * 4
add eax, 5
; EAX = var_a * 4 + 5
; Ага! Пользоваться LEA WATCOM то же не умеет!
push eax
; Передаем printf значение var_a * 4 + 5
shl ebx, 4
; EBX = var_a * 16
push ebx
; Передаем printf значение var_a * 16
push offset aXXX ; "%x %x %x\n"
call printf_
add esp, 10h
; printf("%x %x %x\n",var_a * 16, var_a * 4 + 5, var_a*13)
pop ebx
retn
main_ endp
Листинг 220
В результате, код, сгенерированный компилятором WATCOM требует шести тактов, т.е. вдвое больше, чем у конкурентов.
::Комплексные операторы. Язык Си\Си++ выгодно отличается от большинства своих конкурентов поддержкой комплексных операторов: x= (где x – любой элементарный оператор), ++ и – –.
Комплексные операторы семейства "a x= b" транслируются в "a = a x b" и они идентифицируются так же, как и элементарные операторы (см. "элементарные операторы").
Операторы "++" и "––": в префиксной форме они выражаются в тривиальные конструкции "a = a +1" и "a = a – 1" не представляющие для нас никакого интереса, но вот постфиксная форма – дело другое.
__обращение к разным частям одной переменной
Идентификация new и delete
…нет ничего случайного. Самые свободные ассоциации являются самыми надежными"
тезис классического психоанализа
Операторы new
и delete транслируются компилятором в вызовы библиотечных функций, которые могут быть распознаны точно так, как и обычные библиотечные функции (см. "Идентификация библиотечных функций"). Автоматически распознавать библиотечные функции умеет, в частности, IDA Pro, снимая эту заботу с плеч пользователя. Однако IDA Pro есть не у всех, и далеко не всегда в нужный момент находится под рукой, да к тому же не все библиотечные функции она знает, а из тех, что знает не всегда узнает new
и delete… Словом, причин для их ручной идентификации существует предостаточно…
Реализация new
и delete может быть любой, но Windows-компиляторы в большинстве своем редко реализуют функции работы с кучей самостоятельно, - зачем это, ведь намного проще обратиться к услугам операционной системы. Однако наивно ожидать вместо new вызов HeapAlloc, а вместо delete – HeapFree. Нет, компилятор не так прост! Разве он может отказать себе в удовольствии "вырезания матрешек"? Оператор new транслируется в функцию new, вызывающую для выделения памяти malloc, malloc же в свою очередь обращается к heap_alloc (или ее подобию – в зависимости от реализации библиотеки работы с памятью – см. "подходы к реализацию кучи"), – своеобразной "обертке" одноименной Win32 API-процедуры. Картина с освобождением памяти – аналогична.
Углубляться в дебри вложенных вызовов – слишком утомительно. Нельзя ли new и delete идентифицировать как-нибудь иначе, с меньшими трудозатратами и без большой головной боли? Разумеется, можно! Давайте вспомним все, что мы знаем о new.
- new принимает единственный аргумент – количество байт выделяемой памяти, причем этот аргумент в подавляющем большинстве случаев вычисляется еще на стадии компиляции, т.е. является константой;
- если объект не содержит ни данных, ни виртуальных функций, его размер равен единице (минимальный блок памяти, выделяемый только для того, чтобы было на что указывать указателю this); отсюда – будет очень много вызовов типа PUSH 01\CALL xxx, - где xxx и есть адрес new! Вообще же, типичный размер объектов составляет менее сотни байт… - ищите часто вызываемую функцию, с аргументом-константой меньшей ста байт;
- функция new – одна из самых "популярных" библиотечных функций, - ищите функцию с "толпой" перекрестных ссылок;
- самое характерное: new возвращает указать this, а this очень легко идентифицировать даже при беглом просмотре кода (см. "Идентификация this");
- возвращенный new результат всегда проверяется на равенство нулю, и если он действительно равен нулю, конструктор (если он есть – см. "Идентификация конструктора и деструктора") не вызывается;
"Родимых пятен" у new более чем достаточно для быстрой и надежной идентификации, - тратить время на анализ ее кода совершенно ни к чему! Единственное, о чем следует помнить: new используется не только для создания новых экземпляров объектов, но и для выделения памяти под массивы (структуры) и изредка – одиночные переменные (типа int *x = new int, - что вообще маразм, но… некоторые так делают). К счастью, отличить два этих способа очень просто – ни у массивов, ни у структур, ни у одиночных переменных нет указателя this!
Давайте, для закрепления всего вышесказанного рассмотрим фрагмент кода, сгенерированного компилятором WATCOM (IDA PRO не распознает его "родную" new):
main_ proc near ; CODE XREF: __CMain+40p
push 10h
call __CHK
push ebx
push edx
mov eax, 4
call W?$nwn_ui_pnv
; это, как мы узнаем позднее, функция new. IDA
вообще-то распознала ее имя, но,
; чтобы узнать в этой "абракадабре" оператор выделения памяти – надо быть
; провидцем!
; Пока же обратим внимание, что она принимает один аргумент-константу
; очень небольшую по значению т.е. заведомо не являющуюся смещением
; (см. "Идентификация констант и смещений")
; Передача аргумента через регистр ни о чем не говорит – Watcom
так поступает
; со многими библиотечными функциями, напротив, другие компиляторы всегда
; заталкивают аргумент в стек...
mov edx, eax
test eax, eax
; Проверка результата, возвращенного функцией, на нулевое значение
; (что характерно для new)
jz short loc_41002A
mov dword ptr [eax], offset BASE_VTBL
; Ага, функция возвратила указатель и по нему записывается указатель на
; виртуальную таблицу (или по крайней мере – массив функций)
; EAX
уже очень похож на this, но, чтобы окончательно убедиться в этом,
; требуется дополнительные признаки…
loc_41002A: ; CODE XREF: main_+1Aj
mov ebx, [edx]
mov eax, edx
call dword ptr [ebx]
; Вот теперь можно не сомневаться, что EAX
– указатель this, а этот код –
; и есть вызов виртуальной функции!
; Следовательно, функция W?$nwm_ui_pnv
и есть new
;(а кто бы еще мог возвратить this?)
Листинг 54
Сложнее идентифицировать delete. Каких либо характерных признаков эта функция не имеет. Да, она принимает единственный аргумент – указатель на освобождаемый регион памяти, причем, в подавляющем большинстве случаев этот указатель – this. Но, помимо нее, this принимают десятки, если не сотни других функций! Правда, между ними существует одно тонкое различие – delete
в большинстве случаев принимает указатель this через стек, а остальные функции – через регистр. К сожалению, некоторые компиляторы, (тот же WATCOM – не к ночи он будет упомянут) передают многим библиотечным функциям аргументы через регистры, скрывая тем самым все различия! Еще, delete
ничего не возвращает, но мало ли функций поступают точно так же? Единственная зацепка – вызов delete
следует за вызовом деструктора (если он есть), но, ввиду того, что конструктор как раз и идентифицируется как функция, предшествующая delete, образуется замкнутый круг!
Ничего не остается, как анализировать ее содержимое – delete рано или поздно вызывает HeapFree (хотя тут возможны и варианты, так Borland содержит библиотеки, работающие с кучей на низком уровне и освобождающие память вызовом VirtualFree). К счастью, IDA Pro в большинстве случаев опознает delete
и самостоятельно напрягаться не приходится.
::подходы к реализации кучи.
В некоторых, между прочим достаточно многих, руководствах по программированию на Си++ (например, Джефри Рихтер "Windows для профессионалов") встречаются призывы всегда выделять память именно new, а не malloc, поскольку, new опирается на эффективные средства управления памятью самой операционной системы, а malloc реализует собственный (и достаточно тормозной) менеджер кучи. Все это грубые натяжки! Стандарт вообще ничего не говорит о реализации кучи, и какая функция окажется эффективнее наперед неизвестно. Все зависит от конкретных библиотек конкретного компилятора.
Рассмотрим, как происходит управление памятью в штатных библиотеках трех популярных компиляторов: Microsoft Visual C++, Borland C++ и Watcom C++.
В Microsoft Visual C++
и malloc, и new представляют собой переходники к одной и той же функции __nh_malloc, поэтому, можно с одинаковым успехом пользоваться и той, и другой. Сама же __nh_malloc вызывает __heap_alloc, в свою очередь вызывающую API функцию Windows HeapAlloc.
(Стоит отметить, что в __heap_alloc есть "хук" – возможность вызвать собственный менеджер куч, если по каким-то причинам системный будет недоступен, впрочем, в Microsoft Visual C++ 6.0 от хука осталась одна лишь обертка, а собственный менеджер куч был исключен).
Все не так в Borland C++! Во-первых, этот зверь напрямую работает с виртуальной памятью Windows, реализуя собственный менеджер кучи, основанный на функциях VirtualAlloc/VirtualFree. Профилировка показывает, что он серьезно проигрывает в производительности Windows 2000 (другие системы не проверял), не говоря уже о том, что помещение лишнего кода в программу увеличивает ее размер. Второе: new вызывает функцию malloc, причем, вызывает не напрямую, а через несколько слоев "оберточного" кода! Поэтому, вопреки всем рекомендациям, под Borland C++ вызов malloc
эффективнее, чем new!
Товарищ Watcom
(во всяком случае, его одиннадцатая версия – последняя, до которой мне удалось дотянуться) реализует new
и malloc практически идентичным образом, - обе они ссылаются на _nmalloc, - очень "толстую" обертку от LocalAlloc. Да, да – 16-разрядной функции Windows, самой являющейся переходником к HeapAlloc!
Таким образом, Джефри Рихтер лопухнулся по полной программе – ни в одном из популярных компиляторов new не быстрее malloc, а вот наоборот – таки да. Уж не знаю, какой он такой редкоземельный компилятор имел ввиду (точнее, не сам компилятор, а библиотеки, поставляемые вместе с ним, но это не суть важно), или, скорее всего, просто писал не думавши. Отсюда мораль – все умозаключения, прежде чем переносить на бумагу, необходимо тщательно проверять.
Идентификация объектов, структур и массивов
Для целого поколения Эйнштейн был глашатаем передовой науки, пророком разума и мира. А сам он в глубине своей кроткой и невозмутимой души без всякой горечи оставался скептиком… Он хотел затеряться и как бы раствориться в окружающем его мире, а оказался одним из самых разрекламированных людей нашего века, и его лицо, вдохновенное и отрешенное от всех грехов мира, стало таким же широко известным, как фотография какой-нибудь кинозвезды.
Чарлз Перси Сноу «ЭЙНШТЕЙН»
Внутренне представление объектов очень похоже на представление структур в языке Си (по большому счету, объекты и есть структуры), поэтому, рассмотрим их идентификацию в одной главе.
Структуры очень популярны среди программистов – позволяя объединить под одной крышей родственные данные, они делают листинг программы более наглядным, упрощая его понимание. Соответственно, идентификация структур при дизассемблировании облегчает анализ кода. К великому сожалению исследователей, структуры как таковые существует только в исходном тексте программы и практически полностью "перемалываются" при ее компиляции, становясь неотличимыми от обычных, никак не связанных друг с другом переменных.
Рассмотрим следующий пример:
#include <stdio.h>
#include <string.h>
struct zzz
{
char s0[16];
int a;
float f;
};
func(struct zzz y)
// Понятное дело, передачи структуры по значению лучше избегать,
// но здесь это сделано умышленно для демонстрации скрытого создания
// локальной переменной
{
printf("%s %x
%f\n",&y.s0[0], y.a, y.f);
}
main()
{
struct zzz y;
strcpy(&y.s0[0],"Hello,Sailor!");
y.a=0x666;
y.f=6.6;
func(y);
}
Листинг 45 Пример, демонстрирующий уничтожение структур на стадии компиляции
Результат его компиляции в общем случае должен выглядеть так:
main proc near ; CODE XREF: start+AFp
var_18 = byte ptr -18h
var_8 = dword ptr -8
var_4 = dword ptr -4
; члены структуры неотличимы от обычных локальных переменных
push ebp
mov ebp, esp
sub esp, 18h
; резервирование места в стеке для структуры
push esi
push edi
push offset aHelloSailor ; "Hello,Sailor!"
lea eax, [ebp+var_18]
; Указатель на локальную переменную var_18
; следующая за ней переменная расположена по смещению 8
; следовательно, 0x18-0x8=0x10 – шестнадцать байт – именно столько
; занимает var_18, что намекает на то, что она – строка
; (см. "Идентификация литералов и строк")
push eax
call strcpy
; копирование строки из сегмента данных в локальную переменную-член структуры
add esp, 8
mov [ebp+var_8], 666h
; занесение в переменную типа DWORD
значения 0x666
mov [ebp+var_4], 40D33333h
; а это значение в формате float равно 6.6
; (см. "Идентификация аргументов функций")
sub esp, 18h
; резервируем место для скрытой локальной переменной, которая используется
; компилятором для передачи функции экземпляра структуры по значению
; (см. "Идентификация локальных переменных – регистровых и временныех
переменныех")
mov ecx, 6
; будет скопировано 6 двойных слов, т.е. 24 байта
; 16 – на строку и по четыре на float
и int
lea esi, [ebp+var_18]
; получаем указатель на копируемую структуру
mov edi, esp
; получаем указатель на только что созданную скрытую локальную переменную
repe movsd
; копируем!
call func
; вызываем функцию
; передачи указателя на скрытую локальную переменную не происходит – она
; и так находится на верху стека.
add esp, 18h
pop edi
pop esi
mov esp, ebp
pop ebp
retn
main endp
Листинг 46
А теперь заменим структуру последовательным объявлением тех же самых переменных:
main()
{
char s0[16];
int a;
float f;
strcpy(&s0[0],"Hello,Sailor!");
a=0x666;
f=6.6;
}
Листинг 47 Пример, демонстрирующий сходство структур с обычными локальными переменными
И сравним результат компиляции с предыдущим:
main proc near ; CODE XREF: start+AFp
var_18 = dword ptr -18h
var_14 = byte ptr -14h
var_4 = dword ptr -4
; Ага, кажется есть какое-то различие! Действительно, локальные переменные помещены
; в стек не в том порядке, в котором они были объявлены в программе, а как это
; захотелось компилятору. Напротив, члены структуры обязательно должны помещаться
; в порядке их объявления.
; Но, поскольку, при дизассемблировании оригинальный порядок следования переменных
; не известен, определить "правильно" ли они расположены или нет, увы,
; не представляется возможным
push ebp
mov ebp, esp
sub esp, 18h
; резервируем 0x18 байт стека (как и предыдущем примере)
push offset aHelloSailor ; "Hello,Sailor!"
lea eax, [ebp+var_14]
push eax
call strcpy
add esp, 8
mov [ebp+var_4], 666h
mov [ebp+var_18], 40D33333h
; смотрите: код аккуратно совпадает байт в байт! Следовательно, невозможно
; автоматически отличить структуру от простого скопища локальных переменных
mov esp, ebp
pop ebp
retn
main endp
func proc near ; CODE XREF: main+36p
var_8 = qword ptr -8
arg_0 = byte ptr 8
arg_10 = dword ptr 18h
arg_14 = dword ptr 1Ch
; смотрите: хотя функции передается только один аргумент – экземпляр структуры –
; в дизассемблерном тексте он не отличим от последовательной засылки в стек
; нескольких локальных переменных! Поэтому, восстановить подлинный прототип
; функции невозможно!
push ebp
mov ebp, esp
fld [ebp+arg_14]
; загрузить в стек FPU вещественное целое, находящееся по смещению
; 0x14 относительно указателя eax
sub esp, 8
; зарезервировать 8 байт пол локал. перемен.
fstp [esp+8+var_8]
; перепихнуть считанное вещественное значение в локальную переменную
mov eax, [ebp+arg_10]
push eax
; прочитать только что "перепихнутую" вещественную переменную
; и затолкать ее в стек
lea ecx, [ebp+arg_0]
; получить указатель на первый аргумент
push ecx
push offset aSXF ; "%s %x %f\n"
call printf
add esp, 14h
pop ebp
retn
func endp
Листинг 48
Выходит, отличить структуру от обычных переменных невозможно? Неужто исследователю придется самостоятельно распознавать "родство" данных и связывать их "брачными узами", порой ошибаясь и неточно воспроизводя исходный текст программы?
Как сказать… И да, и нет одновременно. "Да": экземпляр структуры, использующийся в той же единице трансляции в которой он был объявлен, "развертывается" еще на стадии компиляции в самостоятельные переменные, обращение к которым происходит индивидуально по их фактическим адресам (возможно относительным). "Нет", – если в области видимости находится один лишь указатель на экземпляр структуры. – Тогда обращение ко всем членам структуры происходит через указатель на этот экземпляр структуры (т.к. структура не присутствует в области видимости, например, передается другой функции по ссылке, вычислить фактические адреса ее членов на стадии компиляции невозможно).
Постойте, но ведь точно так происходит обращение и к элементам массива, – базовый указатель указывает на начало массива, к нему добавляется смещение искомого элемента относительно начала массива (индекс элемента, умноженный на его размер), – результат вычислений и будет фактическим указателем на искомый элемент!
Единственное фундаментальное отличие массивов от структур состоит в том, что массивы гомогенны
(т.е. состоят из элементов одинакового типа), а структуры могут быть как гомогенными, таки гетерогенными
(состоящими из элементов различных типов). Таким образом, задача идентификации структур и массивов сводится: во-первых, к выделению ячеек памяти, адресуемых через общий для всех них базовый указатель, и, во-вторых, определению типа этих переменных ___(см.
идентификация типов данных). Если удается выделить более одного типа – скорее всего перед нами структура, в противном случае это с равным успехом может быть и структурой, и массивом, - тут уж приходится смотреть по обстоятельствам и самой программе.
С другой стороны, если программисту вздумается подсчитать зависимость выпитого пива от дня недели, он может выделить для учета либо массив day[7], либо завести структуру struct week{int Monday; int Tuesday;….}. И в том, и в другом случае сгенерированный компилятором код будет одинаков, да не только код, но и смысл! В этом контексте структура неотличима от массива и физически, и логически, - выбор той или иной конструкции – дело вкуса.
Так же возьмите себе на заметку, что массивы, как правило, длинны, а обращение к их элементам часто сопровождается различными математическими операциями, совершаемыми над указателем. Далее – обработка элементов массива как правило осуществляется в цикле, а члены структуры по обыкновению "разбираются" индивидуально (хотя некоторые программисты позволяют себе вольность обращаться со структурой как с массивом). Еще неприятнее, что Си/Си++ допускают (если не сказать провоцируют) явное преобразование типов и… ой, а ведь в этом случае, при дизассемблировании не удастся установить: имеем ли мы дело с объединенными под одну крышу разнотипными данными (т.е. структуру), или же это массив, c "ручным" преобразованием типа своих элементов. Хотя, строго говоря, после подобных преобразований массив превращается в самую настоящую структуру! (Массив по определению гомогенен, и данные разных типов хранить не может).
Модифицируем предыдущий пример, передав функции не саму структуру, а указатель на нее и посмотрим, что за код сгенерировал компилятор.
funct proc near ; CODE XREF: sub_0_401029+29p
var_8 = qword ptr -8
arg_0 = dword ptr 8
; ага! Функция принимает только один аргумент!
push ebp
mov ebp, esp
mov eax, [ebp+arg_0]
; загружаем переданный функции аргумент в EAX
fld dword ptr [eax+14h]
; загружаем в стек FPU вещественное значение, находящееся по смещению
; 0x14 относительно указателя EAX
; Таким образом, во-первых, EAX (аргумент, переданный функции) – это указатель
; во-вторых, это не просто указатель, а базовый указатель, использующийся
; для доступа к элементам структуры или массива.
; Запомним тип первого элемента (вещественное значение) и продолжим анализ
sub esp, 8
; резервируем 8 байт пол локальные переменные
fstp [esp+8+var_8]
; перепихиваем считанное вещественное значение в локальную переменную var_8
mov ecx, [ebp+arg_0]
; Загружаем в ECX значение переданного функции указателя
mov edx, [ecx+10h]
; загружаем в EDX значение, лежащее по смещению 0x10
; Ага! Это явно не вещественное значение, следовательно, мы имеем дело со
; структурой
push edx
; заталкиваем только что считанное значение в стек
mov eax, [ebp+arg_0]
push eax
; получаем указатель на структуру (т.е. на ее первый член)
; и запихиваем его в стек. Поскольку ближайший элемент
; находится по смещению 0x10, то первый элемент структуры по-видимому
; занимает все эти 0x10 байт, хотя это и не обязательно – возможно остальные
; члены структуры просто не используются. Установить: как все обстоит на самом
; деле можно, обратившись к вызывающей (материнской) функции, которая и
; инициализировала эту структуру, но и без этого, мы можем восстановить
; ее приблизительный вид
; struct xxx{
; char x[0x10] || int x[4] || __int16[8] || __int64[2];
; int y;
; float z;
; }
push offset aSXF ; "%s %x %f\n"
; строка спецификаторов, позволяет уточнить типы данных – так, первый элемент
; это, бесспорно, char x[x010], поскольку, он выводится как строка,
; следовательно наше предварительное предположение о формате структуры –
; верное!
call printf
add esp, 14h
pop ebp
retn
funct endp
main proc near ; CODE XREF: start+AFp
var_18 = byte ptr -18h
var_8 = dword ptr -8
var_4 = dword ptr -4
; смотрите: на первый взгляд мы имеем дело с несколькими локальными переменными,
; но давайте не будем торопиться с их идентификацией!
push ebp
mov ebp, esp
sub esp, 18h
; Открываем кадр стека
push offset aHelloSailor ; "Hello,Sailor!"
lea eax, [ebp+var_18]
push eax
call unknown_libname_1
; unknown_libmane_1 – это strcpy и понять это можно даже не анализируя ее код.
; Функция принимает два аргумента – указатель на локальный буфер из 0x10 байт
; (размер 0x10 получен вычитанием смещения ближайшей переменной от смещения
; самой этой переменной относительно карда стека) такой же точно прототип
; и у strcmp, но это не может быть strcmp, т.к. локальный буфер
; не инициализирован, и он может быть только буфером-приемником
add esp, 8
; выталкиваем аргументы из стека
mov [ebp+var_8], 666h
; инициализируем локальную переменную var_8 типа DWORD
mov [ebp+var_4], 40D33333h
; инициализируем локальную переменную var_4 типа... нет, не DWORD
; (хотя она и выглядит как DWORD), - проанализировав, как эта переменная
; используется в функции funct, которой она передается, мы распознаем
; в ней вещественное значение размером 4 байта. Стало быть это float
; (подробнее см. "Идентификация аргументов функций")
lea ecx, [ebp+var_18]
push ecx
; Вот теперь – самое главное! Функции передается указатель на локальную
; переменную var_18, - строковой буфер размером в 0x10 байт,
; но анализ вызываемой функции позволил установить, что она обращается не
; только к первым 0x10 байтам стека материнской функции, а ко всем – 0x18!
; Следовательно, функции передается не указатель на строковой буфер,
; а указатель на структуру
;
; srtuct x{
; char var_18[10];
; int var_8;
; float var_4
; }
;
; Поскольку, типы данных различны, то это – именно структура, а не массив.
call funct
add esp, 4
mov esp, ebp
pop ebp
retn
sub_0_401029 endp
Листинг 49
::Идентификация объектов. Объекты языка Си++ - это, по сути дела, структуры, совмещающие в себе данные, методы их обработки (функции то бишь), и атрибуты защиты (типа public, friend…).
Элементы-данные объекта обрабатываются компилятором равно как и обычные члены структуры. Не виртуальные функции вызываются по фактическому смещению и в объекте отсутствуют. Виртуальные функции вызываются через специальный указатель на виртуальную таблицу, помещенный в объект, а атрибуты защиты уничтожаются еще на стадии компиляции. Отличить публичную функцию от защищенной можно только тем, что публичная вызывается и из других объектов, а защищенная – только из своего объекта.
Теперь обо всем этом подробнее. Итак, объект (вернее, экземпляр объекта) – что он собой представляет? Пусть у нас есть следующий объект:
class MyClass{
void demo_1(void);
int a;
int b;
public:
virtual void demo_2(void);
int c;
};
MyClass zzz;
Листинг 50 Пример, демонстрирующий строение объекта
Экземпляр объекта zzz "перемелется" компилятором в следующую структуру (см. рис 13):
Рисунок 13 0х008 Представление экземпляра объекта в памяти.
Перед исследователем встают следующие проблемы: как отличить объекты от простых структур? Как определить размер объектов? Как определить какая функция к какому объекту принадлежит? Как…. Погодите, погодите, не все сразу! Начнем, отвечать на вопросы по порядку согласно социалистической очереди.
Вообще же, строго говоря, отличить объект от структуры невозможно в силу того, что объект и есть структура с членами приватными по умолчанию. При объявлении объектов можно пользоваться и ключевым словом "struct", и ключевым словом "class". Причем, для классов, все члены которых открыты, предпочтительнее использовать именно "struc", т.к.
члены структуры уже публичны по умолчанию. Сравните два следующих примера:
struct MyClass{ class MyClass{
void demo(void); void demo_private(void);
int x; int y;
private: public:
void demo_private(void); void demo(void);
int y; int x;
}; };
Листинг 51 Классы – это структуры с членами приватными по умолчанию
Одна запись отличается от другой лишь синтаксически, а код, генерируемый компилятором, будет идентичен! Поэтому, с надеждой научиться отличать объекты от структур следует как можно скорее расстаться.
ОК, условимся считать объектами структуры, содержащие одну или более функций, вот только как определить какая функция какому объекту принадлежит? С виртуальными функциями все просто – они вызываются косвенно, через указатель на виртуальную таблицу, помещаемый компилятором в каждый экземпляр объекта, к которому принадлежит данная виртуальная функция. Не виртуальные функции вызываются по их фактическому адресу, равно как и обычные функции, не принадлежащие никакому объекту. Положение безнадежно? Отнюдь нет! Каждой функции-члену объекта передается неявный аргумент – указатель this, ссылающийся на экземпляр объекта, к которому принадлежит данная функция. Экземпляр объекта это, правда, не сам объект, но нечто очень тесно с ним связанное, поэтому, восстановить исходную структуру объектов дизассемблируемой программы – вполне реально (подробнее об этом см. "Объекты и экземпляры")
Размер объектов
определяется теми же указателями this – как разница соседний указателей (если объекты расположены в стеке или в сегменте данных). Если же экземпляры объектов создаются оператором new (как часто и бывает), то в код помещается вызов функции new, принимающий в качестве аргумента количество выделяемых байт, - это и есть размер объекта.
Вот, собственно, и все. Остается добавить, что многие компиляторы, создавая экземпляр объекта, не содержащего ни данных, ни виртуальных функций, все равно выделяют под него минимальное количество памяти (обычно один байт), хотя никак его не используют.
call demo
; Вот мы и добрались до вызова функции demo
– открываем хвост Тигре!
; Пока не ясно, что эта функция делает (символьное имя дано ей для наглядности)
; но известно, что она принадлежит экземпляру объекта, на который
; указывает ECX. Назовем этот экземпляр 'a'. Далее – поскольку
; функция, вызывающая demo (т.е. функция в которой мы сейчас находимся), не
; принадлежит к 'a' (она же его сама и создала – не мог же экземпляр объекта
; сам "вытянуть себя за волосы"), то функция demo
– это public-функция.
; Неплохо для начала?
mov dword ptr [esi], 777h
; так, так... мы помним, что ESI указывает на экземпляр объекта, тогда
; выходит, что в объекте есть еще один public-член, это переменная
; типа int.
; По предварительным заключениям объект выглядел так:
; class myclass{
; public:
; void demo(void); // void –т.к. функция ничего не принимает и не возвращает
; int x;
;}
pop esi
retn
main endp
demo proc near ; CODE XREF: main+Fp
; вот мы в функции demo – члене объекта A
push esi
mov esi, ecx
; Загружаем в ECX – указатель this, переданный функции
push offset aMyclass ; "MyClass\n"
call printf
add esp, 4
; Выводим строку на экран...это не интересно, но вот дальше…
mov ecx, esi
call demo_private
; Опля, вот он, наш Тигра! Вызывается еще одна функция! Судя по this,
; эта функция нашего объекта, причем вероятнее всего имеющая атрибут private,
; поскольку вызывается только из функции самого объекта.
mov dword ptr [esi+4], 666h
; Так, в объекте есть еще одна переменная, вероятно, приватная. Тогда,
; по современным воззрениям, объект должен выглядеть так:
; class myclass{
; void demo_provate(void);
; int y;
; public:
; void demo(void); // void –т.к. функция ничего не принимает и не возвращает
; int x;
; }
;
; Итак, мы не только идентифицировали объект, но даже восстановили его
; структуру! Пускай, не застрахованную от ошибок (так, предположение
; о приватности "demo_private" и "y" базируется лишь на том, что они ни разу
; не вызывались извне объекта), но все же – не так ООП страшно, как его
; малюют и восстановить если не подлинный исходный текст программы, то хотя бы
; какое-то его подобие вполне возможно!
pop esi
retn
demo endp
demo_private proc near ; CODE XREF: demo+12p
; приватная функция demo. – ничего интересного
push offset aPrivate ; "Private\n"
call printf
pop ecx
retn
demo_private endp
Листинг 53
::Объекты и экземпляры. В коде, сгенерированном компилятором, никаких объектов и в помине нет, – одни лишь экземпляры объектов. Вроде бы – да какая разница-то? Экземпляр объекта разве не есть сам объект? Нет, между объектом и экземпляром существует принципиальная разница. Объект – это структура, в то время как экземпляр объекта (в сгенерированном коде!) – подструктура этой структуры. Т.е. пусть имеется объект А, включающий в себя функции a1 и a2. Далее, пусть создано два его экземпляра – из одного мы вызываем функцию a1, а из другого – a2. С помощью указателя this мы сможем выяснить лишь то, что одному экземпляру принадлежит функция a1, а другому – a2. Но установить – являются ли эти экземпляры экземплярами одного объекта или экземплярами двух разных объектов – невозможно! Ситуация усугубляется тем, что в производных классах наследуемые функции не дублируются (во всяком случае, так поступают "умные" компиляторы, хотя… в жизни случается всякое). Возникает двузначность – если с одним экземпляром связаны функции a1 и a2, а с другим - a1, a2 и a3, то это могут быть либо экземпляры одного класса (просто из первого экземпляра функция a3 не вызывается), то ли второй экземпляр – экземпляр класса, производного от первого. Код, сгенерированный компилятором, в обоих случаях будет идентичным! Приходится восстанавливать иерархию классов по смыслу и назначению принадлежащих им функций… понятное дело, приблизиться к исходному коду сможет только провидец (ясновидящий).
Словом, как бы там ни было, никогда не путайте экземпляр объекта с самим объектом, и не забываете, что объекты существуют только в исходном тексте и уничтожаются на стадии компиляции.
::мой адрес – не дом и не улица! Где "живут" структуры, массивы и объекты? Конечно же, в памяти! А поконкретнее? Конкретнее: существуют три типа размещения: в стеке
(автоматическая память), сегменте данных (статическая память) и куче (динамическая память). И каждый тип со своим "характером". Возьмем стек – выделение памяти неявное, фактически происходящее на этапе компиляции, причем гарантированно определяется только общий объем памяти, выделенный под все локальные переменные, а определить: сколько занимает каждая из них – невозможно в принципе. Не верите? А вот скажем, пусть будет такой код: "char a1[13]; char a2[17]; char a3[23]". Если компилятор выровняет массивы по кратным адресам (а это делают многие компиляторы), то разница смещений ближайших друг к другу массивов может и не быть равна их размеру. Единственная надежда восстановить подлинный размер – найти в коде проверки на выход за границы массива (если они есть – их часто не бывает). Второе (самое неприятное) – если один из массивов не используется, а только объявляется, то не оптимизирующие компиляторы (и даже некоторые оптимизирующие!) могут, тем не менее, отвести для него стековое пространство. Он вплотную примкнет к предыдущему массиву и… гадай – то ли размер массива такой, то ли в его конец "вбухан" неиспользуемый массив? Ну, с массивами куда бы еще ни шло, а вот со структурами и объектами дела обстоят намного хуже. Никому и в голову не придет помещать в программу код, отслеживающий выход за пределы структуры (объекта). Такое невозможно в принципе (ну разве что программист слишком вольно работает с указателями)!
Ладно, оставим в стороне размер, перейдем к проблемам "разверстки" и поиску указателей. Как уже говорилось выше, если массив (объект, структура) объявляется в непосредственной области видимости единицы трансляции, он "вспарывается" на этапе компиляции и обращение к его членам происходят по фактическому смещению, а не базовому указателю.
К счастью, идентификацию объектов облегчает наличие в них указателя на виртуальную таблицу, но ведь не факт, что любая таблица указателей на функции – есть виртуальная таблица! Может, это просто массив указателей на функции, определенный самим программистом? Вообще-то, при наличии опыта такие ситуации можно легко распознать (см. "Идентификация виртуальных функций"), но все-таки они достаточно неприятны.
С объектами, расположенными в статической памяти, дела обстоят намного проще, - в силу своей глобальности они имеют специальный флаг, предотвращающий повторный вызов конструктора (подробнее см. "Идентификация конструктора и деструктора"), поэтому, отличить экземпляр объекта, расположенный в сегменте данных, от структуры или массива становится очень легко. С определением его размера, правда, все те же неувязки.
Наконец, объекты (структуры, массивы), расположенные в куче – просто сказка для анализа! Отведение памяти осуществляется функцией, явно принимающей количество выделяемых байт в качестве своего аргумента, и возвращающей указатель, гарантированно указывающий на начало экземпляра объекта (структуры, массива). Радует и то, что обращение к элементам всегда происходит через базовый указатель, даже если объявление совершается в области видимости (иначе и быть не может – фактические адреса выделяемых блоков динамической памяти не известны на стадии компиляции).
__дописать – восстановление структуры многомерных массивов
Идентификация регистровых и временных переменных
Ничто не постоянно так, как временное
Народная мудрость
Стремясь минимализировать количество обращений к памяти, оптимизирующие компиляторы размещают наиболее интенсивно используемые локальные переменные в регистрах общего назначения, только по необходимости сохраняя их в стеке (а в идеальном случае не сохраняя их вовсе).
Какие трудности для анализа это создает? Во-первых, вводит контекстную зависимость в код. Так, увидев в любой точке функции команду типа "MOV EAX,[EBP+var_10]", мы с уверенностью можем утверждать, что здесь в регистр EAX копируется содержимое переменной var_10. А что эта за переменная? Это можно легко узнать, пройдясь по телу функции на предмет поиска всех вхождений "var_10", - они-то и подскажут назначение переменной!
С регистровыми переменными этот номер не пройдет! Положим, нам встретилась инструкция "MOV EAX,ESI" и мы хотим отследить все обращения к регистровой переменной ESI. Как быть, ведь поиск подстроки "ESI" в теле функции ничего не даст, вернее, напротив, выдаст множество ложных срабатываний. Ведь один и тот же регистр (в нашем случае ESI) может использоваться (и используется) для временного хранения множества различных переменных! Поскольку, регистров общего назначения всего семь, да к тому же EBP
"закреплен" за указателем кадра стека, а EAX и EDX
– за возвращаемым значением функции, остается всего четыре регистра, пригодных для хранения локальных переменных. А в Си++ программах и того меньше – один из этих четырех идет под указатель на виртуальную таблицу, а другой – под указатель на экземпляр this. Плохи дела! С двумя регистрами особо не разгонишься, - в типичной функции локальных переменных – десятки! Вот компилятор и использует регистры как кэш, - только в исключительных случаях каждая локальная переменная сидит в "своем" регистре, чаще всего переменных хаотично скачут по регистрам, временами сохраняются в стеке, зачастую выталкиваясь совсем в другой регистр (не в тот, чье содержимое сохранялась).
Практически все распространенные дизассемблеры (в том числе и IDA) не в состоянии отслеживать "миграции" регистровых переменных и эту операцию приходится выполнять вручную. Определить содержимое интересующего регистра в произвольной точке программы достаточно просто, хотя и утомительно, - достаточно прогнать программу с начала функции до этой точки на "эмуляторе Pentium-а", работающего в голове, отслеживая все операции пересылки. Гораздо сложнее выяснить какое количество локальных переменных хранится в данном регистре. Когда большое количество переменных отображается на небольшое число регистров, однозначно восстановить отображение становится невозможно. Вот, например: программист объявляет переменную 'a', - компилятор помещает ее в регистр X. Затем, некоторое время спустя программист объявляет переменную 'b', - и, если переменная 'a' более не используется (что бывает довольно часто), компилятор может поместить в тот же самый регистр X переменную 'b', не заботясь о сохранении значения 'a' (а зачем его сохранять, если оно не нужно). В результате – мы "теряем" одну переменную. На первый взгляд здесь нет никаких проблем. Теряем, - ну и ладно! Теоретически это мог сделать и сам программист, - спрашивается: зачем он вводил 'b', когда для работы вполне достаточно одной 'a'? Если переменные 'a' и 'b' имеют один тип – то никаких проблем, действительно, не возникает, но в противном случае анализ программы будет чрезвычайно затруднен.
Перейдем к технике идентификации регистровых переменных. Во многих хакерских руководствах утверждается, что регистровая переменная отличается от остальных тем, что никогда не обращается к памяти вообще. Это неверно, регистровые переменные могут временно сохраняться в стеке командой PUSH
и восстанавливаться обратно – POP. Конечно, в некотором "высшем смысле" такая переменная перестает быть регистровой, но и не становится стековой. Чтобы не дробить типы переменных на множество классов, условимся считать, что (как утверждают другие хакерские руководства) – регистровая переменная, это переменная, содержащаяся в регистре общего назначения, возможно, сохраняемая в стеке, но всегда на вершине, а не в кадре стека.
Другими словами, регистровые переменные никогда не адресуются через EBP. Если переменная адресуется через EBP, следовательно, она "прописана" в кадре стека, и является стековой переменной. Правильно? Нет! Посмотрите, что произойдет, если регистровой переменной 'a' присвоить значение стековой переменной 'b'. Компилятор сгенерирует приблизительно следующий код "MOV REG, [EBP-xxx]", соответственно, присвоение стековой переменной значения регистровой будет выглядеть так: "MOV [EBP-xxx], REG". Но, несмотря на явное обращение к кадру стека, переменная REG
все же остается регистровой переменной. Рассмотрим следующий код:
...
MOV [EBP-0x4], 0x666
MOV ESI, [EBP-0x4]
MOV [EBP-0x8], ESI
MOV ESI, 0x777
SUB ESI, [EBP-0x8]
MOV [EBP-0xC], ESI
...
Листинг 114
Его можно интерпретировать двояко – то ли действительно существует некая регистровая переменная ESI (тогда исходный тест примера должен выглядеть как показано в листинге 115-а), то ли регистр ESI используется как временная переменная для пересылки данных (тогда исходный текст примера должен выглядеть как показано в листинге 1115-б):
int var_4=0x666; int var_4=0x666;
int var_8=var_4; register {>>> см. сноску}int ESI = var_4;
int vac_C=0x777 – var_8 int var_8=ESI;
ESI=0x777-var_8;
int var_C = ESI
а) б)
Листинг 115
Притом, что алгоритм обоих листингом абсолютно идентичен, левый из них заметно выигрывает в наглядности у правого. А главная цель дизассемблирования – отнюдь не воспроизведение подлинного исходного текста программы, а реконструирование ее алгоритма. Совершенно безразлично, что представляет собой ESI – регистровую или временную переменную. Главное – чтобы костюмчик сидел. Т.е. из нескольких вариантов интерпретации выбирайте самый наглядный!
Вот мы и подошли к понятию временных переменных, но, прежде чем заняться его изучением вплотную, завершим изучение регистровых переменных, исследованием следующего примера:
{>>> сноска | врезка В языках Си/Си++ существует ключевое слово "register" предназначенное для принудительного размещения переменных в регистрах. И все бы было хорошо, да подавляющее большинство компиляторов втихую игнорируют предписания программистов, размещая переменные там, где, по мнению компилятора, им будет "удобно". Разработчики компиляторов объясняют это тем, что компилятор лучше "знает" как построить наиболее эффективный код. Не надо, говорят они, пытаться помочь ему. Напрашивается следующая аналогия: пассажир говорит – мне надо в аэропорт, а таксист без возражений едет "куда удобнее".
Ну, не должна работа на компиляторе превращаться в войну с ним, ну никак не должна! Отказ разместить переменную в регистре вполне законен, но в таком случае компиляция должна быть прекращена с выдачей сообщения об ошибке, типа "убери register, а то компилить не буду!", или на худой конец – выводе предупреждения.}
main()
{
int a=0x666;
int b=0x777;
int c;
c=a+b;
printf("%x + %x = %x\n",a,b,c);
c=b-a;
printf("%x - %x = %x\n",a,b,c);
}
Листинг 116 Пример, демонстрирующий идентификацию регистровых переменных
Результат компиляции Borland C++ 5.x должен выглядеть приблизительно так:
; int __cdecl main(int argc,const char **argv,const char *envp)
_main proc near ; DATA XREF: DATA:00407044o
argc = dword ptr 8
argv = dword ptr 0Ch
envp = dword ptr 10h
; Обратите внимание – IDA не распознала ни одной стековой переменной,
; хотя они объявлялись в программе.
; Выходит, компилятор разместил их в регистрах
push ebp
mov ebp, esp
; Открываем кадр стека
push ebx
push esi
; Сохраняем регистры в стеке или выделяем память для стековых переменных?
; Поскольку, IDA не обнаружила ни одной стековой переменной, вероятнее всего,
; этот код сохраняет регистры
mov ebx, 666h
; Смотрите: инициализируем регистр! Сравните это с примером 112, приведенным в
; главе "Идентификация локальных стековых переменных". Помните, там было:
; mov [ebp+var_4], 666h
; Следовательно, можно заподозрить, что EBX
– это регистровая переменная
; Существование переменной доказывает тот факт, что если бы значение 0x666
; непосредственно передавалось функции т.е. так – printf("%x %x
%x\n", 0x666)
; Компилятор бы и поместил в код инструкцию "PUSH
0x666"
; А раз не так, следовательно: значение 0x666 передавалось через переменную
; Реконструируя исходный тест пишем:
; 1. int a=0x666
mov esi, 777h
; Аналогично, ESI скорее всего представляет собой регистровую переменную
; 2. int b=0x777
lea eax, [esi+ebx]
; Загружаем в EAX сумму ESI и EBX
; Нет, EAX – не указатель, это просто сложение такое хитрое
push eax
; Передаем функции printf сумму регистровых переменных ESI
и EBX
; А вот, что такое EAX – уже интересно. Ее можно представить и самостоятельной
; переменной и непосредственной передачей суммы переменных a
и b
функции
; printf. Исходя из соображений удобочитаемости, выбираем последний вариант
; 3. printf (,,,,a+b)
push esi
; Передаем функции printf регистровую переменную ESI, выше обозначенную нами
; как 'b'
; 3. printf(,,,b,a+b)
push ebx
; Передаем функции printf регистровую переменную EBX, выше обозначенную как 'a'
; 3. printf(,,a,b,a+b)
push offset aXXX ; "%x + %x = %x"
; Передаем функции printf указатель на строку спецификаторов, судя по которой
; все три переменные имеют тип int
; 3. printf("%x + %x = %x", a, b, a + b)
call _printf
add esp, 10h
mov eax, esi
; Копируем в EAX значение регистровой переменной ESI, обозначенную нами 'b'
; 4. int c=b
sub eax, ebx
; Вычитаем от регистровой переменной EAX
('c') значение переменной EBX
('a')
; 5. c=c-a
push eax
; Передаем функции printf разницу значений переменных EAX и EBX
; Ага! Мы видим, что от переменной 'c' можно отказаться, непосредственно
; передав функции printf разницу значений 'b' и 'a'. Вычеркиваем строку '5.'
; (совершаем откат), а вместо '4.' пишем следующее:
; 4. printf(,,,,b-a)
push esi
; Передаем функции printf значение регистровой переменной ESI
('b')
; 4. printf(,,,b, b-a)
push ebx
; Передаем функции printf значение регистровой переменной EBX
('a')
; 4. printf(,,a, b, b-a)
push offset aXXX_0 ; "%x + %x = %x"
; Передаем функции printf указатель на строку спецификаторов, судя по которой
; все трое имеют тип int
; 4. printf("%x + %x = %x",a, b, b-a)
call _printf
add esp, 10h
xor eax, eax
; Возвращаем в EAX нулевое значение
; return 0
pop esi
pop ebx
; Восстанавливаем регистры
pop ebp
; Закрываем кадр стека
retn
; В итоге, реконструированный текст выглядит так:
; 1. int a=0x666
; 2. int b=0x777
; 3. printf("%x + %x = %x", a, b, a + b)
; 4. printf("%x + %x = %x", a, b, b - a)
;
; Сравнивая свой результат с оригинальным исходным текстом, с некоторой досадой
; обнаруживаем, что все-таки слегка ошиблись, выкинув переменную 'c'
; Однако эта ошибка отнюдь не загубила нашу работу, напротив, придала
; листингу более "причесанный" вид, облегчая его восприятие
; Впрочем, о вкусах не спорят, и если вы желаете точнее следовать ассемблерному
; коду, что ж, воля ваша – вводите еще и переменную 'c'. Это решение, кстати,
; имеет тот плюс, что не придется делать "отката" – переписывать уже
; реконструированные строки для удаления их них лишней переменной
_main endp
Листинг 117
…когда же лебедь ушел от нас, мы его имя оставили себе, поскольку мы считали, что оно лебедю больше не понадобится
Алан Александр Милн.
"Дом в медвежьем углу"
(пер.Руднев, Т.Михайлова)
Временные переменные. Временными переменными мы будем называть локальные переменные, внедряемые в код программы самим компилятором.
Для чего они нужны? Рассмотрим следующий пример: "int b=a". Если 'a' и 'b' – стековые переменные, то непосредственное присвоение невозможно, поскольку, в микропроцессорах серии 80x86 отсутствует адресация "память – память". Вот и приходится выполнять эту операцию в два этапа: "память à регистр" + "регистр à
память". Фактически компилятор генерирует следующий код:
register int tmp=a; mov eax, [ebp+var_4]
int b=tmp; mov [ebp+var_8], eax
где "tmp" – и есть временная переменная, создавая лишь на время выполнения операции "b=a", а затем уничтожаемая за ненадобностью.
Компиляторы (особенно оптимизирующие) всегда стремятся размещать временные переменные в регистрах, и только в крайних случаях заталкивают их в стек. Механизмы выделения памяти и способы чтения/записи временных переменных довольно разнообразны.
Сохранение переменных в стеке – обычная реакция компилятора на острый недостаток регистров. Целочисленные переменные чаще всего закидываются на вершину стека командой PUSH, а стягиваются оттуда командой POP. Встретив в тексте программы "тянитолкая" (инструкцию PUSH
в паре с соответствующей ей POP), сохраняющего содержимое инициализированного регистра, но не стековый аргумент функции (см. "Идентификация аргументов функции"), можно достаточно уверенно утверждать, что мы имеем дело с целочисленной временной переменной.
Выделение памяти под вещественные переменные и их инициализация в большинстве случаев происходят раздельно. Причина в том, что команды, позволяющей перебрасывать числа с вершины стека сопроцессора на вершину стека основного процессора, не существует и эту операцию приходится осуществлять вручную. Первым делом "приподнимается" регистр указатель вершины стека (обычно "SUB ESP, xxx"), затем в выделенные ячейки памяти записывается вещественное значение (обычно "FSTP [ESP]"), наконец, когда временная переменная становится не нужна, она удаляется из стека командой "ADD ESP, xxx" или подобной ей ("SUB, ESP, - xxx").
Подвинутые компиляторы (например, Microsoft Visual C++) умеют располагать временные переменные в аргументах, оставшихся на вершине стека после завершения последней вызванной функции. Разумеется, этот трюк применим исключительно к cdecl-, но не stdcall-функциям, ибо последние самостоятельно вычищают свои аргументы из стека (подробнее см. "Идентификация аргументов функций"). Мы уже сталкивались с таким приемом при исследовании механизма возврата значений функцией в главе "Идентификация значения, возвращаемого функцией".
Временные переменные размером свыше восьми байт (строки, массивы, структуры, объекты) практически всегда размешаются в стеке, заметно выделясь среди прочих типов своим механизмом инициализации – вместо традиционного MOV, здесь используется одна из команд циклической пересылки MOVSx, при необходимости предваренная префиксом повторения REP (Microsoft Visual C++, Borland C++), или несколько команд MOVSx
к ряду (WATCOM C).
Механизм выделения памяти под временные переменные практически идентичен механизму выделения памяти стековым локальным переменным, однако, никаких проблем идентификации не возникает. Во-первых, выделение памяти стековым переменным происходит сразу же после открытия кадра стека, а временным переменными – в любой точке функции. Во-вторых, временные переменные адресуются не через регистр указатель кадра стека, а через указатель вершины стека.
|
действие |
методы |
||
|
1й |
2й |
3й |
|
|
резервирование памяти |
PUSH |
SUB ESP, xxx |
использовать стековые аргументы >>># |
|
освобождение памяти |
POP |
ADD ESP, xxx |
|
|
запись переменной |
PUSH |
MOV [ESP+xxx], |
MOVS |
|
чтение переменной |
POP |
MOV , [ESP+xxx] |
передача вызываемой функции |
>>># Только в cdecl!
В каких же случаях компилятором создаются временные переменные? Вообще-то, это зависит от "нрава" самого компилятора (чужая душа – всегда потемки, а уж тем более – душа компилятора).
Однако можно выделить по крайней мере два случая, когда без создания временных переменных ну никак не обойтись: 1) при операциях присвоения, сложения, умножения; 2) в тех случаях, когда аргумент функции или член выражения – другая функция. Рассмотри оба случая подробнее.
::Создание временных переменных при пересылках данных и вычислении выражений. Как уже отмечалось выше, микропроцессоры серии 80x86 не поддерживают непосредственную пересылку данных из памяти в память, поэтому, присвоение одной переменной значения другой требует ввода временной регистровой переменной (при условии, что остальные переменные не регистровые).
Вычисление выражений (особенно сложных) так же требует временных переменных для хранения промежуточных результатов. Вот, например, сколько по-вашему требуется временных переменных для вычисления следующего выражения?
int a=0x1;int b=0x2;
int с= 1/((1-a) / (1-b));
Начнем со скобок, переписав их как: int tmp_d = 1; tmp_d=tmp_d-a; и int tmp_e=1; tmp_e=tmp_e-b; затем: int tmp_f = tmp_d / tmp_e; и наконец: tmp_j=1; c=tmp_j / tmp_f. Итого насчитываем…. раз, два, три, четыре, ага, четыре временных переменных. Не слишком ли много? Давайте попробуем записать это короче:
int tmp_d = 1;tmp_d=tmp_d-a; // (1-a);
int tmp_e=1; tmp_e=tmp_e-b; // (1-b);
tmp_d=tmp_d/tmp_e; // (1-a) / (1-b);
tmp_e=1; tmp_e=tmp_e/tmp_d;
Как мы видим, вполне можно обойтись всего двумя временными переменными – совсем другое дело! А, что если бы выражение было чуточку посложнее? Скажем, присутствовало бы десять пар скобок вместо трех, - сколько бы тогда потребовалось временных переменных? Нет, не соблазняйтесь искушением сразу же заглянуть в ответ, - попробуйте сосчитать это сами! Уже сосчитали? Да что там считать – каким сложным выражение ни было – для его вычисления вполне достаточно всего двух временных переменных. А если раскрыть скобки, то можно ограничится и одной, однако, это потребует излишних вычислений. Этот вопрос во всех подробностях мы рассмотрим в главе "___Идентификация выражений", а сейчас посмотрим, что за код сгенерировал компилятор:
mov [ebp+var_4], 1
mov [ebp+var_8], 2
mov [ebp+var_C], 3
; Инициализация локальных переменных
mov eax, 1
; Вот вводится первая временная переменная
; В нее записывается непосредственное значение, т.к. команда, вычитания SUB,
; в силу архитектурных особенностей микропроцессоров серии 80x86 всегда
; записывает результат вычисления на место уменьшаемого и потому
; уменьшаемое не может быть непосредственным значением, вот и приходится
; вводить временную переменную
sub eax, [ebp+var_4]
; tEAX
:= 1 – var_4
; в регистре EAX теперь хранится вычисленное значение (1-a)
mov ecx, 1
; Вводится еще одна временная переменная, поскольку EAX
трогать нельзя –
; он занят
sub ecx, [ebp+var_8]
; tECX
:= 1- var_8
; В регистре ECX теперь хранится вычисленное значение (1-b)
cdq
; Преобразуем двойное слово, лежащее в EAX
в четверное слово,
; помещаемое в EDX:EAX
; (машинная команда idiv всегда ожидает увидеть делимое именно в этих регистрах)
idiv ecx
; Делим (1-a) на (1-b), помещая частое в tEAX
; Прежнее значение временной переменной при этом неизбежно затирается, однако,
; для дальнейших вычислений оно и не нужно
; Вот и пускай себе затирается – не беда!
mov ecx, eax
; Копируем значение (1-a) / (1-b) в регистр ECX.
; Фактически, это новая временная переменная t2ECX, но в том же самом регистре
; (старое содержимое ECX нам так же уже не нужно)
; Индекс "2" после префикса "t" дан для того, чтобы показать, что t2ECX -
; вовсе не то же самое, что tECX, хотя обе эти временные переменные хранится
; в одном регистре
mov eax, 1
; Заносим в EAX непосредственное значение 1
; Это еще одна временная переменная – t2EAX
cdq
; Обнуляем EDX
idiv ecx
; Делим 1 на ((1-a) / (1-b))
; Частое помещается в EAX
mov [ebp+var_10], eax
; c := 1 / ((1-a) / (1-b))
; Итак, для вычисления данного выражения потребовалось четыре временных
; переменных и всего два регистра общего назначения
Листинг 118
::Создание временных переменных для сохранения значения, возращенного функцией, и результатов вычисления выражений. Большинство языков высокого уровня (в том числе и Си/Си++) допускают подстановку функций и выражений в качестве непосредственных аргументов. Например: "myfunc(a+b, myfunc_2(c))" Прежде, чем вызвать myfunc, компилятор должен вычислить значение выражения "a+b". Это легко, но возникает вопрос – во что записать результат сложения? Посмотрим, как с этим справится компилятор:
mov eax, [ebp+var_C]
; Создается временная переменная tEAX
и в нее копируется значение
; локальной переменной var_C
push eax
; Временная переменная tEAX сохраняется в стеке, передавая функции myfunc
; в качестве аргумента значение локальной переменной var_C
; Хотя, локальная переменная var_C
в принципе могла бы быть непосредственно
; передана функции – PUSH [ebp+var_4] и никаких временных переменных!
call myfunc
add esp, 4
; Функция myfunc возвращает свое значение в регистре EAX
; Его можно рассматривать как своего рода еще одну временную переменную
push eax
; Передаем функции myfunc_2 результат, возвращенный функцией myfunc
mov ecx, [ebp+var_4]
; Копируем в ECX значение локальной переменной var_4
; ECX
– еще одна временная переменная
; Правда, не совсем понятно почему компилятор не использовал регистр EAX,
; ведь предыдущая временная переменная ушла из области видимости и,
; стало быть, занимаемый ею регистр EAX
освободился...
add ecx, [ebp+var_8]
; ECX := var_4 + var_8
push ecx
; Передаем функции myfunc_2 сумму двух локальных переменных
call _myfunc_2
Листинг 119
Область видимости временных переменных. Временные переменные – это, в некотором роде, очень локальные переменные. Область их видимости в большинстве случаев ограничена несколькими строками кода, вне контекста которых временная переменная не имеет никакого смысла.По большому счету, временная переменная не имеет смысла вообще и только загромождает код. В самом деле, myfunc(a+b)
намного короче и понятнее, чем int tmp=a+b; myfunc(tmp). Поэтому, чтобы не засорять дизассемблерный листинг, стремитесь не употреблять в комментариях временные переменные, подставляя вместо них их фактические значения. Сами же временные переменные разумно предварять каким ни будь характерным префиксом, например, "tmp_" (или "t" если вы патологический любитель краткости). Например:
MOV EAX, [EBP+var_4] ; // var_8 := var_4
; ^ tEAX := var_4
ADD EAX, [EBP+var_8], ; ^ tEAX += var_8
PUSH EAX ; // MyFunc(var_4+var_8)
CALL MyFunc
Листинг 120
Идентификация стартовых функций
…чтобы не наделать ошибок в работе, богу понадобился свет. Судя по этому, в предшествовавшие века он сидел в полной темноте. К счастью, он не рисковал обо что-либо стукнуться, ибо вокруг ничего не было.
Лео Таксиль "Забавная Библия"
Если первого встречного программиста спросить "С какой функции начинается выполнение Windows-программы?", вероятнее всего мы услышим в ответ "С WinMain" и это будет ошибкой. На самом же деле, первым управление получает стартовый код, скрыто вставляемый компилятором, – выполнив необходимые инициализационные процедуры, в какой-то момент он вызывает WinMain, а после ее завершения вновь получает управление и выполняет "капитальную" деинициализацию.
В подавляющем большинстве случаев стартовый код не представляет никакого интереса и первой задачей анализирующего становится поиск функции WinMain. Если компилятор входит в число "знакомых" IDA, она опознает WinMain автоматически, в противном же случае это приходится делать руками и головой. Обычно в штатную поставку компилятора входят исходные тексты его библиотек, в том числе и процедуры стартового кода. Например, у Microsoft Visual C++ стартовый код расположен в файлах "CRT\STC\CRT0.C" – версия для статичной компоновки, "CRT\SRC\CRTEXE.C" – версия для динамичной компоновки (т.е. библиотечный код не пристыкуется к файлу, а вызывается из DLL), "CRT\SRC\wincmdln.c" – версия для консольных приложений. У Borland C++ все файлы со start-up кодом хранятся в отдельной одноименной директории, в частности, стартовый код для Windows-приложений содержится в файле "c0w.asm". Разобравшись с исходными текстами, понять дизассемблерный листинг будет намного легче!
А как быть, если для компиляции исследуемой программы использовался неизвестный или недоступный вам компилятор? Прежде, чем приступать к утомительному ручному анализу, давайте вспомним: какой прототип имеет функция WinMain:
int WINAPI WinMain(
HINSTANCE hInstance, // handle to current instance
HINSTANCE hPrevInstance, // handle to previous instance
LPSTR lpCmdLine, // pointer to command line
int nCmdShow // show state of window
);
Во-первых, четыре аргумента (см. "Идентификация аргументов функций") – это достаточно много и в большинстве случаев WinMain
оказывается самой "богатой" на аргументы функцией стартового кода. Во-вторых, последний заносимый в стек аргумент – hInstance – чаще всего вычисляется "на лету" вызовом GetModuleHandleA, - т.е. встретив конструкцию типа "CALL GetModuleHandleA" можно с высокой степенью уверенности утверждать, что следующая функция – и есть WinMain. Наконец, вызов WinMain обычно расположен практически в самом конце кода стартовой функции. За ней бывает не более двух-трех "замыкающих" строй функций таких как "exit" и "XcptFilter".
Рассмотрим следующий фрагмент кода. Сразу бросается в глаза множество инструкций PUSH, заталкивающих в стек аргументы, последний из которых передает результат завершения GetModuleHandleA. Значит, перед нами ни что иное, как вызов WinMain (и IDA подтверждает, что это именно так):
.text:00401804 push eax
.text:00401805 push esi
.text:00401806 push ebx
.text:00401807 push ebx
.text:00401808 call ds:GetModuleHandleA
.text:0040180E push eax
.text:0040180F call _WinMain@16
.text:00401814 mov [ebp+var_68], eax
.text:00401817 push eax
.text:00401818 call ds:exit
Листинг 21 Идентификация функции WinMain по роду и количеству передаваемых ей аргументов
Но не всегда все так просто, - многие разработчики, пользуясь наличием исходных текстов start-up кода, модифицируют его (под час весьма значительно). В результате – выполнение программы может начинаться не с WinMain, а любой другой функции, к тому же теперь стартовый код может содержать критические для понимания алгоритма программы операции (например, расшифровщик основного кода)! Поэтому, всегда
хотя бы мельком следует изучить start-up код – не содержит ли он чего-нибудь необычного?
Аналогичным образом обстоят дела и с динамическими библиотеками – их выполнение начинается вовсе не с функции DllMain (если она, конечно, вообще присутствует в DLL), а с __DllMainCRTStartup (по умолчанию). Впрочем, разработчики под час изменяют умолчания, назначая ключом "/ENTRY" ту стартовую функцию, которая им нужна. Строго говоря, неправильно называть DllMain стартовой функций – она вызывается не только при загрузке DLL, но так же и при выгрузке, и при создании/уничтожении подключившим ее процессором нового потока. Получая уведомления об этих событиях, разработчик может предпринимать некоторые действия (например, подготавливать код к работе в многопоточной среде). Весьма актуален вопрос – имеет ли все это значение для анализа программы? Ведь чаще всего требуется проанализировать не всю динамическую библиотеку целиком, а исследовать работу некоторых экспортируемых ею функций. Если DllMain выполняет какие-то действия, скажем, инициализирует переменные, то остальные функции, на которых распространяется влияние этих переменных, будут содержать на них прямые ссылки, ведущие прямиком к DllMain. Таким образом, не стоит вручную искать DllMain, - она сама себя обнаружит! Хорошо, если бы всегда это было так! Но жизнь сложнее всяких правил. Вдруг в DllMain находится некий деструктивный код или библиотека помимо основной своей деятельности шпионит за потоками, отслеживая их появление? Тогда без непосредственного анализа ее кода не обойтись!
Обнаружить DllMain на порядок труднее, чем WinMain, если ее не найдет IDA – пиши пропало. Во-первых, прототип DllMain достаточно незамысловат и не содержит ничего характерного:
BOOL WINAPI DllMain(
HINSTANCE hinstDLL, // handle to DLL module
DWORD fdwReason, // reason for calling function
LPVOID lpvReserved // reserved
);
А, во-вторых, ее вызов идет из самой гущи довольно внушительной функции __DllMainCRTStartup
и быстро убедиться, что это именно тот CALL, который нам нужен – нет никакой возможности. Впрочем, некоторые зацепки все-таки есть. Так, при неудачной инициализации DllMain возвращает FALSE, и код __DllMainCRTStartup обязательно проверит это значение, в случае чего прыгая аж к концу функции. Подробных ветвлений в теле стартовой функции не так уж много и обычно только одно из них связано с функций, принимающей три аргумента.
.text:1000121C push edi
.text:1000121D push esi
.text:1000121E push ebx
.text:1000121F call _DllMain@12
.text:10001224 cmp esi, 1
.text:10001227 mov [ebp+arg_4], eax
.text:1000122A jnz short loc_0_10001238
.text:1000122C test eax, eax
.text:1000122E jnz short loc_0_10001267
Листинг 22 Идентификация DllMain по коду неудачной инициализации
Прокрутив экран немного вверх, нетрудно убедиться, что регистры EDI, ESI и EBX содержат lpvReserved, fdwReason и hinstDLL соответственно. А значит, перед нами и есть функция DllMain (Для справки, исходный текст __DllMainCRTStartup содержится в файле "dllcrt0.c", который настоятельно рекомендуется изучить).
Наконец, мы добрались и до функции main
консольных Windows-приложений. Как всегда, выполнение программы начинается не с нее, а c функции mainCRTStartup, инициализирующей кучу, систему ввода-вывода, подготавливающую аргументы командной строки и только потом предающей управление main. Функция main
принимает всего два аргумента: "int main(int argc, char **argv)" – этого слишком мало, чтобы выделить ее среди остальных. Однако приходит на помощь тот факт, что ключи командной строки доступны не только через аргументы, но и через глобальные переменные – __argc
и __argv
соответственно. Поэтому, вызов main обычно выглядит так:
.text:00401293 push dword_0_407D14
.text:00401299 push dword_0_407D10
.text:0040129F call _main
.text:0040129F ; Смотрите: оба аргумента функции – указатели на глобальные переменные
.text:0040129F ; (см. "Идентификация глобальных переменных")
.text:0040129F
.text:004012A4 add esp, 0Ch
.text:004012A7 mov [ebp+var_1C], eax
.text:004012AA push eax
.text:004012AA ; Смотрите: возвращаемое функцией знаечние, передается функции exit
.text:004012AA ; как код завершения процесса
.text:004012AA ; Значит, это и main и есть!
.text:004012AA
.text:004012AB call _exit
Листинг 23 Идентификация main
Обратите внимание и на то, что результат завершения main
передается следующей за ней функции (это, как правило, библиотечная функция exit).
Вот мы и разобрались с идентификацией основных типов стартовых функций. Конечно, в жизни бывает не все так просто, как в теории, но в любом случае, описанные выше приемы заметно упростят анализ.
__дописать идентификацию стартовых функций FreePascal, Fortran….
Идентификация switch – case – break
"…когда вы видите все целиком, то у вас нет выбора, вам не из чего выбирать. Тогда вы имеете два пути одновременно, следуете одновременно этим двум направлениям"
Ошо "Пустая лодка" Беседы по высказываниям Чжуан Цзы
Для улучшения читабельности программ в язык Си был введен оператор множественного выбора – switch. В Паскале с той же самой задачей справляется оператор CASE, кстати, более гибкий, чем его Си-аналог, но об их различиях мы поговорим попозже.
Легко показать, что switch эквивалентен конструкции "IF (a == x1) THEN оператор1
ELSE IF (a == x2) THEN оператор2
IF (a == x2) THEN оператор2
IF (a == x2) THEN оператор2 ELSE …. оператор по умолчанию". Если изобразить это ветвление в виде логического дерева, то образуется характерная "косичка", прозванная так за сходство с завитой в косу прядью волос – см. рис. 29
Казалось бы, идентифицировать switch никакого труда не составит, – даже не стоя дерева, невозможно не обратить внимания на длинную цепочку гнезд, проверяющих истинность условия равенства некоторой переменной с серией непосредственных значений (сравнения переменной с другой переменной switch не допускает).
Рисунок 29 0х01С Трансляция оператора switch в общем случае
Однако в реальной жизни все происходит совсем не так. Компиляторы (даже не оптимизирующие) транслируют switch в настоящий "мясной рулет", доверху нашпигованных всевозможными операциями отношений. Давайте, откомпилируем приведенный выше пример компилятором Microsoft Visual C++ и посмотрим, что из этого выйдет:
main proc near ; CODE XREF: start+AFp
var_tmp = dword ptr -8
var_a = dword ptr –4
push ebp
mov ebp, esp
; Открываем кадр стека
sub esp, 8
; Резервируем место для локальных переменных
mov eax, [ebp+var_a]
; Загружаем в EAX значение переменной var_a
mov [ebp+var_tmp], eax
; Обратите внимание – switch создает собственную временную переменную!
; Даже если значение сравниваемой переменной в каком-то ответвлении CASE
; будет изменено, это не повлияет на результат выборов!
; В дальнейшем во избежании путаницы, мы будем условно называть
; переменную var_tmp
переменной var_a
cmp [ebp+var_tmp], 2
; Сравниваем значение переменной var_a с двойкой
; Хм-хм, в исходном коде CASE начинался с нуля, а заканчивался 0x666
; Причем же тут двойка?!
jg short loc_401026
; Переход, если var_a
> 2
; Обратите на этот момент особое внимание – ведь в исходном тексте такой
; операции отношения не было!
; Причем, этот переход не ведет к вызову функции printf, т.е. этот фрагмент
; кода получен не прямой трансляцией некой ветки case, а как-то иначе!
cmp [ebp+var_tmp], 2
; Сравниваем значение var_a
с двойкой
; Очевидный "прокол" компилятора – мы же только что проделывали эту
; операции, и с того момента не меняли никакие флаги!
jz short loc_40104F
; Переход к вызову printf("a == 2"), если var_a
== 2
; ОК, этот код явно получен трансляцией ветки CASE 2: printf("a == 2")
cmp [ebp+var_tmp], 0
; Сравниваем var_a
с нулем
jz short loc_401031
; Переход к вызову printf("a == 0"), если var_a
== 0
; Этот код получен трансляцией ветки CASE 0: printf("a == 0")
cmp [ebp+var_tmp], 1
; Сравниваем var_a
с единицей
jz short loc_401040
; Переход к вызову printf("a == 1"), если var_a
== 1
; Этот код получен трансляцией ветки CASE 1: printf("a == 1")
jmp short loc_40106D
; Переход к вызову printf("Default")
; Этот код получен трансляцией ветки Default: printf("a == 0")
loc_401026: ; CODE XREF: main+10j
; Эта ветка получает управление, если var_a > 2
cmp [ebp+var_tmp], 666h
; Сравниваем var_a
со значением 0x666
jz short loc_40105E
; Переход к вызову printf("a == 666h"), если var_a
== 0x666
; Этот код получен трансляцией ветки CASE 0x666: printf("a == 666h")
jmp short loc_40106D
; Переход к вызову printf("Default")
; Этот код получен трансляцией ветки Default: printf("a == 0")
loc_401031: ; CODE XREF: main+1Cj
; // printf("A == 0")
push offset aA0 ; "A == 0"
call _printf
add esp, 4
jmp short loc_40107A
; ^^^^^^^^^^^^^^^^^^^^^^ - а вот это оператор break, выносящий управление
; за пределы switch – если бы его не было, то начали бы выполняться все
; остальные ветки CASE, не зависимо от того, к какому значению var_a они
; принадлежат!
loc_401040: ; CODE XREF: main+22j
; // printf("A == 1")
push offset aA1 ; "A == 1"
call _printf
add esp, 4
jmp short loc_40107A
; ^ break
loc_40104F: ; CODE XREF: main+16j
; // printf("A == 2")
push offset aA2 ; "A == 2"
call _printf
add esp, 4
jmp short loc_40107A
; ^ break
loc_40105E: ; CODE XREF: main+2Dj
; // printf("A == 666h")
push offset aA666h ; "A == 666h"
call _printf
add esp, 4
jmp short loc_40107A
; ^ break
loc_40106D: ; CODE XREF: main+24j main+2Fj
; // printf("Default")
push offset aDefault ; "Default"
call _printf
add esp, 4
loc_40107A: ; CODE XREF: main+3Ej main+4Dj ...
; // КОНЕЦ SWITCH
mov esp, ebp
pop ebp
; Закрываем кадр стека
retn
main endp
Листинг 173
Построив логическое дерево (см. "Идентификация IF – THEN – ELSE"), мы получим следующую картину (см. рис. 30). При ее изучении бросается в глаза, во-первых, условие "a >2", которого не было в исходной программе, а во-вторых, изменение порядка обработки case. В то же время, вызовы функций printf следуют один за другим строго согласно их объявлению.
Зачем же компилятор так чудит? Чего он рассчитывает этим добиться?
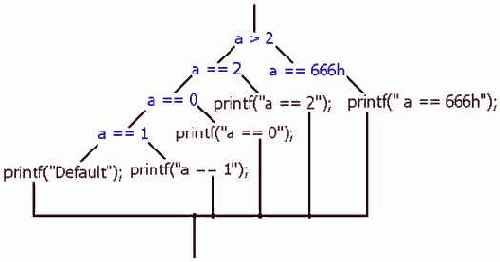
Рисунок 30 0x01D Пример трансляция оператора switch компилятором Microsoft Visual C
Назначение гнезда (a > 2) объясняется очень просто – последовательная обработка всех операторов case крайне непроизводительная. Хорошо, если их всего четыре-пять штук, а если программист натолкает в switch сотню - другую case? Процессор совсем запарится, пока их все проверит (а по закону бутерброда нужный case будет в самом конце). Вот компилятор и "утрамбовывает" дерево, уменьшая его высоту. Вместо одной ветви, изображенной на рис. 30, транслятор в нашем случае построил две, поместив в левую только числа не большие двух, а в правую – все остальные. Благодаря этому, ветвь "666h" из конца дерева была перенесена в его начало. Данный метод оптимизации поиска значений называют "методом вилки", но не будет сейчас на нем останавливаться, а лучше разберем его в главе "Обрезка длинных деревьев".
Изменение порядка сравнений – право компилятора. Стандарт ничего об этот не говорит и каждая реализация вольна поступать так, как ей это заблагорассудится. Другое дело – case-обработчики (т.е. тот код, которому case передает управление в случае истинности отношения). Они обязаны располагаться так, как были объявлены в программе, т.к. при отсутствии закрывающего оператора break они должны выполняться строго в порядке, замышленном программистом, хотя эта возможность языка Си используется крайне редко.
Таким образом, идентификация оператора switch
не сильно усложняется: если после уничтожения узлового гнезда и прививки правой ветки к левой (или наоборот) мы получаем эквивалентное дерево, и это дерево образует характерную "косичку" – мы имеем дело с оператором множественного выбора или его аналогом.
Весь вопрос в том: правомерны ли мы удалять гнездо, не нарушит ли эта операция структуры дерева? Смотрим – на левой ветке узлового гнезда расположены гнезда (a == 2), (a == 0) и (a == 1), а на левом – (a==0x666) Очевидно, если a == 0x666, то a != 0 и a != 1! Следовательно, прививка правой ветки к левой вполне безопасна и после такого преобразования дерево принимает вид типичный для конструкции switch (см.
рис. 31 ).
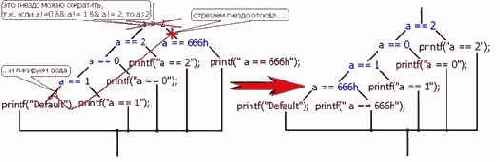
Рисунок 31 0x01E Усечение логического дерева
Увы, такой простой прием идентификации срабатывает не всегда! Иные компиляторы такого наворотят, что волосы в разных местах дыбом встанут! Если откомпилировать наш пример компилятором Borland C++ 5.0, то код будет выглядеть так:
; int __cdecl main(int argc,const char **argv,const char *envp)
_main proc near ; DATA XREF: DATA:00407044o
push ebp
mov ebp, esp
; Открываем кадр стека
; Компилятор помещает нашу переменную a в регистр EAX
; Поскольку она не была инициализирована, то заметить этот факт
; не так-то легко!
sub eax, 1
; Уменьшает EAX на единицу! Что бы этого значило, хвост Тиггера?
; Никакого вычитания в нашей программе не было!
jb short loc_401092
; Если EAX < 1, то переход на вызов printf("a == 0")
; (мы ведь помним, что CMP та же команда SUB, только не изменяющая операндов?)
; Ага, значит, этот код сгенерирован в результате трансляции
; ветки
CASE 0: printf("a == 0");
; Внимание! задумайтесь: какие значения может принимать EAX, чтобы
; удовлетворять условию этого отношения? На первый взгляд, EAX < 1,
; в частости, 0, -1, -2,… СТОП! Ведь jb – это беззнаковая инструкция
; сравнения! А –0x1 в беззнаковом виде выглядит как 0xFFFFFFFF
; 0xFFFFFFFF много больше единицы, следовательно, единственным подходящим
; значением будет ноль
; Таким образом, данная конструкция – просто завуалированная проверка EAX на
; равенство нулю! (Ох! и хитрый же этот Borland – компилятор!)
;
jz short loc_40109F
; Переход, если установлен флаг нуля
; Он будет он установлен в том случае, если EAX
== 1
; И действительно переход идет на вызов printf("a == 1")
dec eax
; Уменьшаем EAX на единицу
jz short loc_4010AC
; Переход если установлен флаг нуля, а он будет установлен когда после
; вычитания единицы командой SUB, в EAX останется ровно единица,
; т.е. исходное значение EAX должно быть равно двум
; И точно – управление передается ветке вызова printf("a == 2")!
sub eax, 664h
; Отнимаем от EAX число 0x664
jz short loc_4010B9
; Переход, если установлен флаг нуля, т.е. после двукратного уменьшения EAX
; равен 0x664, следовательно, исходное значение – 0x666
jmp short loc_4010C6
; прыгаем на вызов printf("Default"). Значит, это – конец switch
loc_401092: ; CODE XREF: _main+6j
; // printf("a==0");
push offset aA0 ; "a == 0"
call _printf
pop ecx
jmp short loc_4010D1
loc_40109F: ; CODE XREF: _main+8j
; // printf("a==1");
push offset aA1 ; "a == 1"
call _printf
pop ecx
jmp short loc_4010D1
loc_4010AC: ; CODE XREF: _main+Bj
; // printf("a==2");
push offset aA2 ; "a == 2"
call _printf
pop ecx
jmp short loc_4010D1
loc_4010B9: ; CODE XREF: _main+12j
; // printf("a==666");
push offset aA666h ; "a == 666h"
call _printf
pop ecx
jmp short loc_4010D1
loc_4010C6: ; CODE XREF: _main+14j
; // printf("Default");
push offset aDefault ; "Default"
call _printf
pop ecx
loc_4010D1: ; CODE XREF: _main+21j _main+2Ej ...
xor eax, eax
pop ebp
retn
_main endp
Листинг 174
Код, сгенерированный компилятором, модифицирует сравниваемую переменную в процессе сравнения! Оптимизатор посчитал, что DEC EAX
короче, чем сравнение с константой, да и работает шустрее. Вот только нам, хакером, от этого утешения ничуть не легче! Ведь прямая ретрансляция кода (см. "Идентификация IF – THEN – ELSE") дает конструкцию вроде: "if (a-- == 0) printf("a == 0"); else if (a==0) printf("a == 1"); else if (--a == 0) printf("a == 2"); else if ((a-=0x664)==0) printf("a == 666h); else printf("Default")", - в которой совсем не угадывается оператор switch! Впрочем, почему это "не угадывается"?! Угадывается, еще как! Где есть длинная цепочка "IF-THEN-ELSE-IF-THEN-ELSE…" там и до switch-а недалеко! Узнать оператор множественного выбора будет еще легче, если изобразить его в виде дерева – смотрите (см.
рис. 32) вот она, характерная "косичка"!
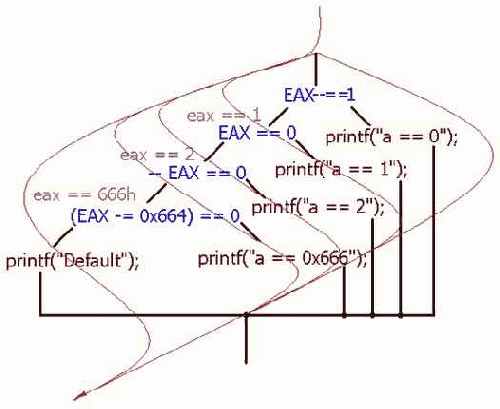
Рисунок 32 0x01F Построение логического дерева с гнездами, модифицирующими саму сравниваемую переменную
Другая характерная деталь – case-обработчики, точнее оператор break традиционно замыкающий каждый из них. Они-то и образуют правую половину "косички", сходясь все вместе с точке "Z". Правда, многие программисты питают паралогическую любовь к case-обработчикам размером в два-три экрана, включая в них помимо всего прочего и циклы (о них речь еще впереди – см. "Идентификация for\while"), и ветвления, и даже вложенные операторы множественно выбора! В результате правая часть "косички" превращается в непроходимый таежный лес, сквозь который не проберется и стадо слонопотамов. Но даже если и так – левая часть "косички", все равно останется достаточно простой и легко распознаваемой!
В заключение темы рассмотрим последний компилятор – WATCOM C. Как и следует ожидать, здесь нас подстерегают свои тонкости и "вкусности". Итак, откомпилированный им код предыдущего примера должен выглядеть так:
main_ proc near ; CODE XREF: __CMain+40p
push 8
call __CHK
; Проверка стека на переполнение
cmp eax, 1
; Сравнение регистровой переменной EAX, содержащей в себе переменную a
; со значением 1
jb short loc_41002F
; Если EAX == 0, то переход к ветви с дополнительными проверками
jbe short loc_41003A
; Если EAX == 1 (т.е. условие bellow уже обработано выше), то переход
; к ветке вызова printf("a == 1");
cmp eax, 2
; Сравнение EAX со значением 2
jbe short loc_410041
; Если EAX == 2 (условие EAX <2 уже было обработано выше), то переход
; к ветке вызова printf("a == 2");
cmp eax, 666h
; Сравнение EAX со значением 0x666
jz short loc_410048
; Если EAX == 0x666, то переход к ветке вызова printf("a == 666h");
jmp short loc_41004F
; Что ж, ни одно из условий не подошло – переходит к ветке "Default"
loc_41002F: ; CODE XREF: main_+Dj
; // printf("a == 0");
test eax, eax
jnz short loc_41004F
; Совершенно непонятно – зачем здесь дополнительная проверка?!
; Это ляп компилятора – она ни к чему!
push offset aA0 ; "A == 0"
; Обратите внимание – WATCOM сумел обойтись всего одним вызовом printf!
; Обработчики case всего лишь передают ей нужный аргумент!
; Вот это действительно – оптимизация!
jmp short loc_410054
loc_41003A: ; CODE XREF: main_+Fj
; // printf("a == 1");
push offset aA1 ; "A == 1"
jmp short loc_410054
loc_410041: ; CODE XREF: main_+14j
; // printf("a == 2");
push offset aA2 ; "A == 2"
jmp short loc_410054
loc_410048: ; CODE XREF: main_+1Bj
; // printf("a == 666h");
push offset aA666h ; "A == 666h"
jmp short loc_410054
loc_41004F: ; CODE XREF: main_+1Dj main_+21j
; // printf("Default");
push offset aDefault ; "Default"
loc_410054: ; CODE XREF: main_+28j main_+2Fj ...
call printf_
; А вот он наш printf, получающий аргументы из case-обработчиков!
add esp, 4
; Закрытие кадра стека
retn
main_ endp
Листинг 175
В общем, WATCOM генерирует более хитрый, но, как ни странно, весьма наглядный и читабельный код.
::Отличия switch от оператора case языка Pascal. Оператор CASE языка Pascal практически идентичен своему Си собрату – оператору switch, хотя и близнецами их не назовешь: оператор CASE выгодно отличается поддержкой наборов и диапазонов значений. Ну, если обработку наборов можно реализовать и посредством switch, правда не так элегантно как на Pascal (см.
листинг 176), то проверка вхождения значения в диапазон на Си организуется исключительно с помощью конструкции "IF-THEN-ELSE". Зато в Паскале каждый case-обработчик принудительно завершается неявным break, а Си-программист волен ставить (или не ставить) его по своему усмотрению.
CASE a OF switch(a)
begin {
1 : WriteLn('a == 1'); case 1 : printf("a == 1");
break;
2,4,7 : WriteLn('a == 2|4|7'); case 2 :
case 4 :
case 7 : printf("a == 2|4|7");
break;
9 : WriteLn('a == 9'); case 9 : printf("a == 9");
break;
end;
Листинг 176
Однако оба языка накладывают жесткое ограничение на выбор сравниваемой переменной: она должна принадлежать к перечисленному типу, а все наборы (диапазоны) значений представлять собой константы или константные выражения, вычисляемые на стадии компиляции. Подстановка переменных или вызовов функций не допускается.
Представляет интерес посмотреть: как Pascal транслирует проверку диапазонов и сравнить его с компиляторами Си. Рассмотрим следующий пример:
VAR
a : LongInt;
BEGIN
CASE a OF
2 : WriteLn('a == 2');
4, 6 : WriteLn('a == 4 | 6 ');
10..100 : WriteLn('a == [10,100]');
END;
END.
Листинг 177
Результат его компиляции компилятором Free Pascal должен выглядеть так (для экономии места приведена лишь левая часть "косички"):
mov eax, ds:_A
; Загружаем в EAX значение сравниваемой переменной
cmp eax, 2
; Сравниваем EAX со значением 0х2
jl loc_CA ; Конец CASE
; Если EAX < 2, то – конец CASE
sub eax, 2
; Вычитаем из EAX значение 0x2
jz loc_9E ; WriteLn('a == 2');
; Переход на вызов WriteLn('a
== 2') если EAX
== 2
sub eax, 2
; Вычитаем из EAX значение 0x2
jz short loc_72 ; WriteLn('a == 4 | 6');
; Переход на вызов WriteLn(''a == 4 | 6') если EAX == 2 (соотв. a == 4)
sub eax, 2
; Вычитаем из EAX значение 0x2
jz short loc_72 ; WriteLn('a == 4 | 6');
; Переход на вызов WriteLn(''a == 4 | 6') если EAX == 2 (соотв. a == 6)
sub eax, 4
; Вычитаем из EAX значение 0x4
jl loc_CA ; Конец CASE
; Переход на конец CASE, если EAX < 4 (соотв. a < 10)
sub eax, 90
; Вычитаем из EAX значение 90
jle short loc_46 ; WriteLn('a = [10..100]');
; Переход на вызов WriteLn('a
= [10..100]') если EAX
<= 90 (соотв. a
<= 100)
; Поскольку, случай a > 10 уже был обработан выше, то данная ветка
; срабатывает при условии a>=10 && a<=100.
jmp loc_CA ; Конец CASE
; Прыжок на конец CASE – ни одно из условий не подошло
Листинг 178
Как видно, Free Pascal генерирует практически тот же самый код, что и компилятор Borland C++ 5.х, поэтому его анализ не должен вызвать никаких сложностей.
__::IDA распознает switch
::Обрезка (балансировка) длинных деревьев. В некоторых (хотя и редких) случаях, операторы множественного выбора содержат сотни (а то и тысячи) наборов значений, и если решать задачу сравнения "в лоб", то высота логического дерева окажется гигантской до неприличия, а его прохождение займет весьма длительное время, что не лучшим образом скажется на производительности программы.
Но, задумайтесь: чем собственно занимается оператор switch? Если отвлечься от устоявшейся идиомы "оператор SWITCH дает специальный способ выбора одного из многих вариантов, который заключается в проверке совпадения значения данного выражения с одной из заданных констант и соответствующем ветвлении", то можно сказать, что switch – оператор поиска соответствующего значения. В таком случае каноническое switch - дерево представляет собой тривиальный алгоритм последовательного поиска – самый неэффективный алгоритм из всех.
Пусть, например, исходный текст программы выглядел так:
switch (a)
{
case 98 : …;
case 4 : …;
case 3 : …;
case 9 : …;
case 22 : …;
case 0 : …;
case 11 : …;
case 666: …;
case 096: …;
case 777: …;
case 7 : …;
}
Листинг 179
Тогда соответствующее ему не оптимизированное логическое дерево будет достигать в высоту одиннадцати гнезд (см. рис. 33 слева). Причем, на левой ветке корневого гнезда окажется аж десять других гнезд, а на правой – вообще ни одного (только соответствующий ему case - обработчик).
Исправить "перекос" можно разрезав одну ветку на две и привив образовавшиеся половинки к новому гнезду, содержащему условие, определяющее в какой из веток следует искать сравниваемую переменную. Например, левая ветка может содержать гнезда с четными значениями, а правая – с нечетными. Но это плохой критерий: четных и нечетных значений редко бывает поровну и вновь образуется перекос. Гораздо надежнее поступить так: берем наименьшее из всех значений и бросаем его в кучу А, затем берем наибольшее из всех значений и бросаем его в кучу B. Так повторяем до тех пор, пока не рассортируем все, имеющиеся значения.
Поскольку оператор множественного выбора требует уникальности каждого значения, т.е. каждое число может встречаться в наборе (диапазоне) значений лишь однажды, легко показать, что: а) в обеих кучах будет содержаться равное количество чисел (в худшем случае – в одной куче окажется на число больше); б) все числа кучи A меньше наименьшего из чисел кучи B. Следовательно, достаточно выполнить только одно сравнение, чтобы определить в какой из двух куч следует искать сравниваемое значения.
Высота нового дерева будет равна , где N – количество гнезд старого дерева. Действительно, мы же ветвь дерева надвое и добавляем новое гнездо – отсюда и берется и +1, а (N+1) необходимо для округления результата деления в большую сторону. Т.е. если высота не оптимизированного дерева достигала 100 гнезд, то теперь она уменьшилась до 51. Что? Говорите, 51 все равно много? А что нам мешает разбить каждую из двух ветвей еще на две? Это уменьшит высоту дерева до 27 гнезд! Аналогично, последующее уплотнение даст 16 à
12 à
11 à
9 à
8… и все! Более плотная упаковка дерева невозможна (подумайте почему – на худой конец постройте само дерево). Но, согласитесь, восемь гнезд – это не сто! Полное прохождение оптимизированного дерева потребует менее девяти сравнений!
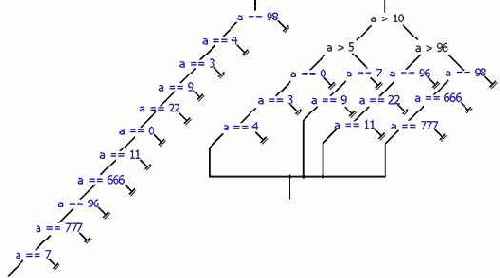
Рисунок 33 0х21 Логическое дерево до утрамбовки (слева) и после (справа)
"Трамбовать" логические деревья оператора множественного выбора умеют практически все компиляторы – даже не оптимизирующие! Это увеличивает производительность, но затрудняет анализ откомпилированной программы. Взгляните еще раз на рис. 33 – левое несбалансированное дерево наглядно и интуитивно - понятно. После же балансировки (правое дерево) в нем Тиггер хвост обломит.
К счастью, балансировка дерева допускает эффективное обращение. Но прежде, чем засучить рукава и приготовиться к лазанью по деревьям (а Тиггеры по деревьям лазают лучше всех!) введем понятие балансировочного узла. Балансировочный узел не изменяет логики работы двоичного дерева и являются факультативным узлов, единственная функция которого укорачивание длины ветвей. Балансировочный узел без потери функциональности дерева может быть замещен любой из своих ветвей. Причем каждая ветвь балансировочного узла должна содержать одно или более гнезд.
Рассуждая от противного – все узлы логического дерева, правая ветка которых содержит одно или более гнезд, могут быть замещены на эту самую правую ветку без потери функциональности дерева, то данная конструкция представляет собой оператор switch. Почему именно правая ветка? Так ведь оператор множественного выбора в "развернутом" состоянии представляет цепочку гнезд, соединенных левыми ветвями друг с другом, а на правых держащих case-обработчики, - вот мы и пытаемся подцепить все правые гнезда на левую ветвь. Если это удается, мы имеем дело с оператором множественного выбора, а нет – с чем-то другим.
Рассмотрим обращение балансировки на примере следующего дерева (см. рис. 34 слева).
Двигаясь от левой нижней ветви, мы будем продолжать взбираться на дерево до тех пор, пока не встретим узел, держащий на своей правой ветви одно или более гнезд. В нашем случае – это узел (a > 5). Смотрите: если данный узел заменить его гнездами (a==7) и (a == 9) функциональность дерева не нарушиться! (см. рис. 34 посередине). Аналогично узел (a > 10) может быть безболезненно заменен гнездами (a > 96), (a == 96), (a == 22) и (a == 11), а узел (a > 96) в свою очередь – гнездами (a == 98), (a == 666) и (a == 777). В конце -концов образуется классическое switch-дерево, в котором оператор множественного выбора распознается с первого взгляда.
Рисунок 34 0x22 Обращение балансировки логического дерева
Сложные случаи балансировки или оптимизирующая балансировка. Для уменьшения высоты "утрамбовываемого" дерева хитрый трансляторы стремятся замещать уже существующие гнезда балансировочными узлами. Рассмотрим следующий пример: (см. рис. 35). Для уменьшения высоты дерева транслятор разбивает его на две половины – в левую идут гнезда со значениями меньшие или равные единицы, а в правую – все остальные. Казалось бы, на правой ветке узла (a > 1) должно висеть гнездо (a == 2), ан нет! Здесь мы видим узел (a >2), к левой ветки которого прицеплен case-обработчик :2! А что, вполне логично – если (a > 1) и !(a > 2), то a == 2!
Легко видеть, что узел (a > 2) жестко связан с узлом (a > 1) и работает на пару с последним. Нельзя выкинуть один из них, не нарушив работоспособности другого! Обратить балансировку дерева по описанному выше алгоритму без нарушения его функциональности невозможно! Отсюда может создаться мнение, что мы имеем дело вовсе не с оператором множественного выбора, а чем-то другим.
Чтобы развеять это заблуждение придется предпринять ряд дополнительных шагов. Первое – у switch-дерева все case-обработчики всегда находятся на правой ветви. Смотрим – можно ли трансформировать наше дерево так, чтобы case-обработчик 2 оказался на левой ветви балансировочного узла? Да, можно: заменив (a > 2) на (a < 3) и поменяв ветви местами (другими словами выполнив инверсию).
Второе – все гнезда switch-дерева содержат в себе условия равенства, - смотрим: можем ли мы заменить неравенство (a < 3) на аналогичное ему равенство? Ну, конечно же, можем – (a == 2)!
Вот, после всех этих преобразований, обращение балансировки дерева удается выполнить без труда!
Рисунок 35 0x23 Хитрый случай балансировки
Ветвления в case-обработчиках. В реальной жизни case-обработчики прямо-таки кишат ветвлениями, циклами и прочими условными переходами всех мастей. Как следствие – логическое дерево приобретает вид ничуть не напоминающий оператор множественного выбора, а скорее смахивающий на заросли чертополоха, так любимые И-i. Понятное дело – идентифицировав case-обработчики, мы могли бы решить эту проблему, но как их идентифицировать?!
Очень просто – за редкими клиническими исключениями, case-обработчики не содержат ветвлений относительно сравниваемой переменной. Действительно, конструкции "switch(a) …. case 666 : if (a == 666) …." или "switch(a) …. case 666 : if (a > 66) …." абсолютно лишены смысла. Таким образом, мы можем смело удалить из логического дерева все гнезда с условиями, не касающимися сравниваемой переменной (переменной коневого гнезда).
Хорошо, а если программист в порыве собственной глупости или стремлении затруднить анализ программы "впаяет" в case-обработчики ветвления относительно сравниваемой переменной?! Оказывается, это ничуть не затруднит анализ! "Впаянные" ветвления элементарно распознаются и обрезаются либо как избыточные, либо как никогда не выполняющиеся. Например, если к правой ветке гнезда (a == 3) прицепить гнездо (a > 0) – его можно удалить, как не несущее в себе никакой информации. Если же к правой ветке того же самого гнезда прицепить гнездо (a == 2) его можно удалить, как никогда не выполняющееся – если a == 3, то заведомо a != 2!
Идентификация this
"Не все ли равно, о чем спрашивать, если ответа все равно не получишь, правда?"
Льюис Кэрролл. Алиса в стране чудес
Указатель this – это настоящий "золотой ключик" или, если угодно, "спасательный круг", позволяющей не утонуть в бурном океане ООП. Именно благодаря this возможно определять принадлежность вызываемой функции к тому или иному экземпляру объекта. Поскольку, все не виртуальные функции объекта вызываются непосредственно - по фактическому адресу, объект как бы "расщепляется" на составляющие его функции еще на стадии компиляции. Не будь указателей this – восстановить иерархию функций было бы принципиально невозможно!
Таким образом, правильная идентификация this очень важна. Единственная проблема – как его отличить от указателей на массивы и структуры? Ведь идентификация экземпляра объекта осуществляется по указателю this (если на выделенную память указывает this, это – экземпляр объекта), однако, сам this по определению это указатель, ссылающийся на экземпляр объекта. Замкнутый круг! К счастью, есть одна лазейка… Код, манипулирующий указателем this, весьма специфичен, что и позволяет отличить this ото всех остальных указателей.
Вообще-то, у каждого компилятора свой "почерк", который настоятельно рекомендуется изучить, дизассемблируя собственные Cи++ программы, но существуют и универсальные рекомендации, приемлемые к большинству реализацией. Поскольку, this – это неявной аргумент каждой функции-члена класса, то логично отложить разговор о его идентификации до главы "Идентификация аргументов функций", здесь же мы дадим лишь краткую сводную таблицу, описывающую механизмы передачи this различными компиляторами:
| Компилятор | тип функции | ||||||||
| Default | fastcall | cdecl | stdcall | PASCAL | |||||
| Microsoft Visual C++ | ECX | через стек последним аргументом функции | через стек первым аргументом | ||||||
| Borland C++ | EAX | ||||||||
| WATCOM C |
Таблица 1 Механизм передачи указателя this в зависимости от реализации компилятора и типа функции
Идентификация виртуальных функций
А мы летим орбитами, путями неизбитыми,Прошит метеоритами простор.Оправдан риск и мужество, космическая музыка
Вплывает в деловой наш разговор.
"Трава у дома" Земляне
Виртуальная функция по определению обозначает "определяемая по время выполнения программы". При вызове виртуальной функции выполняемый код должен соответствовать динамическому типу объекта, из которого вызывается функция. Поэтому, адрес виртуальной функции не может быть определен на стадии компиляции – это приходится делать непосредственно в момент ее вызова. Вот почему вызов виртуальной функции – всегда косвенный
вызов (исключение составляют лишь виртуальные функции статических объектов, - см. "Статическое связывание").
В то время как не виртуальные функции вызываются в точности так же, как и обычные Си-функции, вызов виртуальных функций кардинально отличается. Конкретная схема зависит от реализации конкретного компилятора, но общем случае ссылки на все виртуальные функции помещаются в специальный массив – виртуальную таблицу (virtual table –
сокращенно VTBL), а в каждый экземпляр объекта, использующий хотя бы одну виртуальную функцию, помещается указатель на виртуальную таблицу (virtual table pointer – сокращенно VPRT). Причем, независимо от числа виртуальный функций, каждый объект имеет только один указатель.
Вызов виртуальных функций всегда происходит косвенно, через ссылку на виртуальную таблицу – например: CALL [EBX+0х10], где EBX
– регистр, содержащий смещение виртуальной таблицы в памяти, а 0x10 – смещение указателя на виртуальную функцию внутри виртуальной таблицы.
Анализ вызова виртуальных функций наталкивается на ряд сложностей, самая коварная из которых, – необходимость обратной трассировки кода для отслеживания значения регистра, используемого для косвенной адресации. Хорошо, если он инициализируется непосредственным значением типа "MOV EBX, offset VTBL" недалеко от места использования, но значительно чаще указатель на VTBL передается функции как неявный аргумент или (что еще хуже) один и тот же указатель используется для вызова двух различных виртуальных функций и возникает неопределенность – какое именно значение (значения) он имеет в данной ветке программы?
Разберем следующий пример ( предварительно вспомнив, что если одна и та же не виртуальная функция присутствует и базовом, и в производном классе – всегда вызывается функция базового класса).
#include <stdio.h>
class Base{
public:
virtual void demo(void)
{
printf("BASE\n");
};
virtual void demo_2(void)
{
printf("BASE DEMO 2\n");
};
void demo_3(void)
{
printf("Non virtual BASE DEMO 3\n");
};
};
class Derived: public Base{
public:
virtual void demo(void)
{
printf("DERIVED\n");
};
virtual void demo_2(void)
{
printf("DERIVED DEMO 2\n");
};
void demo_3(void)
{
printf("Non virtual DERIVED DEMO 3\n");
};
};
main()
{
Base *p = new Base;
p->demo();
p->demo_2();
p->demo_3();
p = new Derived;
p->demo();
p->demo_2();
p->demo_3();
}
Листинг 24 Демонстрация вызова виртуальных функций
Результат ее компиляции в общем случае должен выглядеть так:
main proc near ; CODE XREF: start+AFp
push esi
push 4
call ??2@YAPAXI@Z ; operator new(uint)
; EAX c- указатель на выдел. блок памяти
; Выделяем четыре байта памяти для экземпляра нового объекта.
; Объект состоит из одного лишь указателя на VTBL.
add esp, 4
test eax, eax
jz short loc_0_401019 ; --> Ошибка выделения памяти
; проверка успешности выделения памяти
mov dword ptr [eax], offset BASE_VTBL
; Вот здесь в только что созданный экземпляр объекта копируется
; указатель на виртуальную таблицу класса BASE.
; То, что это именно виртуальная таблица класса BASE, можно узнать
; проанализировав элементы этой таблицы – они указывают на члены
; класса BASE, следовательно, сама таблица – виртуальная таблица
; класса BASE
mov esi, eax ; ESI = **BASE_VTBL
; заносим в ESI указатель на экземпляр объекта (указатель на указатель
; на BASE_VTBL
; Зачем? Дело в том, что на самом деле в ESI
заносится указатель на
; экземпляр объекта (см. "Идентификация объектов, структур и массивов),
; но нам на данном этапе все эти детали ни к чему, поэтому, мы просто
; говорим, что в ESI – указатель на указатель на виртуальную таблицу
; базового класса, не вникая для чего понадобился этот двойной указатель.
jmp short loc_0_40101B
loc_0_401019: ; CODE XREF: sub_0_401000+Dj
xor esi, esi
; принудительно обнуляем указатель на экземпляр объекта (эта ветка получает управление
; только в случае неудачного выделения памяти для объекта) нулевой указатель
; словит обработчик структурных исключений при первой же попытке обращения
loc_0_40101B: ; CODE XREF: sub_0_401000+17j
mov eax, [esi] ; EAX = *BASE_VTBL == *BASE_DEMO
; заносим в EAX указатель на виртуальную таблицу класса BASE,
; не забывая о том, что указатель на виртуальную таблицу одновременно
; является указателем и на первый элемент этой таблицы.
; А первый элемент виртуальной таблицы, содержащий указатель
; на первую (в порядке объявления) виртуальную функцию класса.
mov ecx, esi ; ECX = this
; заносим в ECX указатель на экземпляр объекта, передавая вызываемой функции
; неявный аргумент – указатель this
(см. "Идентификация аргументов функций")
call dword ptr [eax] ; CALL BASE_DEMO
; Вот он – вызов виртуальной функции! Чтобы понять – какая именно функция
; вызывается, мы должны знать значение регистра EAX. Прокручивая экран
; дизассемблера вверх, мы видим – EAX
указывает на BASE_VTBL, а первый
; член BASE_VTBL
(см. ниже) указывает на функцию BASE_DEMO. Следовательно:
; а) этот код вызывает именно функцию BASE_DEMO
; б) функция BASE_DEMO
– это виртуальная
функция
mov edx, [esi] ; EDX = *BASE_DEMO
; заносим в EDX указатель на первый элемент виртуальной таблицы класса BASE
mov ecx, esi ; ECX = this
; заносим в ECX указатель на экземпляр объекта
; Это неявный аргумент функции – указатель this
(см. "Идентификация this")
call dword ptr [edx+4] ; CALL [BASE_VTBL+4] (BASE_DEMO_2)
; Еще один вызов виртуальной функции! Чтобы понять – какая именно функция
; вызывается, мы должны знать содержимое регистра EDX. Прокручивая экран
; дизассемблера вверх, мы видим, что он указывает на BASE_VTBL, а EDX+4,
; стало быть, указывает на второй элемент виртуальной таблицы класса BASE.
; Он же, в свою очередь, указывает на функцию BASE_DEMO_2
push offset aNonVirtualBase ; "Non virtual BASE DEMO 3\n"
call printf
; а вот вызов не виртуальной функции. Обратите внимание – он происходит
; как и вызов обычной Си функции. (Обратите внимание, что эта функция -
; встроенная, т.к. объявленная непосредственно в самом классе и вместо ее
; вызова осуществляется подстановка кода)
push 4
call ??2@YAPAXI@Z ; operator new(uint)
; Далее идет вызов функций класса DERIVED. Не будем здесь подробно
; его комментировать – сделайте это самостоятельно. Вообще же, класс
; DERIVED
понадобился только для того, чтобы показать особенности компоновки
; виртуальных таблиц
add esp, 8 ; Очистка после printf
& new
test eax, eax
jz short loc_0_40104A ; Ошибка выделения памяти
mov dword ptr [eax], offset DERIVED_VTBL
mov esi, eax ; ESI == **DERIVED_VTBL
jmp short loc_0_40104C
loc_0_40104A: ; CODE XREF: sub_0_401000+3Ej
xor esi, esi
loc_0_40104C: ; CODE XREF: sub_0_401000+48j
mov eax, [esi] ; EAX = *DERIVED_VTBL
mov ecx, esi ; ECX = this
call dword ptr [eax] ; CALL [DERIVED_VTBL] (DERIVED_DEMO)
mov edx, [esi] ; EDX = *DERIVED_VTBL
mov ecx, esi ; ECX=this
call dword ptr [edx+4] ; CALL [DERIVED_VTBL+4] (DERIVED_DEMO_2)
push offset aNonVirtualBase ; "Non virtual BASE DEMO 3\n"
call printf
; Обратите внимание – вызывается функция BASE_DEMO базового,
; а не производного класса!!!
add esp, 4
pop esi
retn
main endp
BASE_DEMO proc near ; DATA XREF: .rdata:004050B0o
push offset aBase ; "BASE\n"
call printf
pop ecx
retn
BASE_DEMO endp
BASE_DEMO_2 proc near ; DATA XREF: .rdata:004050B4o
push offset aBaseDemo2 ; "BASE DEMO 2\n"
call printf
pop ecx
retn
BASE_DEMO_2 endp
DERIVED_DEMO proc near ; DATA XREF: .rdata:004050A8o
push offset aDerived ; "DERIVED\n"
call printf
pop ecx
retn
DERIVED_DEMO endp
DERIVED_DEMO_2 proc near ; DATA XREF: .rdata:004050ACo
push offset aDerivedDemo2 ; "DERIVED DEMO 2\n"
call printf
pop ecx
retn
DERIVED_DEMO_2 endp
DERIVED_VTBL dd offset DERIVED_DEMO ; DATA XREF: sub_0_401000+40o
dd offset DERIVED_DEMO_2
BASE_VTBL dd offset BASE_DEMO ; DATA XREF: sub_0_401000+Fo
dd offset BASE_DEMO_2
; Обратите внимание – виртуальные таблицы "растут" снизу вверх в порядке
; объявления классов в программе, а элементы виртуальных таблиц "растут"
; сверху вниз в порядке объявления виртуальных функций в классе.
; Конечно, так бывает не всегда (порядок размещения таблиц и их элементов
; нигде не декларирован и целиком лежит на "совести" компилятора, но на
; практике большинство из них ведут себя именно так) Сами же виртуальные
; функции располагаются вплотную друг к другу в порядке их объявления
Листинг 25
Рисунок 11 0x006 Художнику – добавить функции A, B и С Реализация вызова виртуальных функций
::идентификация чистой виртуальной функции. Если функция объявляется в базовом, а реализуется в производным классе – такая функция называется чистой виртуальной функцией, а класс, содержащий хотя бы одну такую функцию, называется абстрактным классом.
Язык Си++ запрещает создание экземпляров абстрактного класса, да и как они могут создаваться, если, по крайней мере, одна из функций класса неопределенна?
На первый взгляд – не определена, и ладно, – какая в этом беда? Ведь на анализ программы это не влияет. На самом деле это не так – чистая виртуальная функция в виртуальной таблице замещается указателем на библиотечную функцию __purecall. Зачем она нужна? Дело в том, что на стадии компиляции программы невозможно гарантированно "отловить" все попытки вызова чисто виртуальных функций, но если такой вызов и произойдет, управление получит заранее подставленная сюда __purecall, которая выведет на экран "ругательство" по поводу запрета на вызов чисто виртуальных функций и завершит работу приложения. Подробнее об этом можно прочитать в технической заметке MSNDN
Q120919, датированной 27 июня 1997 года.
Таким образом, встретив в виртуальной таблице указатель на __purecall, можно с уверенностью утверждать, что мы имеем дело с чисто виртуальной функцией. Рассмотрим следующий пример:
#include <stdio.h>
class Base{
public:
virtual void demo(void)=0;
};
class Derived:public Base {
public:
virtual void demo(void)
{
printf("DERIVED\n");
};
};
main()
{
Base *p = new Derived;
p->demo();
}
Листинг 26 Демонстрация вызова чистой виртуальной функции
Результат его компиляции в общем случае должен выглядеть так:
main proc near ; CODE XREF: start+AFp
push 4
call ??2@YAPAXI@Z
add esp, 4
; Выделение памяти для нового экземляра объекта
test eax, eax
; Проверка успешности выделения памяти
jz short loc_0_401017
mov ecx, eax
; ECX = this
call GetDERIVED_VTBL
; занесение в экземпляр объекта указателя на виртуальную таблицу класса
; DERIVED
jmp short loc_0_401019
loc_0_401017: ; CODE XREF: main+Cj
xor eax, eax
; EAX = NULL
loc_0_401019: ; CODE XREF: main+15j
mov edx, [eax]
; тут возникает исключение по обращению к нулевому указателю
mov ecx, eax
jmp dword ptr [edx]
main endp
GetDERIVED_VTBL proc near ; CODE XREF: main+10p
push esi
mov esi, ecx
; Через регистр ECX функции передается неявный аргумент – this
call SetPointToPure
; функция заносит в экземпляр объекта указатель на __purecall
; специальную функцию - заглушку на случай незапланированного вызова
; чисто виртуальной функции
mov dword ptr [esi], offset DERIVED_VTBL
; занесение в экземпляр объекта указателя на виртуальную таблицу производного
; класса, с затиранием предыдущего значения (указателя на __purecall)
mov eax, esi
pop esi
retn
GetDERIVED_VTBL endp
DERIVED_DEMO proc near ; DATA XREF: .rdata:004050A8o
push offset aDerived ; "DERIVED\n"
call printf
pop ecx
retn
DERIVED_DEMO endp
SetPointToPure proc near ; CODE XREF: GetDERIVED_VTBL+3p
mov eax, ecx
mov dword ptr [eax], offset PureFunc
; Заносим по [EAX] (в экземляр нового объекта) указатель на специальную
; функцию - __purecall, которая предназначена для отслеживания попыток
; вызова чисто виртуальной функции в ходе выполнения программы -
; если такая попытка произойдет, __purecall выведет на экран "матюгательство"
; дескать, вызывать чисто виртуальную функцию нельзя и завершит работу
retn
SetPointToPure endp
DERIVED_VTBL dd offset DERIVED_DEMO ; DATA XREF: GetDERIVED_VTBL+8o
PureFunc dd offset __purecall ; DATA XREF: SetPointToPure+2o
; указатель на функцию-заглушку __purecall. Следовательно, мы имеем дело
; с чисто виртуальной функцией
Листинг 27
::совместное использование виртуальной таблицы несколькими экземплярами объекта. Сколько бы экземпляров объекта ни существовало – все они пользуются одной и той же виртуальной таблицей.
Виртуальная таблица принадлежит самому объекту, но не экземпляру (экземплярам) этого объекта. Впрочем, из этого правила существуют и исключения (см. "Копии виртуальных таблиц").
Рисунок 12 0x007 все экземпляры объекта используют одну и ту же виртуальную таблицу
Для подтверждения сказанного рассмотрим следующий пример:
#include <stdio.h>
class Base{
public:
virtual demo ()
{
printf("Base\n");
}
};
class Derived:public Base{
public:
virtual demo()
{
printf("Derived\n");
}
};
main()
{
Base * obj1 = new Derived;
Base * obj2 = new Derived;
obj1->demo();
obj2->demo();
}
Листинг 28 Демонстрация совместного использование одной копии виртуальной таблицы несколькими экземплярами класса
Результат его компиляции в общем случае должен выглядеть так:
main proc near ; CODE XREF: start+AFp
push esi
push edi
push 4
call ??2@YAPAXI@Z ; operator new(uint)
add esp, 4
; выделяем память под первый экземпляр объекта
test eax, eax
jz short loc_0_40101B
mov ecx, eax ; EAX
– указывает на первый экземпляр объекта
call GetDERIVED_VTBL
; в EAX – указатель на виртуальную таблицу класса DERIVED
mov edi, eax ; EDI = *DERIVED_VTBL
jmp short loc_0_40101D
loc_0_40101B: ; CODE XREF: main+Ej
xor edi, edi
loc_0_40101D: ; CODE XREF: main+19j
push 4
call ??2@YAPAXI@Z ; operator new(uint)
add esp, 4
; выделяем память под второй экземпляр объекта
test eax, eax
jz short loc_0_401043
mov ecx, eax ; ECX – this
call GetDERIVED_VTBL
; обратите внимание – второй экземпляр использует ту же самую
; виртуальную
таблицу
DERIVED_VTBL dd offset DERIVED_DEMO ; DATA XREF: GetDERIVED_VTBL+8o
BASE_VTBL dd offset BASE_DEMO ; DATA XREF: GetBASE_VTBL+2o
; Обратите внимание – виртуальная таблица одна на все экземпляры класса
Листинг 29
::копии виртуальных таблиц. ОК, для успешной работы, - понятное дело, - вполне достаточно и одной виртуальной таблицы, однако, на практике приходится сталкиваться с тем, что исследуемый файл прямо-таки кишит копиями этих виртуальных таблиц. Что же это за напасть такая, откуда она берется и как с ней бороться?
Если программа состоит из нескольких файлов, компилируемых в самостоятельные obj-модули (а такой подход используется практически во всех мало-мальски серьезных проектах), компилятор, очевидно, должен поместить в каждый obj "свою" собственную виртуальную таблицу для каждого используемого модулем класса. В самом деле – откуда компилятору знать о существовании других obj и наличии в них виртуальных таблиц? Вот так и возникают никому не нужные дубли, отъедающие память и затрудняющие анализ. Правда, на этапе компоновки, линкер может обнаружить копии и удалить их, да и сами компиляторы используют различные эвристические приемы для повышения эффективности генерируемого кода. Наибольшую популярность завоевал следующий алгоритм: виртуальная таблица помещается в тот модуль, в котором содержится реализация первой невстроенной не виртуальной функции класса. Обычно каждый класс реализуется в одном модуле и в большинстве случаев такая эвристика срабатывает. Хуже если класс состоит из одних виртуальных или встраиваемых функций – в этом случае компилятор "ложится" и начинает запихивать виртуальные таблицы во все модули, где этот класс используется. Последняя надежда на удаление "мусорных" копий ложиться на линкер, но и линкер – не панацея. Собственно, эти проблемы должны больше заботить разработчиков программы (если их волнует количество занимаемой программой памятью), для анализа лишние копии – всего лишь досадна помеха, но отнюдь не непреодолимое препятствие!
::связанный список. В большинстве случаев виртуальная таблица представляет собой обыкновенный массив, но некоторые компиляторы представляют ее в виде связного списка, - каждый элемент виртуальной таблицы содержит указатель на следующий элемент, а сами элементы размещены не вплотную друг к другу, а рассеянны по всему исполняемому файлу.
На практике подобное, однако, встречается крайне редко, поэтому, не будем подробно на этом останавливаться, - достаточно лишь знать, что такое бывает, - если встретись со списками (впрочем, навряд ли вы с ними встретитесь) – разберетесь по обстоятельствам, благо это несложно.
::вызов через шлюз. Будьте так же готовы и к тому, чтобы встретить в виртуальной таблице указатель не на виртуальную функцию, а на код, который модифицирует этот указатель, занося в него смещение вызываемой функции. Этот прием был впервые предложен самим разработчиком языка – Бьерном Страуструпом, позаимствовавшим его из ранних реализаций Алгола-60. В Алголе код, корректирующий указатель вызываемой функции, называется шлюзом (thunk), а сам вызов – вызовом через шлюз. Вполне справедливо употреблять эту терминологии и по отношению к Си++.
Однако в настоящее время вызов через шлюз чрезвычайно мало распространен и не используется практически ни одним компилятором. Несмотря на то, что он обеспечивает более компактное хранение виртуальных таблиц, модификация указателя приводит к излишним накладным расходам на процессорах с конвейерной архитектурой, (а Pentium – наиболее распространенный процессор, - как раз и построен по такой архитектуре). Поэтому, использование шлюзовых вызовов оправдано лишь в программах, критических к размеру, но не к скорости.
Подробнее обо всем этом можно прочесть в руководстве по Алголу-60 (шутка), или у Бьерна Страуструпа в "Дизайне и эволюции языка С++".
::сложный пример или когда не виртуальные функции попадают в виртуальные таблицы. До сих пор мы рассматривали лишь простейшие примеры использования виртуальных функций. В жизни же порой встречается такое… Рассмотрим сложный случай наследования с конфликтом имен:
#include <stdio.h>
class A{
public:
virtual void f() { printf("A_F\n");};
};
class B{
public:
virtual void f() { printf("B_F\n");};
virtual void g() { printf("B_G\n");};
};
class C:public A, public B {
public:
void f(){ printf("C_F\n");}
}
main()
{
A *a = new A;
B *b = new B;
C *c = new C;
a->f();
b->f();
b->g();
c->f();
}
Листинг 30 Демонстрация помещения не виртуальных функций в виртуальные таблицы
Как будет выглядеть виртуальная таблица класса C? Так, давайте подумаем: раз класс C – производный от классов A и B, то он наследует функции обоих, но виртуальная функция f() класса B перекрывает одноименную виртуальную функцию класса A, поэтому, из класса А она не наследуется. Далее, поскольку не виртуальная функция f() присутствует и в производном классе С, она перекрывает виртуальную функцию производного класса (да, именно так, а вот не виртуальная не виртуальную функцию не перекрывает и она всегда вызывается из базового, а не производного класса). Таким образом, виртуальная таблица класса С должна содержать только один элемент – указатель на виртуальную функцию g(), унаследованную от B, а не виртуальная функция f() вызывается как обычная Си-функция. Правильно? Нет!
Это как раз тот случай, когда не виртуальная функция вызывается через указатель – как виртуальная функция. Более того, виртуальная таблица класса будет содержать не два, а три элемента! Третий элемент – это ссылка на виртуальную функцию f(), унаследованную от B, но тут же замещенная компилятором на "переходник" к C::f(). Уф… Как все непросто! Может, после изучения дизассемблерного листинга это станет понятнее?
main proc near ; CODE XREF: start+AFp
push ebx
push esi
push edi
push 4
call ??2@YAPAXI@Z ; operator new(uint)
add esp, 4
; выделяем память для экземпляра объекта A
test eax, eax
jz short loc_0_40101C
mov ecx, eax ; ECX = this
call Get_A_VTBL ; a[0]=*A_VTBL
; помещаем в экземпляр объекта указатель на его виртуальную таблицу
mov ebx, eax ; EBX = *a
jmp short loc_0_40101E
loc_0_40101C: ; CODE XREF: main+Fj
xor ebx, ebx
loc_0_40101E: ; CODE XREF: main+1Aj
push 4
call ??2@YAPAXI@Z ; operator new(uint)
add esp, 4
; выделяем память для экземпляра объекта B
test eax, eax
jz short loc_0_401037
mov ecx, eax ; ECX = this
call Get_B_VTBL ; b[0] = *B_VTBL
; помещаем в экземпляр объекта указатель на его виртуальную таблицу
mov esi, eax ; ESI = *b
jmp short loc_0_401039
loc_0_401037: ; CODE XREF: main+2Aj
xor esi, esi
loc_0_401039: ; CODE XREF: main+35j
push 8
call ??2@YAPAXI@Z ; operator new(uint)
add esp, 4
; выделяем память для экземпляра объекта B
test eax, eax
jz short loc_0_401052
mov ecx, eax ; ECX = this
call GET_C_VTBLs ; ret: EAX=*c
; помещаем в экземпляр объекта указатель на его виртуальную таблицу
; (внимание: загляните в функцию GET_C_VTBLs)
mov edi, eax ; EDI = *c
jmp short loc_0_401054
loc_0_401052: ; CODE XREF: main+45j
xor edi, edi
loc_0_401054: ; CODE XREF: main+50j
mov eax, [ebx] ; EAX = a[0] = *A_VTBL
mov ecx, ebx ; ECX = *a
call dword ptr [eax] ; CALL [A_VTBL] (A_F)
mov edx, [esi] ; EDX = b[0]
mov ecx, esi ; ECX = *b
call dword ptr [edx] ; CALL [B_VTBL] (B_F)
mov eax, [esi] ; EAX = b[0] = B_VTBL
mov ecx, esi ; ECX = *b
call dword ptr [eax+4] ; CALL [B_VTBL+4] (B_G)
mov edx, [edi] ; EDX = c[0] = C_VTBL
mov ecx, edi ; ECX = *c
call dword ptr [edx] ; CALL [C_VTBL] (C_F)
; Внимание! Вызов не виртуальной функции происходит как виртуальной!
pop edi
pop esi
pop ebx
retn
main endp
GET_C_VTBLs proc near ; CODE XREF: main+49p
push esi ; ESI = *b
push edi ; ECX = *c
mov esi, ecx ; ESI = *c
call Get_A_VTBL ; c[0]=*A_VTBL
; помещаем в экземпляр объекта C указатель на виртуальную таблицу класса A
lea edi, [esi+4] ; EDI = *c[4]
mov ecx, edi ; ECX = **_C_F
call Get_B_VTBL ; c[4]=*B_VTBL
; добавляем в экземпляр объекта C
указатель на виртуальную таблицу класса B
; т.е. теперь объект C содержит два указателя на две виртуальные таблицы
; базовых классов. Посмотрим далее, как компилятор справится с конфликтом
; имен…
mov dword ptr [edi], offset C_VTBL_FORM_B ; c[4]=*_C_VTBL
; Ага! указатель на виртуальную таблицу класса B
замещается указателем
; на виртуальную таблицу класса C
(смотри комментарии в самой таблице)
mov dword ptr [esi], offset C_VTBL ; c[0]=C_VTBL
; Ага, еще раз – теперь указатель на виртуальную таблицу класса A замещается
; указателем на виртуальную таблицу класса C. Какой неоптимальный код, ведь это
; было можно сократить еще на стадии компиляции!
mov eax, esi ; EAX = *c
pop edi
pop esi
retn
GET_C_VTBLs endp
Get_A_VTBL proc near ; CODE XREF: main+13p GET_C_VTBLs+4p
mov eax, ecx
mov dword ptr [eax], offset A_VTBL
; помещаем в экземпляр объекта указатель на виртуальную таблицу класса B
retn
Get_A_VTBL endp
A_F proc near ; DATA XREF: .rdata:004050A8o
; виртуальная функиця f() класса A
push offset aA_f ; "A_F\n"
call printf
pop ecx
retn
A_F endp
Get_B_VTBL proc near ; CODE XREF: main+2Ep GET_C_VTBLs+Ep
mov eax, ecx
mov dword ptr [eax], offset B_VTBL
; помещаем в экземпляр объекта указатель на виртуальную таблицу класса B
retn
Get_B_VTBL endp
B_F proc near ; DATA XREF: .rdata:004050ACo
; виртуальная функция f() класса B
push offset aB_f ; "B_F\n"
call printf
pop ecx
retn
B_F endp
B_G proc near ; DATA XREF: .rdata:004050B0o
; виртуальная функция g() класса B
push offset aB_g ; "B_G\n"
call printf
pop ecx
retn
B_G endp
C_F proc near ; CODE XREF: _C_F+3j
; Не виртуальная функция f() класса C
выглядит и вызывается как виртуальная!
push offset aC_f ; "C_F\n"
call printf
pop ecx
retn
C_F endp
_C_F proc near ; DATA XREF: .rdata:004050B8o
sub ecx, 4
jmp C_F
; смотрите, какая странная функция! Во-первых, она никогда не вызывается, а
; во-вторых, это переходник к функции C_F.
; зачем уменьшается ECX? В ECX компилятор поместил указатель this, который
; до уменьшения пытался указывать на виртуальную функцию f(), унаследованную
; от класса B. Но на самом же деле this указывал на этот переходник.
; А после уменьшения он стал указывать на предыдущий элемент виртуальной
; таблицы – т.е. функцию f() класса C, вызов которой и осуществляет JMP
_C_F endp
A_VTBL dd offset A_F ; DATA XREF: Get_A_VTBL+2o
; виртуальная таблица класса A
B_VTBL dd offset B_F ; DATA XREF: Get_B_VTBL+2o
dd offset B_G
; виртуальная таблица класса B – содержит указатели на две виртуальные функции
C_VTBL dd offset C_F ; DATA XREF: GET_C_VTBLs+19o
; виртуальная таблица класса C. Содержит указатель на не виртуальную функцию f()
C_VTBL_FORM_B dd offset _C_F ; DATA XREF: GET_C_VTBLs+13o
dd offset B_G
; виртуальная таблица класса C скопированная компилятором из класса B. Первоначально
; состояла из двух указателей на функции f() и g(), но еще на стадии
; компиляции компилятор разобрался в конфликте имен и заменил указатель на B::f()
; указателем на переходник к C::f()
Листинг 31
Таким образом, на самом деле виртуальная таблица производного класса включает в себя виртуальные таблицы всех базовых классов (во всяком случае, всех, откуда она наследует виртуальные функции).
В данном случае виртуальная таблица класса С содержит указатель на не виртуальную функцию С и виртуальную таблицу класса B. Задача – как определить, что функция C::f() не виртуальная? И как найти все базовые классы класса C?
Начнем с последнего – да, виртуальная таблица класса С не содержит никакого намека на его родственные отношения с классом A, но взгляните на содержимое функции GET_C_VTBLs, - видите: предпринимается попытка внедрить в C указатель на виртуальную таблицу А, следовательно, класс C – производный от A. Мне могут возразить, дескать, это не слишком надежный путь, компилятор мог бы оптимизировать код, выкинув обращение к виртуальной таблице класса А, которое все равно не нужно. Это верно, - мог бы, но на практике большинство компиляторов так не делают, а если и делают, все равно оставляют достаточно избыточной информации, позволяющей установить базовые классы. Другой вопрос – так ли необходимо устанавливать "родителей", от которых не наследуется ни одной функции? (Если хоть одна функция наследуется, никаких сложностей в поиске не возникает). В общем-то, для анализа это действительно некритично, но, чем точнее будет восстановлен исходный код программы, – тем нагляднее он будет и тем легче в нем разобраться.
Теперь перейдем к не виртуальной функции f(). Подумаем, что было бы – будь она на самом деле виртуальной? Тогда – она бы перекрыла одноименную функцию базовых классов и никакой "дикости" наподобие "переходников" в откомпилированной программе и не встретилось бы. А так – они говорят, что тут не все гладко и функция не виртуальная, хоть и стремится казаться такой. Опять-таки, умный компилятор теоретически может выкинуть переходник и дублирующийся элемент виртуальной таблицы класса С, но на практике этой интеллектуальности не наблюдается…
::статическое связывание. Есть ли разница как создавать экземпляр объекта – MyClass zzz;
или MyClass *zzz=new MyClass? Разумеется: в первом случае компилятор может определить адреса виртуальных функций еще на стадии компиляции, тогда как во втором – это приходится вычислять в ходе выполнения программы.
Другое различие: статические объекты размешаются в стеке (сегменте данных), а динамические – в куче. Таблица виртуальных функций упорно создается компиляторами в обоих случаях, а при вызове каждый функции (включая не виртуальные) подготавливается указатель this (как правило, помещаемый в один из регистров общего назначения – подробнее см. "Идентификация аргументов функций"), содержащий адрес экземпляра объекта.
Таким образом, если мы встречаем функцию, вызываемую непосредственно по ее смещению, но в то же время присутствующую в виртуальной таблице класса – можно с уверенностью утверждать, что это – виртуальная функция статичного экземпляра объекта.
Рассмотрим следующий пример:
#include <stdio.h>
class Base{
public:
virtual void demo(void)
{
printf("BASE DEMO\n");
};
virtual void demo_2(void)
{
printf("BASE DEMO 2\n");
};
void demo_3(void)
{
printf("Non virtual BASE DEMO 3\n");
};
};
class Derived: public Base{
public:
virtual void demo(void)
{
printf("DERIVED DEMO\n");
};
virtual void demo_2(void)
{
printf("DERIVED DEMO 2\n");
};
void demo_3(void)
{
printf("Non virtual DERIVED DEMO 3\n");
};
};
main()
{
Base p;
p.demo();
p.demo_2();
p.demo_3();
Derived d;
d.demo();
d.demo_2();
d.demo_3();
}
Листинг 32 Демонстрация вызова статической виртуальной функции
Результат ее компиляции в общем случае должен выглядеть так:
main proc near ; CODE XREF: start+AFp
var_8 = byte ptr -8 ; derived
var_4 = byte ptr -4 ; base
; часто, (но не всегда!) экземпляры объектов в стеке расположены снизу вверх,
; т.е. в обратном порядке их объявления в программе
push ebp
mov ebp, esp
sub esp, 8
lea ecx, [ebp+var_4] ; base
call GetBASE_VTBL ; p[0]=*BASE_VTBL
; обратите внимание – экземпляр объекта размещается в стеке,
; а не в куче! Это, конечно, не еще не свидетельствует о статичной
; природе экземпляра объекта (динамичные объекты тоже могут размещаться в стеке)
; но намеком на "статику" все же служит
lea ecx, [ebp+var_4] ; base
; подготавливаем указатель this (на тот случай если он понадобится функции)
call BASE_DEMO
; непосредственный вызов функции! Вот, вкупе с ее наличием в виртуальной таблице
; свидетельство статичности объявления экземпляра объекта!
lea ecx, [ebp+var_4] ; base
; вновь подготавливаем указатель this
на экземляр base
call BASE_DEMO_2
; непосредственный вызов функции. Она есть в виртуальной таблице? Есть!
; значит, это виртуальная функция, а экземпляр объекта объявлен статичным
lea ecx, [ebp+var_4] ; base
; готовим указатель this для не виртуальной
функции demo_3
call BASE_DEMO_3
; этой функции нет в виртуальной таблице (см. виртуальную таблицу)
; значит, она не виртуальная
lea ecx, [ebp+var_8] ; derived
call GetDERIVED_VTBL ; d[0]=*DERIVED_VTBL
lea ecx, [ebp+var_8] ; derived
call DERIVED_DEMO
; аналогично предыдущему...
lea ecx, [ebp+var_8] ; derived
call DERIVED_DEMO_2
; аналогично
предыдущему...
lea ecx, [ebp+var_8] ; derived
call BASE_DEMO_3_
; внимание! Указатель this указывает на объект DERIVED, в то время как
; вызывается функция объекта BASE!!! Значит, функция BASE – производная
mov esp, ebp
pop ebp
retn
main endp
BASE_DEMO proc near ; CODE XREF: main+11p
; функция demo класса BASE
push offset aBase ; "BASE\n"
call printf
pop ecx
retn
BASE_DEMO endp
BASE_DEMO_2 proc near ; CODE XREF: main+19p
; функция demo_2 класса BASE
push offset aBaseDemo2 ; "BASE DEMO 2\n"
call printf
pop ecx
retn
BASE_DEMO_2 endp
BASE_DEMO_3 proc near ; CODE XREF: main+21p
; функция demo_3 класса BASE
push offset aNonVirtualBase ; "Non virtual BASE DEMO 3\n"
call printf
pop ecx
retn
BASE_DEMO_3 endp
DERIVED_DEMO proc near ; CODE XREF: main+31p
; функция demo класса DERIVED
push offset aDerived ; "DERIVED\n"
call printf
pop ecx
retn
DERIVED_DEMO endp
DERIVED_DEMO_2 proc near ; CODE XREF: main+39p
; функция demo класса DERIVED
push offset aDerivedDemo2 ; "DERIVED DEMO 2\n"
call printf
pop ecx
retn
DERIVED_DEMO_2 endp
BASE_DEMO_3_ proc near ; CODE XREF: main+41p
; функция demo_3 класса BASE
; Внимание! Смотрите – функция demo_3 дважды присутствует в программе!
; первый раз она входила в объект класса BASE, а второй – в объект класса
; DERIVED, который унаследовал ее от базового класса и сделал копию
; глупо, да? ведь лучше бы он обратился к оригиналу... Зато это упрощает
; анализ программы...
push offset aNonVirtualDeri ; "Non virtual DERIVED DEMO 3\n"
call printf
pop ecx
retn
BASE_DEMO_3_ endp
GetBASE_VTBL proc near ; CODE XREF: main+9p
; занесение в экземпляр объекта BASE
смещения его виртуальной таблицы
mov eax, ecx
mov dword ptr [eax], offset BASE_VTBL
retn
GetBASE_VTBL endp
GetDERIVED_VTBL proc near ; CODE XREF: main+29p
; занесение в экземпляр объекта DERIVED
смещения его виртуальной таблицы
push esi
mov esi, ecx
call GetBASE_VTBL
; ага! Значит, наш объект – производный от BASE!
mov dword ptr [esi], offset DERIVED_VTBL
; занесение указателя на виртуальную таблицу DERIVED
mov eax, esi
pop esi
retn
GetDERIVED_VTBL endp
BASE_VTBL dd offset BASE_DEMO ; DATA XREF: GetBASE_VTBL+2o
dd offset BASE_DEMO_2
DERIVED_VTBL dd offset DERIVED_DEMO ; DATA XREF: GetDERIVED_VTBL+8o
dd offset DERIVED_DEMO_2
; обратите внимание на наличие виртуальной таблицы даже там, где она не нужна!
Листинг 33
::идентификация производных функций. Идентификация производных не виртуальных функций – весьма тонкий момент. На первый взгляд, коль они вызываются как и обычные Си-функции, распознать: в каком классе была объявлена функция невозможно – компилятор уничтожает эту информацию еще на стадии компиляции. Уничтожает, да не всю! Перед каждым вызовом функции (не важно производной или нет) в обязательном порядке формируется указатель this – на тот случай если он понадобится функции, указывающей на объект из которого вызывается эта функция. Для производных функций указатель this хранит смещение производного, а не базового объекта. Вот оно! Если функция вызывается с различными указателями this – это производная функция.
Сложнее выяснить – от какого объекта она происходит. Универсальных решений нет, но если выделить объект A с функциями f1(), f2()… И объект B с функциями f1(), f3(),f4()… то можно смело утверждать, что f1() – функция, производная от класса А. Правда, если из экземпляра класса функция f1() не вызывалась ни разу – определить производная она или нет – не удастся.
Рассмотрим все это на следующем примере:
#include <stdio.h>
class Base{
public:
void base_demo(void)
{
printf("BASE DEMO\n");
};
void base_demo_2(void)
{
printf("BASE DEMO 2\n");
};
};
class Derived: public Base{
public:
void derived_demo(void)
{
printf("DERIVED DEMO\n");
};
void derived_demo_2(void)
{
printf("DERIVED DEMO 2\n");
};
};
Листинг 34 Демонстрация идентификации производных функций
Результат компиляции в общем случае должен выглядеть так:
main proc near ; CODE XREF: start+AFp
push esi
push 1
call ??2@YAPAXI@Z ; operator new(uint)
; создаем новый экземпляр некоторого объекта. Пока мы еще не знаем какого
; пусть это будет объект A
mov esi, eax ; ESI = *a
add esp, 4
mov ecx, esi ; ECX = *a (this)
call BASE_DEMO
; вызываем BASE_DEMO, обращая внимание на то, что this
указывает на 'a'
mov ecx, esi ; ECX = *a (this)
call BASE_DEMO_2
; вызываем BASE_DEMO_2, обращая внимание на то, что this
указывает на 'a'
push 1
call ??2@YAPAXI@Z ; operator new(uint)
; создаем еще один экземпляр некоторого объекта, назовем его b
mov esi, eax ; ESI = *b
add esp, 4
mov ecx, esi ; ECX = *b (this)
call BASE_DEMO
; Ага! Вызываем BASE_DEMO, но на этот раз this
указывает на b
; значит, BASE_DEMO
связана родственными отношениями и с 'a' и с 'b'
mov ecx, esi
call BASE_DEMO_2
; Ага! Вызываем BASE_DEMO_2, но на этот раз this
указывает на b
; значит, BASE_DEMO_2 связана родственными отношениями и с 'a' и с 'b'
mov ecx, esi
call DERIVED_DEMO
; вызываем DERIVED_DEMO. Указатель this указывает на b, и никаких родственных
; связей DERIVED_DEMO
с 'a' не замечено. this
никогда не указывал на 'a'
; при ее вызове
mov ecx, esi
call DERIVED_DEMO_2
; аналогично...
pop esi
retn
main endp
Листинг 35
Ок, идентификация не виртуальных производных функций – вполне реальное дело. Единственная сложность – отличить экземпляры двух различных объектов от экземпляров одного и того же объекта.
Что же касается идентификации производных виртуальных функций – об этом уже рассказывалось выше. Производные виртуальные функции вызываются в два этапа – на первом в экземпляр объекта заносится смещение виртуальной таблицы базового класса, а затем оно замещается смещением виртуальной таблицы производного класса. Даже если компилятор оптимизирует код, оставшейся избыточности все равно с лихвой хватит для отличия производных функций от остальных.
::идентификация виртуальных таблиц. Теперь, основательно освоившись с виртуальными таблицами и функциями, рассмотрим очень коварный вопрос – всякий ли массив указателей на функции есть виртуальная таблица? Разумеется, нет! Ведь косвенный вызов функции через указатель – частое дело в практике программиста.
Массив указателей на функции… хм, конечно типичным его не назовешь, но и такое в жизни встречается!
Рассмотрим следующий пример – кривой и наигранный конечно, но чтобы продемонстрировать ситуацию, где массив указателей жизненно необходим, пришлось бы написать не одну сотню строк кода:
#include <stdio.h>
void demo_1(void)
{
printf("Demo 1\n");
}
void demo_2(void)
{
printf("Demo 2\n");
}
void call_demo(void **x)
{
((void (*)(void)) x[0])();
((void (*)(void)) x[1])();
}
main()
{
static void* x[2] =
{ (void*) demo_1,(void*) demo_2};
// Внимание: если инициализировать массив не при его объявлении
// а по ходу программы, т.е. x[0]=(void *) demo_1,...
// то компилятор сгенерирует адекватный код, заносящий
// смещения функций в ходе выполнения программы, что будет
// совсем не похоже на виртуальную таблицу!
// Напротив, инициализация при объявлении помещает уже
// готовые указатели в сегмент данных, смахивая на настоящую
// виртуальную таблицу (и экономя такты процессора к тому же)
call_demo(&x[0]);
}
Листинг 36 Демонстрация имитации виртуальных таблиц
А теперь посмотрим – сможем ли мы отличить "рукотворную" таблицу указателей от настоящей:
main proc near ; CODE XREF: start+AFp
push offset Like_VTBL
call demo_call
; ага, функции передается указатель на нечто очень похожее на виртуальную
; таблицу. Но мы-то, уже умудренные опытом, с легкостью раскалываем эту
; грубую подделку. Во-первых, указатели на VTBL
так просто не передаются,
; (там не такой тривиальный код), во-вторых они передаются не через стек,
; а через регистр. В-третьих, указатель на виртуальную таблицу ни одним
; существующим компилятором не используется непосредственно, а помещается
; в объект. Тут же нет ни объекта, ни указателя this
– в четвертых.
; словом, это не виртуальная таблица, хотя на беглый, нетренированный
; взгляд очень на нее похожа...
pop ecx
retn
main endp
demo_call proc near ; CODE XREF: sub_0_401030+5p
arg_0 = dword ptr 8
; вот-с! указатель – аргумент, а к виртуальным таблицам идет обращение
; через регистр...
push ebp
mov ebp, esp
push esi
mov esi, [ebp+arg_0]
call dword ptr [esi]
; происходит двухуровневый вызов функции – по указателю на массив
; указателей на функцию, что характерно для вызова виртуальных функций
; но, опять-таки слишком тривиальный код, - вызов виртуальных функций
; сопряжен с большой избыточностью, а во-вторых опять нет указателя this
call dword ptr [esi+4]
; аналогично – слишком просто для вызова виртуальной функции
pop esi
pop ebp
retn
demo_call endp
Like_VTBL dd offset demo_1 ; DATA XREF:main
dd offset demo_2
; массив указателей внешне похож на виртуальную таблицу, но
; расположен "не там" где обычно располагаются виртуальные таблицы
Листинг 37
Обобщая выводы, разбросанные по комментариям, повторим основные признаки "подделки" еще раз:
- слишком тривиальный код, - минимум используемых регистров и никакой избыточности, обращение к виртуальным таблицам происходит куда витиеватее;
- указатель на виртуальную функцию заносится в экземпляр объекта, и передается он не через стек, а через регистр (точнее – см. "Идентификация this");
- отсутствует указатель this, всегда подготавливаемый перед вызовом виртуальной функции;
- виртуальные функции и статические переменные располагаются в различных местах сегмента данных – поэтому сразу можно отличить одни от других.
А можно ли так организовать вызов функции по ссылке, чтобы компиляция программы давала код идентичный вызову виртуальной функции? Как сказать… Теоретически да, но практически – едва ли такое удастся осуществить (а уж непреднамеренно – тем более). Код вызова виртуальных функций в связи с большой избыточностью очень специфичен и легко различим "на глаз".Легко сымитировать общую технику работы с виртуальными таблицами, но без ассемблерных вставок невозможно воспроизвести ее в точности.
::заключение.
Вообще же, как мы видим, работа с виртуальными функциями сопряжена с огромной избыточностью и "тормозами", а их анализ связан с большими трудозатратами – приходится постоянно держать в голове множество указателей и помнить какой из них на что указывает. Но, как бы там ни было, никаких принципиально-неразрешимых преград перед исследователем не стоит.
Идентификация значения, возвращаемого функцией
…каждый язык - это своя философия, свой взгляд на деятельность программиста, отражение определенной технологии программирования.
Кауфман
Традиционно под "значением, возвращаемым функцией" понимается значение, возращенное оператором return, однако, это лишь надводная часть айсберга, не раскрывающая всей картины взаимодействия функций друг с другом. В качестве наглядной демонстрации рассмотрим довольно типичный пример, кстати, позаимствованный из реального кода программы:
int xdiv(int a, int b, int *c=0)
{
if (!b) return –1;
if (c) c[0]=a % b;
return a / b;
}
Листинг 88 Демонстрация возвращения значения в аргументе, переданном по ссылке
Функция xdiv возвращает результат целочисленного деления аргумента a
на аргумент b, но помимо этого записывает в переменную c, переданную по ссылке, остаток. Так сколько же значений вернула функция? И чем возращение результата по ссылке хуже или "незаконнее" классического return?
Популярные издания склонны упрощать проблему идентификации значения, возращенного функций, рассматривая один лишь частный случай с оператором return. В частности, так поступает Мэтт Питтерек в своей книге "Секреты системного программирования в Windows 95", все же остальные способы остаются "за кадром". Мы же рассмотрим следующие механизмы:
-- возврат значения оператором return (через регистры или стек сопроцессора);
-- возврат значений через аргументы, переданные по ссылке;
-- возврат значений через динамическую память (кучу);
-- возврат значений через глобальные переменные;
– возврат значений через флаги процессора.
Вообще-то, к этому списку не помешало бы добавить возврат значений через дисковые и проецируемые в память файлы, но это выходит за рамки обсуждаемой темы (хотя, рассматривая функцию как "черный ящик" с входом и выходом, нельзя не признать, что вывод функцией результатов своей работы в файл, – фактически есть возвращаемое ею значение).
::возврат значения оператором return. По общепринятому соглашению значение, возвращаемое оператором return, помещается в регистр EAX (в AX у 16-разрядных компиляторов), а если его оказывается недостаточно, старшие 32 бита операнда помещаются в EDX (в 16-разрядном режиме старшее слово помещается в DX).
Вещественные типы в большинстве случаев возвращаются через стек сопроцессора, реже – через регистры EDX:EAX (DX:AX в 16-разрядном режиме).
А как возвращаются типы, занимающие более 8 байт? Скажем, некая функция возвращает структуру, состоящую из сотен байт или объект не меньшего размера. Ни то, ни другое в регистры не запихнешь, даже стека сопроцессора не хватит!
|
тип |
способ возврата |
||
|
однобайтовый |
AL |
AX |
|
|
двухбайтовый |
AX |
||
|
четырехбайтовый |
DX:AX |
||
|
real |
DX:BX:AX |
||
|
float |
DX:AX |
стек сопроцессора |
|
|
double |
стек сопроцессора |
||
|
near pointer |
AX |
||
|
far pointer |
DX:AX |
||
|
свыше четырех байт |
через неявный аргумент по ссылке |
||
|
тип |
способ возврата |
|||
|
однобайтовый |
AL |
AX |
EAX |
|
|
двухбайтовый |
AX |
EAX |
||
|
четырехбайтовый |
EAX |
|||
|
восьми байтовый |
EDX:EAX |
|||
|
float |
стек сопроцессора |
EAX |
||
|
double |
стек сопроцессора |
EDX:EAX |
||
|
near pointer |
EAX |
|||
|
свыше восьми байт |
через неявный аргумент по ссылке |
|||
Оказывается, если возвращаемое значение не может быть втиснуто в регистры, компилятор скрыто от программиста передает функции неявный аргумент – ссылку на локальную переменную, в которую и записывается возвращенный результат. Таким образом, функции struct mystuct MyFunc(int a, int b) и void MyFunc(struct mystryct *my, int a, int b) компилируются в идентичный
(или близкий к тому) код и "вытянуть" из машинного кода подлинный прототип невозможно!
Единственную зацепку дает компилятор Microsoft Visual C++, возвращающий в этом случае указатель на возвращаемую переменную, т.е. восстановленный прототип выглядит приблизительно так: struct mystruct* MyFunc(struct mystruct* my, int a, int b). Согласитесь, несколько странно, чтобы программист в здравом уме да при живой теще, возвращал указатель на аргумент, который своими руками только что и передал функции? Компилятор же Borland C++ в данной ситуации возвращает тип void, стирая различие между аргументом, возвращаемым по значению и аргументом, возвращаемым по ссылке. Впрочем, невозможность восстановления подлинного прототипа не должна огорчать. Скорее наоборот! "Истинный прототип" утверждает, что результат работы функции возвращается по значению, а в действительности он возвращается по ссылке! Так ради чего тогда называть кошку мышкой?
Пару слов об определении типа возвращаемого значения. Если функция при выходе явно присваивает регистру EAX или EDX некоторое значение (AX и DX в 16-разрядном режиме), то его тип можно начерно определить по таблицам 11 и 12. Если же оставляет эти регистры неопределенными – то, скорее всего, возвращается тип void, т.е. ничто. Уточнить информацию помогает анализ вызывающей функции, а точнее то, как она обращается с регистрами EAX [EDX] (AX [DX] в 16-разрядном режиме). Например, для типов char характерно либо обращение к младшей половинке регистра EAX (AX) – регистру AL, либо обнуление старших байт операцией логического AND. Логично предположить: если вызывающая функция не использует значения, отставленного вызываемой функцией в регистрах EAX [EDX], – ее тип void. Но это предположение неверно. Частенько программисты игнорируют возвращаемое значение, вводя тем самым исследователей в заблуждение.
Рассмотрим следующий пример, демонстрирующий механизм возвращения основных типов значений:
#include <stdio.h>
#include <malloc.h>
char char_func(char a, char b)
{
return a+b;
}
int int_func(int a, int b)
{
return a+b;
}
__int64 int64_func(__int64 a, __int64 b)
{
return a+b;
}
int* near_func(int* a, int* b)
{
int *c;
c=(int *)malloc(sizeof(int));
c[0]=a[0]+b[0];
return c;
}
main()
{
int a;
int b;
a=0x666;
b=0x777;
printf("%x\n",
char_func(0x1,0x2)+
int_func(0x3,0x4)+
int64_func(0x5,0x6)+
near_func(&a,&b)[0]);
}
Листинг 89 Пример, демонстрирующий механизм возвращения основных типов значений
Результат его компиляции Microsoft Visual C++ 6.0 с настойками по умолчанию будет выглядеть так:
char_func proc near ; CODE XREF: main+1Ap
arg_0 = byte ptr 8
arg_4 = byte ptr 0Ch
push ebp
mov ebp, esp
; Открываем кадр стека
movsx eax, [ebp+arg_0]
; Загружаем в EAX arg_0 тип signed char, попутно расширяя его до int
movsx ecx, [ebp+arg_4]
; Загружаем в EAX arg_0 тип signed char, попутно расширяя его до int
add eax, ecx
; Складываем arg_0 и arg_4 расширенные до int, сохраняя их в регистре EAX -
; это есть значение, возвращаемое функцией.
; К сожалению, достоверно определить его тип невозможно. Он с равным успехом
; может представлять собой и int и char, причем, int даже более вероятен,
; т.к. сумма двух char по соображениям безопасности должна помещаться в int,
; иначе возможно переполнение.
pop ebp
retn
char_func endp
int_func proc near ; CODE XREF: main+29p
arg_0 = dword ptr 8
arg_4 = dword ptr 0Ch
push ebp
mov ebp, esp
; Открываем кадр стека
mov eax, [ebp+arg_0]
; Загружаем в EAX значение аргумента arg_0 типа int
add eax, [ebp+arg_4]
; Складываем arg_0 с arg_4 и оставляем результат в регистре EAX.
; Это и есть значение, возвращаемое функцией, вероятнее всего, типа int.
pop ebp
retn
int_func endp
int64_func proc near ; CODE XREF: main+40p
arg_0 = dword ptr 8
arg_4 = dword ptr 0Ch
arg_8 = dword ptr 10h
arg_C = dword ptr 14h
push ebp
mov ebp, esp
; открываем кадр стека
mov eax, [ebp+arg_0]
; Загружаем в EAX значение аргумента arg_0
add eax, [ebp+arg_8]
; Складываем arg_0 с arg_8
mov edx, [ebp+arg_4]
; Загружаем в EDX значение аргумента arg_4
adc edx, [ebp+arg_C]
; Складываем arg_4 и arg_C
с учетом флага переноса, оставшегося от сложения
; arg_0 с arg_8.
; Выходит, arg_0 и arg_4, как и arg_8 и arg_C
это – половинки двух
; аргументов типа __int64, складываемые друг с другом.
; Стало быть, результат вычислений возвращается в регистрах EDX:EAX
pop ebp
retn
int64_func endp
near_func proc near ; CODE XREF: main+54p
var_4 = dword ptr -4
arg_0 = dword ptr 8
arg_4 = dword ptr 0Ch
push ebp
mov ebp, esp
; Отрываем кадр стека
push ecx
; Сохраняем ECX
push 4 ; size_t
call _malloc
add esp, 4
; Выделяем 4 байта из кучи
mov [ebp+var_4], eax
; Заносим указатель на выделенную память в переменную var_4
mov eax, [ebp+arg_0]
; Загружаем в EAX значение аргумента arg_0
mov ecx, [eax]
; Загружаем в ECX значение ячейки памяти типа int на которую указывает EAX.
; Таким образом, тип аргумента arg_0 – int
*
mov edx, [ebp+arg_4]
; Загружаем в EDX значение аргумента arg_4
add ecx, [edx]
; Складываем с *arg_0 значение ячейки памяти типа int
на которое указывает EDX
; Следовательно, тип аргумента arg_4 – int
*
mov eax, [ebp+var_4]
; Загружаем в EAX указатель на выделенный из кучи блок памяти
mov [eax], ecx
; Копируем в кучу значение суммы *arg_0 и *arg_4
mov eax, [ebp+var_4]
; Загружаем в EAX указатель на выделенный из кучи блок памяти
; Это и будет значением, возвращаемым функцией, т.е.
ее прототип выглядел так:
; int* MyFunc(int *a, int *b);
mov esp, ebp
pop ebp
retn
near_func endp
main proc near ; CODE XREF: start+AFp
var_8 = dword ptr -8
var_4 = dword ptr -4
push ebp
mov ebp, esp
; Открываем кадр стека
sub esp, 8
; Резервируем место для локальных переменных
push esi
push edi
; Сохраняем регистры в стеке
mov [ebp+var_4], 666h
; Заносим в локальную переменную var_4 типа int
значение 0x666
mov [ebp+var_8], 777h
; Заносим в локальную переменную var_8 типа int
значение 0x777
push 2
push 1
call char_func
add esp, 8
; Вызываем
функцию char_func(1,2). Как мы помним, у нас были сомнения в типе
; возвращаемого ею значения – либо int, либо char.
movsx esi, al
; Расширяем возращенное функцией значение до signed int, следовательно, она
; возвратила signed char
push 4
push 3
call int_func
add esp, 8
; Вызываем функцию int_func(3,4), возвращающую значение типа int
add eax, esi
; Прибавляем к значению, возвращенному функцией, содержимое ESI
cdq
; Преобразуем двойное слово, содержащееся в регистре EAX
в четверное,
; помещаемое в регистр EDX:EAX
mov esi, eax
mov edi, edx
; Копируем расширенное четверное слово в регистры EDI:ESI
push 0
push 6
push 0
push 5
call int64_func
add esp, 10h
; Вызываем функцию int64_func(5,6), возвращающую тип __int64
; Теперь становится понятно, чем вызвано расширение предыдущего результата
add esi, eax
adc edi, edx
; К четверному слову, содержащемуся в регистрах EDI:ESI добавляем результат
; возращенный функцией int64_func
lea eax, [ebp+var_8]
; Загружаем в EAX указатель на переменную var_8
push eax
; Передаем функции near_func
указатель на var_8 как аргумент
lea ecx, [ebp+var_4]
; Загружаем в ECX указатель на переменную var_4
push ecx
; Передаем функции near_func
указатель на var_4 как аргумент
call near_func
add esp, 8
; Вызываем near_func
mov eax, [eax]
; Как мы помним, в регистре EAX функция возвратила указатель на переменную
; типа int, - загружаем значение этой переменной в регистр EAX
cdq
; Расширяем EAX до четверного слова
add esi, eax
adc edi, edx
; Складываем два четверных слова
push edi
push esi
; Результат сложения передаем функции printf
push offset unk_406030
; Передаем указатель на строку спецификаторов
call _printf
add esp, 0Ch
pop edi
pop esi
mov esp, ebp
pop ebp
retn
main endp
Листинг 90
Как мы видим: в идентификации типа значения, возращенного оператором return ничего хитрого нет, - все прозаично. Но не будем спешить. Рассмотрим следующий пример. Как вы думаете, что именно и в каких регистрах будет возвращаться?
#include <stdio.h>
#include <string.h>
struct XT
{
char s0[4];
int x;
};
struct XT MyFunc(char *a, int b)
// функция возвращает значение типа структура "XT" по значению
{
struct XT xt;
strcpy(&xt.s0[0],a);
xt.x=b;
return xt;
}
main()
{
struct XT xt;
xt=MyFunc("Hello, Sailor!",0x666);
printf("%s %x\n",&xt.s0[0],xt.x);
}
Листинг 91 Пример демонстрирующий возвращения структуры по значению
Заглянем в откомпилированный результат:
MyFunc proc near ; CODE XREF: sub_401026+10p
var_8 = dword ptr -8
var_4 = dword ptr –4
; Эти локальные переменные на самом деле элементы "расщепленной" структуры XT
; Как уже говорилось в главе "Идентификация объектов, структур и массивов",
; компилятор всегда стремится обращаться к элементам структуры по их фактическим
; адресам, а не через базовый указатель.
; Поэтому, не так-то просто отличить структуру от несвязанных между собой переменных,
; а под час это и вовсе невозможно!
arg_0 = dword ptr 8
arg_4 = dword ptr 0Ch
; Функция принимает два аргумента
push ebp
mov ebp, esp
; Открываем кадр стека
sub esp, 8
; Резервируем место для локальных переменных
mov eax, [ebp+arg_0]
; Загружаем в регистр EAX содержимое аргумента arg_0
push eax
; Передаем arg_0 функции strcpy, следовательно,
; arg_0 представляет собой указатель на строку.
lea ecx, [ebp+var_8]
; Загружаем в ECX указатель на локальную переменную var_8 и…
push ecx
;...передаем его функции strcpy
; Следовательно, var_8 – строковой буфер размером 4 байта
call strcpy
add esp, 8
; Копируем переданную через arg_0 строку в var_8
mov edx, [ebp+arg_4]
; Загружаем в регистр EDX значение аргумента arg_4
mov [ebp+var_4], edx
; Копируем arg_4 в локальную переменную var_4
mov eax, [ebp+var_8]
; Загружаем в EAX содержимое (не указатель!) строкового буфера
mov edx, [ebp+var_4]
; Загружаем в EDX значение переменной var_4
; Столь явная загрузка регистров EDX:EAX перед выходом из функции указывает
; на то, что это и есть значение, взращаемое функцией.
; Надо же какой неожиданный сюрприз! Функция возвращает в EDX
и EAX
; две переменные различного типа! А вовсе не __int64, как могло бы показаться
; при беглом анализе программы.
; Второй сюрприз – возврат типа char[4] не через указатель или ссылку, а через
; регистр!
; Нам еще повезло, если бы структура была объявлена как
; struct XT{short int a, char b, char c}, в регистре EAX возвратились бы
; целых три переменные двух типов!
mov esp, ebp
pop ebp
retn
MyFunc endp
main proc near ; CODE XREF: start+AFp
var_8 = dword ptr -8
var_4 = dword ptr –4
; Две локальные переменные типа int
; Тип установлен путем вычисления размера каждой из них
push ebp
mov ebp, esp
; Открываем кадр стека
sub esp, 8
; Резервируем восемь байт под локальные переменные
push 666h
; Передаем функции MyFunc аргумент типа int
; Следовательно, arg_4 имеет тип int (по коду вызываемой функции это не было
; очевидно, - arg_4 с не меньшим успехом мог оказаться и указателем).
; Значит, в регистре EDX функция возвращает тип int
push offset aHelloSailor ; "Hello, Sailor!"
; Передаем функции MyFunc указатель на строку
; Внимание! Строка занимает более 4-х байт, поэтому, не рекомендуется
; запускать этот пример "вживую".
call MyFunc
add esp, 8
; Вызываем MyFunc. Она неким образом изменяет регистры EDX
и EAX
; Мы уже знаем типы возвращаемых в них значений и остается только
; удостоверится – "правильно" ли они используются вызывающей функцией.
mov [ebp+var_8], eax
; Заносим в локальную переменную var_8 содержимое регистра EAX
mov [ebp+var_4], edx
; Заносим в локальную переменную var_4 содержимое регистра EDX
; Согласитесь, – очень похоже на то, что функция возвращает __int64
mov eax, [ebp+var_4]
; Загружаем в EAX содержимое var_4
; (т.е. регистра EDX, возвращенного функцией MyFunc) и…
push eax
; …передаем его функции printf
; Согласно строки спецификаторов, это тип int
; Следовательно, в EDX функция возвратила int или, по крайней мере, его
; старшую часть
lea ecx, [ebp+var_8]
; Загружаем в ECX указатель на переменную var_8, хранящую значение,
; возвращенное функцией через регистр EAX.
; Согласно строки спецификаторов, это указатель на строку
; Итак, мы подтвердили, что типы значений, возвращенных через регистры EDX:EAX
; различны!
; Немного поразмыслив, мы даже сможем восстановить подлинный прототип:
; struct X{char a[4]; int} MyFunc(char* b, int c);
push ecx
push offset aSX ; "%s %x\n"
call _printf
add esp, 0Ch
mov esp, ebp
pop ebp
; Закрываем кадр стека
retn
main endp
Листинг 92
А теперь слегка изменим структуру XT, заменив char s0[4]
на char9 s0[10], что гарантированно не влезает в регистры EDX:AX и посмотрим, как изменится от этого код:
main proc near ; CODE XREF: start+AFp
var_20 = byte ptr -20h
var_10 = dword ptr -10h
var_C = dword ptr -0Ch
var_8 = dword ptr -8
var_4 = dword ptr -4
push ebp
mov ebp, esp
; Отрываем кадр стека
sub esp, 20h
; Резервируем 0x20 байт под локальные переменные
push 666h
; Передаем функции MyFunc крайний правый аргумент – значение 0x666 типа int
push offset aHelloSailor ; "Hello, Sailor!"
; Передаем функции MyFunc второй справа аргумент – указатель на строку
lea eax, [ebp+var_20]
; Загружаем в EAX адрес локальной переменной var_20
push eax
; Передаем функции MyFunc указатель на переменную var_20
; Стоп! Этого аргумента не было в прототипе функции! Откуда же он взялся?!
; Верно, не было. Его вставил компилятор для возвращения структуры по значению.
; Последнюю фразу вообще-то стоило заключить в кавычки для придания ей
; ироничного оттенка – структура, возвращаемая по значению, в действительности
; возвращается по ссылке.
call MyFunc
add esp, 0Ch
; Вызываем MyFunc
mov ecx, [eax]
; Функция в ECX возвратила указатель на возвращенную ей по ссылке структуру
; Этот прием характерен лишь для Microsoft Visual C++, большинство компиляторов
; оставляют значение EAX на выходе неопределенным или равным нулю.
; Но, так или иначе, в ECX загружается первое двойное слово,
; на которое указывает указатель EAX. На первый взгляд, это элемент типа int
; Однако не будем бежать по перед косы и торопиться с выводами
mov [ebp+var_10], ecx
; Сохранение ECX в локальной переменной var_10
mov edx, [eax+4]
; В EDX загружаем второе двойное слово по указателю EDX
mov [ebp+var_C], edx
; Копируем его в переменную var_C
; Выходит, что и второй элемент структуры – имеет тип int?
; Мы, знающие как выглядел исходный текст программы, уже начинам замечать
; подвох. Что-то здесь определенно не так...
mov ecx, [eax+8]
; Загружаем третье двойное слово, от указателя EAX
и…
mov [ebp+var_8], ecx
; …копируем его в var_8. Еще один тип int? Да откуда же они берутся в таком
; количестве, когда у нас он был только один! И где, собственно, строка?
mov edx, [eax+0Ch]
mov [ebp+var_4], edx
; И еще один тип int переносим из структуры в локальную переменную. Нет, это
; выше наших сил!
mov eax, [ebp+var_4]
; Загружаем в EAX содержимое переменной var_4
push eax
; Передаем значение var_4 функции printf.
; Судя по строке спецификаторов, var_4 действительно, имеет тип int
lea ecx, [ebp+var_10]
; Получаем указатель на переменную var_10 и…
push ecx
;...передаем его функции printf
; Судя по строке спецификаторов, тип ECX
– char
*, следовательно: var_10
; и есть искомая строка. Интуиция нам подсказывает, что var_C и var_8,
; расположенные ниже ее (т.е. в более старших адресах), так же содержат
; строку. Просто компилятор вместо того чтобы вызывать srtcpy
решил, что
; будет быстрее скопировать ее самостоятельно, чем и ввел нас в заблуждение.
; Поэтому, никогда не следует торопится с идентификацией типов элементов
; структур! Тщательно проверяйте каждый байт – как он инициализируется и как
; используется. Операции пересылки в локальные переменные еще ни о чем
; не
говорят!
push offset aSX ; "%s %x\n"
call _printf
add esp, 0Ch
mov esp, ebp
pop ebp
; Закрываем кадр стека
retn
main endp
MyFunc proc near ; CODE XREF: main+14p
var_10 = dword ptr -10h
var_C = dword ptr -0Ch
var_8 = dword ptr –8
var_4 = dword ptr –4
arg_0 = dword ptr 8
arg_4 = dword ptr 0Ch
arg_8 = dword ptr 10h
; Обратите внимание, что функции передаются три аргумента, а не два, как было
; объявлено в прототипе
push ebp
mov ebp, esp
; Открываем кадр стека
sub esp, 10h
; Резервируем память для локальных переменных
mov eax, [ebp+arg_4]
; Загружаем а EAX указатель на второй справа аргумент
push eax
; Передаем указатель на arg_4 функции strcpy
lea ecx, [ebp+var_10]
; Загружаем в ECX указатель на локальную переменную var_10
push ecx
; Передаем функции strcpy указатель на локальную переменную var_10
call strcpy
add esp, 8
; Копируем строку, переданную функции MyFunc, через аргумент arg_4
mov edx, [ebp+arg_8]
; Загружаем в EDX значение самого правого аргумента, переданного MyFunc
mov [ebp+var_4], edx
; Копируем arg_8 в локальную переменную var_4
mov eax, [ebp+arg_0]
; Загружаем в EAX значение аргумента arg_0
; Как мы знаем, этот аргумент функции передает сам компилятор, и передает в нем
; указатель на локальную переменную, предназначенную для возращения структуры
mov ecx, [ebp+var_10]
; Загружаем в ECX двойное слово с локальной переменной var_10
; Как мы помним, в локальную переменную var_10 ранее была скопирована строка,
; следовательно, сейчас мы вновь увидим ее "двухсловное" копирование!
mov [eax], ecx
mov edx, [ebp+var_C]
mov [eax+4], edx
mov ecx, [ebp+var_8]
mov [eax+8], ecx
; И точно! Из локальной переменной var_10 в локальную переменную *arg_0
; копирование происходит "вручную", а не с помощью strcpy!
; В общей сложности сейчас было скопировано 12 байт, значит, первый элемент
; структуры выглядит так: char s0[12].
; Да, конечно, в исходном тесте было 'char s0[10]', но компилятор,
; выравнивая элементы структуры по адресам, кратным четырем, перенес второй
; элемент – int x, по адресу base+0x12, тем самым создав "дыру" между концом
; строки и началом второго элемента.
; Анализ дизассемблерного листинга не позволяет восстановить истинный вид
; структуры, единственное, что можно сказать – длина строки s0
; лежит в интервале [9 - 12]
;
mov edx, [ebp+var_4]
mov [eax+0Ch], edx
; Копируем переменную var_4 (содержащую аргумент arg_8) в [eax+0C]
; Действительно, второй элемент структуры -int x- расположен по смещению
; 12 байт от ее начала.
mov eax, [ebp+arg_0]
; Возвращаем в EAX указатель на аргумент arg_0, содержащий указатель на
; возращенную структуру
mov esp, ebp
pop ebp
; Закрываем кадр стека
retn
; Итак, прототип функции выглядит так:
; struct X {char s0[12], int a} MyFunc(struct X *x, char *y, int z)
;
MyFunc endp
Листинг 93
Возникает вопрос – а как возвращаются структуры, состоящие из сотен и тысяч байт? Ответ: они копируются в локальную переменную, неявно переданную компилятором по ссылке, инструкцией MOVS, в чем мы сейчас и убедимся, изменив в исходном тексте предыдущего примера "char s0[10]", на "char s0[0x666]". Результат перекомпиляции должен выглядеть так:
MyFunc proc near ; CODE XREF: main+1Cp
var_66C = byte ptr -66Ch
var_4 = dword ptr -4
arg_0 = dword ptr 8
arg_4 = dword ptr 0Ch
arg_8 = dword ptr 10h
push ebp
mov ebp, esp
; Открываем кадр стека
sub esp, 66Ch
; Резервируем память для локальных переменных
push esi
push edi
; Сохраняем регистры в стеке
mov eax, [ebp+arg_4]
push eax
lea ecx, [ebp+var_66C]
push ecx
call strcpy
add esp, 8
; Копируем переданную функции строку в локальную переменную var_66C
mov edx, [ebp+arg_8]
mov [ebp+var_4], edx
; Копируем аргумент arg_8 в локальную переменную var_4
mov ecx, 19Bh
; Заносим в ECX значение 0x19B, пока еще не понимая, что оно выражает
lea esi, [ebp+var_66C]
; Устанавливаем регистр ESI на локальную переменную var_66C
mov edi, [ebp+arg_0]
; Устанавливаем регистр EDI на переменную на которую указывает
; указатель, переданный в аргументе arg_0
repe movsd
; Копируем ECX двойных слов с ESI в EDI
; Переводя это в байты, получаем: 0x19B*4 = 0x66C
; Таким образом, копируется и строка var_66C, и переменная var_4
mov eax, [ebp+arg_0]
; Возвращаем в EAX указатель на возвращенную структуру
pop edi
pop esi
mov esp, ebp
pop ebp
; Закрываем кадр стека
retn
MyFunc endp
Листинг 94
Следует учитывать, что многие компиляторы (например, WATCOM) передают функции указатель на буфер для возвращаемого значения не через стек, а через регистр, причем регистр по обыкновению берется не из очереди кандидатов в порядке предпочтения (см. таблицу 6), а используется особый регистр, специально предназначенный для этой цели. Например, у WATCOM-а это регистр ESI.
::возвращение вещественных значений.
Соглашения cdecl и stdcall предписывают возвращать вещественные значения (float, double, long double) через стек сопроцессора, значение же регистров EAX и EDX на выходе из такой функции может быть любым (другими словами, функции, возвращающие вещественные значения, оставляют регистры EAX и EDX в неопределенном состоянии).
fastcall-функции теоретически могут возвращать вещественные переменные и в регистрах, но на практике до этого дело обычно не доходит, поскольку, сопроцессор не может напрямую читать регистры основного процессора и их приходится проталкивать через оперативную память, что сводит на нет всю выгоду быстрого вызова.
Для подтверждения сказанного исследуем следующий пример:
#include <stdio.h>
float MyFunc(float a, float b)
{
return a+b;
}
main()
{
printf("%f\n",MyFunc(6.66,7.77));
}
Листинг 95 Пример, демонстрирующий возвращение вещественных значений
Результат его компиляции Microsoft Visual C++ должен выглядеть приблизительно так:
main proc near ; CODE XREF: start+AFp
var_8 = qword ptr -8
push ebp
mov ebp, esp
; Открываем кадр стека
push 40F8A3D7h
push 40D51EB8h
; Передаем функции MyFunc аргументы. Пока еще мы не можем установить их тип
call MyFunc
fstp [esp+8+var_8]
; Стягиваем со стека сопроцессора вещественное значение, занесенное туда
; функцией MyFunc
; Чтобы определить его тип смотрим опкод инструкции, – DD
1C 24
; По таблице 10 определяем – он принадлежит double
; Постой, постой, как double, ведь функция должна возвращать float?!
; Так-то оно так, но здесь имеет место неявное преобразование типов
; при передаче аргумента функции printf, ожидающей double.
; Обратите внимание на то, куда стягивается возращенное функцией значение:
; [esp+8-8] == [esp], т.е. оно помещается на вершину стека, что равносильно
; его заталкиваю командами PUSH.
push offset aF ; "%f\n"
; Передаем функции printf указатель на строку спецификаторов "%f\n"
call _printf
add esp, 0Ch
pop ebp
retn
main endp
MyFunc proc near ; CODE XREF: main+Dp
arg_0 = dword ptr 8
arg_4 = dword ptr 0Ch
push ebp
mov ebp, esp
; Открываем кадр стека
fld [ebp+arg_0]
; Затягиваем на вершину стека сопроцессора аргумент arg_0
; Чтобы определять его тип, смотрим на опкод инструкции FLD
- D9 45 08
; Раз так, это – float
fadd [ebp+arg_4]
; Складываем arg_0, только что затянутый на вершину стека сопроцессора, с arg_4
; помещая результат в тот же стек и…
pop ebp
retn
; ...возвращаемся из функции, оставляя результат сложения двух float-ов
; на вершине стека сопроцессора
; Забавно, если объявить функцию как double
это даст идентичный код!
MyFunc endp
Листинг 96
Замечание о механизме возращения значений в компиляторе WATCOM C: Компилятор WATCOM C предоставляет программисту возможность "вручную" выбирать: в каком именно регистре (регистрах) функция будет возвращать результат своей работы.
Это серьезно осложняет анализ, ведь (как уже было сказано выше) по общепринятым соглашениям функция не должна портить регистры EBX, ESI и EDI (BX, SI и DI в 16-разрядном коде). Увидев операцию чтения регистра ESI, идущую после вызова функции, в первую очередь мы решим, что он был инициализирован еще до ее вызова, - ведь так происходит в подавляющем большинстве случаев. Но только не с WATCOM! Этот товарищ может заставить функцию возвращать значение в любом регистре общего назначения за исключением EBP (BP), заставляя тем самым, исследовать и вызывающую и вызываемую функцию.
|
тип |
допустимые регистры |
|||||
|
однобайтовый |
AL |
BL |
CL |
DL |
||
|
AH |
BH |
CH |
DH |
|||
|
двухбайтный |
AX |
CX |
BX |
DX |
SI |
DI |
|
четырехбайтный |
EAX |
EBX |
ECX |
EDX |
ESI |
EDI |
|
восьмибайтовый |
EDX:EAX |
ECX:EBX |
ECX:EAX |
ECX:ESI |
EDX:EBX |
EBX:EAX |
|
EDI:EAX |
ECX:EDI |
EDX:ESI |
EDI:EBX |
ESI:EAX |
ECX:EDX |
|
|
EDX:EDI |
EDI:ESI |
ESI:EBX |
||||
|
ближний указатель |
EAX |
EBX |
ECX |
EDX |
ESI |
EDI |
|
дальний указатель |
DX:EAX |
CX:EBX |
CX:EAX |
CX:ESI |
DX:EBX |
DI:EAX |
|
CX:EDI |
DX:ESI |
DI:EBX |
SI:EAX |
CX:EDX |
DX:EDI |
|
|
DI:ESI |
SI:EBX |
BX:EAX |
FS:ECX |
FS:EDX |
FS:EDI |
|
|
FS:ESI |
FS:EBX |
FS:EAX |
GS:ECX |
GS:EDX |
GS:EDI |
|
|
GS:ESI |
GS:EBX |
GS:EAX |
DS:ECX |
DS:EDX |
DS:EDI |
|
|
DS:ESI |
DS:EBX |
DS:EAX |
ES:ECX |
ES:EDX |
ES:EDI |
|
|
ES:ESI |
ES:EBX |
ES:EAX |
||||
|
float |
8087 |
??? |
??? |
??? |
??? |
??? |
|
double |
8087 |
EDX:EAX |
ECX:EBX |
ECX:EAX |
ECX:ESI |
EDX:EBX |
|
EDI:EAX |
ECX:EDI |
EDX:ESI |
EDI:EBX |
ESI:EAX |
ECX:EDX |
|
|
EDX:EDI |
EDI:ESI |
ESI:EBX |
EBX:EAX |
В частности, через регистр EAX может возвращаться и переменная типа int и структура из четырех переменных типа char (или двух char или одного short int)
Покажем, как это выглядит на практике. Рассмотрим следующий пример:
#include <stdio.h>
int MyFunc(int a, int b)
{
#pragma aux MyFunc value
[ESI]
// Прагма AUX вкупе с ключевым словом "value" позволяет вручную задавать регистр
// через который будет возращен результат вычислений.
// В данном случае его предписывается возвращать через ESI
return a+b;
}
main()
{
printf("%x\n",MyFunc(0x666,0x777));
}
Листинг 97 Пример, демонстрирующий возвращение значения в произвольном регистре
Результат компиляции этого примера должен выглядеть приблизительно так:
main_ proc near ; CODE XREF: __CMain+40p
push 14h
call __CHK
; Проверка стека на переполнение
push edx
push esi
; Сохраняем ESI и EDX
; Это говорит о том, что данный компилятор придерживается соглашения
; о сохранении ESI. Команды сохранения EDI не видно, однако, этот регистр
; не модифицируется данной функцией и, стало быть, сохранять его незачем
mov edx, 777h
mov eax, 666h
; Передаем функции MyFunc два аргумента типа int
call MyFunc
; Вызываем MyFunc. По общепринятым соглашениям EAX, EDX
и под час ECX
; на выходе из функции содержат либо неопределенное,
; либо возращенное функцией значение
; Остальные регистры в общем случае должны быть сохранены
push esi
; Передаем регистр ESI функции printf. Мы не можем с уверенностью сказать:
; содержит ли он значение, возращенное функцией, или был инициализирован еще
; до ее вызова
push offset asc_420004 ; "%x\n"
call printf_
add esp, 8
pop esi
pop edx
retn
main_ endp
MyFunc proc near ; CODE XREF: main_+16p
push 4
call __CHK
; Проверка стека на переполнение
lea esi, [eax+edx]
; А вот уже знакомый нам хитрый трюк со сложением. На первый взгляд в ESI
; загружается указатель на EAX+EBX, - фактически так оно и происходит, но ведь
; указатель на EAX+EBX
в то же время является и их суммой, т.е. эта команда
; эквивалентна ADD EAX,EDX/MOV ESI,EAX.
; Это и есть возвращаемое функцией значение, - ведь ESI
был модифицирован, и
; не сохранен!
; Таким образом, вызывающая функция командой PUSH ESI
передает printf
; результат сложения 0x666 и 0x777, что и требовалось выяснить
retn
MyFunc endp
Листинг 98
Возращение значений in-line assembler функциями. Создать ассемблерной функции волен возвращать значения в любых регистрах, каких ему будет угодно, однако, поскольку вызывающие функции языка высокого уровня ожидают увидеть результат вычислений в строго определенных регистрах, писаные соглашения приходится соблюдать. Другое дело, "внутренние" ассемблерные функции – они могут вообще не придерживаться никаких правил, что и демонстрирует следующий пример:
#include <stdio.h>
// naked-функция, не имеющая прототипа, - обо всем должен заботится сам программист!
__declspec( naked ) int MyFunc()
{
__asm{
lea ebp, [eax+ecx] ; возвращаем в EBP сумму EAX и
ECX
; Такой трюк допустим лишь при условии, что эта
; функция будет вызываться из ассемблерной функции,
; знающей через какие регистры передаются аргументы
; и через какие – возвращается результат вычислений
ret
}
}
main()
{
int a=0x666;
int b=0x777;
int c;
__asm{
push ebp
push edi
mov eax,[a];
mov ecx,[b];
lea edi,c
// Вызываем функцию MyFunc из ассемблерной функции, передавая ей аргументы
// через те регистры, которые она "хочет"
call MyFunc;
// Принимаем возращенное в EBP значение и сохраняем его в локальной переменной
mov [edi],ebp
pop edi
pop ebp
}
printf("%x\n",c);
}
Листинг 99 Пример, демонстрирующий возвращение значения встроенными ассемблерными функциями
Результат компиляции Microsoft Visual C++ ( а другие компиляторами этот пример откомпилировать и вовсе не удастся, ибо они не поддерживают ключевое слово naked) должен выглядеть так:
MyFunc proc near ; CODE XREF: main+25p
lea ebp, [eax+ecx]
; Принимаем аргументы через регистры EAX
и ECX, возвращая через регистр EBP
; их сумму
; Кончено, пример несколько надуман, зато нагляден!
retn
MyFunc endp
main proc near ; CODE XREF: start+AFp
var_C = dword ptr -0Ch
var_8 = dword ptr -8
var_4 = dword ptr -4
push ebp
mov ebp, esp
; Открываем кадр стека
sub esp, 0Ch
; Резервируем место для локальных переменных
push ebx
push esi
push edi
; Сохраняем изменяемые регистры
mov [ebp+var_4], 666h
mov [ebp+var_8], 777h
; Инициализируем переменные var_4 и var_8
push ebp
push edi
; Сохраняем регистры или передаем их функции? Пока нельзя ответить
; однозначно
mov eax, [ebp+var_4]
mov ecx, [ebp+var_8]
; Загружаем в EAX значение переменной var_4, а в ECX – var_8
lea edi, [ebp+var_C]
; Загружаем в EDI указатель на переменную var_C
call MyFunc
; Вызываем MyFunc – из анализа вызывающей функции не очень понятно как
; ей передаются аргументы. Может через стек, а может и через регистры.
; Только исследование кода MyFunc позволяет установить, что верным оказывается
; последнее предположение. Да, - аргументы передаются через регистры!
mov [edi], ebp
; Что бы это значило? Анализ одной лишь вызывающей функции не может дать
; исчерпывающего ответа и только анализ вызываемой подсказывает, что
; через EBP она возвращает результат вычислений.
pop edi
pop ebp
; Восстанавливаем измененные регистры
; Это говорит о том, что выше эти регистры действительно сохранялись в стеке
; а не передавались функции в качестве аргументов
mov eax, [ebp+var_C]
; Загружаем в EAX содержимое переменной var_C
push eax
push offset unk_406030
call _printf
add esp, 8
; Вызываем printf
pop edi
pop esi
pop ebx
; Восстанавливаем регистры
mov esp, ebp
pop ebp
; Закрываем кадр стека
retn
main endp
Листинг 100
:: возврат значений через аргументы, переданные по ссылке. Идентификация значений, возращенных через аргументы, переданные по ссылке, тесно переплетается с идентификацией самих аргументов (см. главу "Идентификация аргументов функций"). Выделив среди аргументов, переданных функции, указатели – заносим их в список кандидатов на возвращаемые значения.
Теперь поищем: нет ли среди них указателей на неинициализированные переменные, – очевидно, их инициализирует сама вызываемая функция. Однако не стоит вычеркивать указатели на инициализированные переменные (особенно равные нулю) – они так же могут возвращать значения. Уточнить ситуацию позволит анализ вызываемой функции – нас будут интересовать все операции модификации переменных, переданных по ссылке. Только не спутайте это с модификацией переменных, переданных по значению. Последние автоматически умирают в момент завершения функции (точнее – вычистки аргументов из стека). Фактически – это локальные переменные функции и она безболезненно может изменять их как ей вздумается.
#include <stdio.h>
#include <string.h>
// Функция инвертирования строки src
с ее записью в строку dst
void Reverse(char *dst, const char *src)
{
strcpy(dst,src);
_strrev( dst);
}
// Функция инвертирования строки s
// (результат записывается в саму же строку s)
void Reverse(char *s)
{
_strrev( s );
}
// Функция возращает сумму двух аргументов
int sum(int a,int b)
{
// Мы можем безболезненно модифицировать аргументы, переданные по значению,
// обращаясь с ними как с обычными локальными переменными
a+=b;
return a;
}
main()
{
char s0[]="Hello,Sailor!";
char s1[100];
// Инвертируем строку s0, записывая ее в s1
Reverse(&s1[0],&s0[0]);
printf("%s\n",&s1[0]);
// Инвертируем строку s1, перезаписывая ее
Reverse(&s1[0]);
printf("%s\n",&s1[0]);
// Выводим сумму двух числел
printf("%x\n",sum(0x666,0x777));
}
Листинг 101 Пример, демонстрирующий возврат значений через переменные, переданные по ссылке
Результат компиляции этого примера должен выглядеть приблизительно так:
main proc near ; CODE XREF: start+AFp
var_74 = byte ptr -74h
var_10 = dword ptr -10h
var_C = dword ptr -0Ch
var_8 = dword ptr -8
var_4 = word ptr -4
push ebp
mov ebp, esp
; Открываем кадр стека
sub esp, 74h
; Резервируем память для локальных переменных
mov eax, dword ptr aHelloSailor ; "Hello,Sailor!"
; Заносим в регистр EAX четыре первых байта строки "Hello, Sailor!"
; Вероятно, компилятор копирует строку в локальную переменную таким
; хитро-тигриным способом
mov [ebp+var_10], eax
mov ecx, dword ptr aHelloSailor+4
mov [ebp+var_C], ecx
mov edx, dword ptr aHelloSailor+8
mov [ebp+var_8], edx
mov ax, word ptr aHelloSailor+0Ch
mov [ebp+var_4], ax
; Точно, строка "Hello,Sailor!" копируется в локальную переменную var_10
; типа char s[0x10]
; Число 0x10 было получено подсчетом количества копируемых байт –
; четыре итерации по четыре байт в каждой – итого, шестнадцать!
lea ecx, [ebp+var_10]
; Загрузка в ECX указателя на локальную переменную var_10,
; содержащую строку "Hello, World!"
push ecx ; int
; Передача функции Reverse_1 указателя на строку "Hello, World!"
; Смотрите, - IDA неверно определила тип, - ну какой же это int,
; когда это char *
; Однако, вспомнив, как копировалась строка, мы поймем, почему ошиблась IDA
lea edx, [ebp+var_74]
; Загрузка в ECX указателя на неинициализированную локальную переменную var_74
push edx ; char *
; Передача функции Reverse_1 указателя на неинициализированную переменную
; типа char s1[100]
; Число 100 было получено вычитанием смещения переменной var_74 от смещения
; следующей за ней переменной, var_10, содержащей строку "Hello, World!"
; 0x74 – 0x10 = 0x64 или в десятичном представлении - 100
; Факт передачи указателя на неинициализированную переменную говорит о том,
; что, скорее всего, функция возвратит через нее некоторое значение –
; возьмите это себе на заметку.
call Reverse_1
add esp, 8
; Вызов функции Reverse_1
lea eax, [ebp+var_74]
; Загрузка в EAX указателя на переменную var_74
push eax
; Передача функции printf указателя на переменную var_74, - поскольку,
; вызывающая функция не инициализировала эту переменную, можно предположить,
; что вызываемая возвратила в через нее свое значение
; Возможно, функция Reverse_1 модифицировала и переменную var_10, однако,
; об этом нельзя сказать с определенностью до тех пор пока не будет
; изучен ее код
push offset unk_406040
call _printf
add esp, 8
; Вызов функции printf для вывода строки
lea ecx, [ebp+var_74]
; Загрузка в ECX указателя на переменную var_74, по-видимому,
; содержащую возращенное функцией Reverse_1 значение
push ecx ; char *
; Передача функции Reverse_2 указателя на переменную var_74
; Функция Reverse_2 так же может возвратить в переменной var_74
; свое значение, или некоторым образом, модифицировать ее
; Однако может ведь и не возвратить!
; Уточнит ситуацию позволяет анализ кода вызываемой функции.
call Reverse_2
add esp, 4
; Вызов функции Reverse_2
lea edx, [ebp+var_74]
; Загрузка в EDX указателя на переменную var_74
push edx
; Передача функции printf указателя на переменную var_74
; Поскольку, значение, возвращенное функцией через регистры EDX:EAX
; не используется, можно предположить, что она возвращает его не через
; регистры, а в переменной var_74. Но это не более чем предположение
push offset unk_406044
call _printf
add esp, 8
; Вызов
функции printf
push 777h
; Передача функции Sum значения 0x777 типа int
push 666h
; Передача функции Sum значения 0x666 типа int
call Sum
add esp, 8
; Вызов
функции Sum
push eax
; В регистре EAX содержится возращенное функцией Sum
значение
; Передаем его функции printf в качестве аргумента
push offset unk_406048
call _printf
add esp, 8
; Вызов
функции printf
mov esp, ebp
pop ebp
; Закрытие кадра стека
retn
main endp
; int __cdecl Reverse_1(char *,int)
; Обратите внимание, что прототип функции определен неправльно!
; На самом деле, как мы уже установили из анализа вызывающей функции, он выглядит так:
; Reverse(char *dst, char *src)
; Название аргументов дано на основании того, что левый аргумент – указатель
; на неинициализированный буфер и, скорее всего, он выступает в роли приемника,
; соответственно, правый аргумент в таком случае – источник.
Reverse_1 proc near ; CODE XREF: main+32p
arg_0 = dword ptr 8
arg_4 = dword ptr 0Ch
push ebp
mov ebp, esp
; Открываем кадр стека
mov eax, [ebp+arg_4]
; Загружаем в EAX значение аргумента arg_4
push eax
; Передаем arg_4 функции strcpy
mov ecx, [ebp+arg_0]
; Загружаем в ECX значение аргумента arg_0
push ecx
; Передаем arg_0 функции strcpy
call strcpy
add esp, 8
; Копируем содержимое строки, на которую указывает arg_4, в буфер
; на который указывает arg_0
mov edx, [ebp+arg_0]
; Загружаем в EDX содержимое аргумента arg_0, указывающего на буфер,
; содержащий только что скопированную строку
push edx ; char *
; Передаем функции __strrev arg_0
call __strrev
add esp, 4
; функция strrev инвертирует строку, на которую указывает arg_0
; следовательно, функция Reverse_1 действительно возвращает свое значение
; через аргумент arg_0, переданный по ссылке.
; Напротив, строка на которую указывает arg_4, остается неизменной, поэтому,
; прототип функции Reverse_1 выглядит так:
; void Reverse_1(char *dst, const char *src);
; Никогда не пренебрегайте квалификатором const, т.к. он ясно указывает на
; то, что переменная, на которую указывает данный указатель используется
; лишь на чтение. Эта информация значительно облегчит работу с
; дизассемблерным листингом, особенно когда вы вернетесь к нему спустя
; некоторое время, основательно подзабыв алгоритм исследуемой программы
pop ebp
; Закрываем кадр стека
retn
Reverse_1 endp
; int __cdecl Reverse_2(char *)
; А вот на этот раз прототип функции определен верно!
; (Ну, за исключением того, что возвращаемый тип void, а не int)
Reverse_2 proc near ; CODE XREF: main+4Fp
arg_0 = dword ptr 8
push ebp
mov ebp, esp
; Открываем кадр стека
mov eax, [ebp+arg_0]
; Загружаем в EAX содержимое аргумента arg_0
push eax ; char *
; Передаем arg_0 функции strrev
call __strrev
add esp, 4
; Инвертируем строку, записывая результат на то же самое место
; Следовательно, функция Reverse_2 действительно возвращает значение
; через arg_0, и наше предварительное предположение оказалось правильным!
pop ebp
; Закрываем кадр стека
retn
; Прототип функции Reverse_2 по данным последних исследований выглядит так:
; void Reverse_2(char *s)
Reverse_2 endp
Sum proc near ; CODE XREF: main+72p
arg_0 = dword ptr 8
arg_4 = dword ptr 0Ch
push ebp
mov ebp, esp
; Открываем кадр стека
mov eax, [ebp+arg_0]
; Загружаем в EAX значение аргумента arg_0
add eax, [ebp+arg_4]
; Складываем arg_0 с arg_4, записывая результат в EAX
mov [ebp+arg_0], eax
; Копируем результат сложения arg_0 и arg_4 обратно в arg_0
; Неопытные хакеры могут принять это за возращение значения через аргумент,
; однако, это предположение неверно.
; Дело в том, что аргументы, переданные функции, после ее завершения
; выталкиваются из стека и тут же "погибают". Не забывайте:
; Аргументы, переданные по значению, ведут себя так же, как и локальные
; переменные.
mov eax, [ebp+arg_0]
; А вот сейчас в регистр EAX действительно копируется возвращаемое значение
; Следовательно, прототип функции выглядит так:
; int Sum(int a, int b);
pop ebp
; Закрываем кадр стека
retn
Sum endp
Листинг 102
::возврат значений через динамическую память (кучу). Возращение значения через аргумент, переданный по ссылке, не очень-то украшает прототип функции. Он вмиг перестает быть интуитивно – понятным и требует развернутых пояснений, что с этим аргументом ничего передать не надо, напротив – будьте готовы отсюда принять. Но хвост с ней, с наглядностью и эстетикой (кто говорил, что был программистом легко?), существует и более серьезная проблема – далеко не во всех случаях размер возвращаемых данных известен наперед, - частенько он выясняется лишь в процессе работы вызываемой функции. Выделить буфер "с запасом"? Некрасиво и неэкономично – даже в системах с виртуальной памятью ее объем не безграничен.
Вот если бы вызываемая функция самостоятельно выделяла для себя память, как раз по потребности, а потом возвращала на нее указатель. Сказано – сделано! Ошибка многих начинающих программистов как раз и заключается в попытке вернуть указать на локальные переменные, - увы, они "умирают" вместе с завершением функции и указатель указывает в "космос". Правильное решение заключается в выделении памяти из кучи (динамической памяти), скажем, вызовом malloc
или new, - эта память "живет" вплоть до ее принудительного освобождения функцией free или delete соответственно.
Для анализа программы механизм выделения памяти не существенен, - основную роль играет тип возвращаемого значения. Отличить указатель от остальных типов достаточно легко – только указатель может использоваться в качестве подадресного выражения.
Разберем следующий пример:
#include <stdio.h>
#include <malloc.h>
#include <stdlib.h>
char* MyFunc(int a)
{
char *x;
x = (char *) malloc(100);
_ltoa(a,x,16);
return x;
}
main()
{
char *x;
x=MyFunc(0x666);
printf("0x%s\n",x);
free(x);
}
Листинг 103 Пример, демонстрирующий возвращения значения через кучу
main proc near ; CODE XREF: start+AFp
var_4 = dword ptr -4
push ebp
mov ebp, esp
; Открываем кадр стека
push ecx
; Выделяем память под локальную переменную размером 4 байта (см. var_4)
push 666h
; Передаем функции MyFunc значение 666 типа int
call MyFunc
add esp, 4
; Вызываем MyFunc – обратите внимание, что функции ни один аргумент
; не был передан по ссылке!
mov [ebp+var_4], eax
; Копирование содержимого возращеного функцией значение в переменную var_4
mov eax, [ebp+var_4]
; Супер! Загружаем в EAX возращенное функцией значение обратно!
push eax
; Передаем возращенное функцией значение функции printf
; Судя по спецификатору, тип возвращенного значения – char
*
; Поскольку, функции MyFunc ни один из аргументов не передавался по ссылке,
; она явно выделила память самостоятельно и записала туда полученную строку.
; А если бы функции MyFunc передавались один или более аргументов по ссылке?
; Тогда – не было бы никакой уверенности, что она не возвратила один из таких
; аргументов обратно, предварительно его модифицировав.
; Впрочем, модификация необязательно, - скажем передаем функции указатели на
; две строки и она возвращает указатель на ту из них, которая, скажем, короче
; или содержит больше гласных букв.
; Поэтому, не всякое возращение указателя свидетельствует о модификации
push offset a0xS ; "0x%s\n"
call _printf
add esp, 8
; Вызов printf – вывод на экран строки, возращенной функцией MyFunc
mov ecx, [ebp+var_4]
; В ECX загружаем значение указателя, возращенного функцией MyFunc
push ecx ; void *
; Передаем указатель, возращенный функцией MyFunc, функции free
; Значит, MyFunc действительно самостоятельно выделяла память вызовом malloc
call _free
add esp, 4
; Освобождаем память, выделенную MyFunc
для возращения значения
mov esp, ebp
pop ebp
; Закрываем кадр стека
retn
; Таким образом, протип MyFunc выглядит так:
; char* MyFunc(int a)
main endp
MyFunc proc near ; CODE XREF: main+9p
var_4 = dword ptr -4
arg_0 = dword ptr 8
push ebp
mov ebp, esp
; Открываем кадр стека
push ecx
; Резервируем память под локальные переменные
push 64h ; size_t
call _malloc
add esp, 4
; Выделяем 0x64 байта памяти из кучи либо для собственных нужд функции, либо
; для возращения результата. Поскольку из анализа кода вызывающей функции нам
; уже известно, что MyFunc возвращает указатель, очень вероятно, что вызов
; malloc
выделяет память как раз для этой цели.
; Впрочем, вызовов malloc может быть и несколько, а указатель возвращается
; только на один из них
mov [ebp+var_4], eax
; Запоминаем указатель в локальной переменной var_4
push 10h ; int
; Передаем функции __ltoa аргумент 0x10 (крайний справа) – требуемая система
; исчисления для перевода числа
mov eax, [ebp+var_4]
; Загружаем в EAX содержимое указателя на выделенную из кучи память
push eax ; char *
; Передаем функции ltoa указатель на буфер для возращения результата
mov ecx, [ebp+arg_0]
; Загружаем в EAX значение аргумента arg_0
push ecx ; __int32
; Передаем функции ltoa аргумент arg_0 – значение типа int
call __ltoa
add esp, 0Ch
; Функция ltoa переводит число в строку и записывает ее в буфер по переданному
; указателю
mov eax, [ebp+var_4]
; Возвращаем указатель на регион памяти, выделенный самой MyFunc
из кучи, и
; содержащий результат работы ltoa
mov esp, ebp
pop ebp
; Закрываем кадр стека
retn
MyFunc endp
Листинг 104
::Возврат значений через глобальные переменные. "Мыльную оперу" перепевов с возращением указателей продолжает серия "Возращение значений через глобальные переменные (и/или указателя на глобальные переменные)". Вообще-то глобальные переменные – плохой тон и такой стиль программирования характерен в основном для программистов с мышлением, необратимо искалеченным идеологий Бацика с его недоразвитым механизмом вызова подпрограмм.
Подробнее об идентификации глобальных переменных рассказывается в одноименном разделе данной главы, здесь же мы сосредоточим наши усилия именно на изучении механизмов возвращения значений через глобальные переменные.
Фактически, все глобальные переменные можно рассматривать как неявные аргументы каждой вызываемой функции и в то же время – как возвращаемые значения. Любая функция может произвольным образом читать и модифицировать их, причем, ни "передача", ни "возращение" глобальных переменных не "видны" анализом кода вызывающей функции, - для этого необходимо тщательно исследовать вызываемую – манипулирует ли она с глобальными переменными и если да, то с какими. Можно зайти и с обратной стороны, - просмотром сегмента данных найти все глобальные переменные, определить их смещение и, пройдясь контекстным поиском по всему файлу, выявить функции, которые на них ссылаются (подробнее см. "Идентификация глобальных переменных :: перекрестные ссылки").
Помимо глобальных, еще существуют и статические переменные.
Они так же располагаются в сегменте данных, но непосредственно доступны только объявившей их функции. Точнее, ограничение наложено не на сами переменных, а на их имена. Чтобы предоставить другим функциям доступ к собственным статическим переменным достаточно передать указатель. К счастью, этот трюк не создает хакерам никаких проблем (хоть некоторые злопыхатели и объявляют его "прорехой в защите"), - отсутствие непосредственного доступа к "чужим" статическим переменным и необходимость взаимодействовать с функцией-владелицей через предсказуемый интерфейс (возращенный указатель), позволяет разбить программу на отдельные независимые модули, каждый из которых может быть проанализирован отдельно. Чтобы не быть голословным, продемонстрируем это на следующем примере:
#include <stdio.h>
char* MyFunc(int a)
{
static char x[7][16]={"Понедельник", "Вторник", "Среда", "Четверг", "Пятница",
"Суббота", "Воскресенье"};
return
&x[a-1][0];
}
main()
{
printf("%s\n",MyFunc(6));
}
Листинг 105 Пример, демонстрирующий возврат значения через глобальные статические переменные
Результат компиляции компилятором Microsoft Visual C++ 6.0 c настройками по умолчанию выглядит так:
MyFunc proc near ; CODE XREF: main+5p
arg_0 = dword ptr 8
push ebp
mov ebp, esp
; Открываем кадр стека
mov eax, [ebp+arg_0]
; Загружаем в EAX значение аргумента arg_0
sub eax, 1
; Уменьшаем EAX на единицу. Это косвенно свидетельствует о том, что arg_0 –
; не указатель, хотя математические операции над указателями в Си разрешены
; и активно используются
shl eax, 4
; Умножаем (arg_0 –1) на 16. Битовый сдвиг вправо на четыре равносилен 24 == 16
add eax, offset aPonedelNik ; "Понедельник"
; Складываем полученное значение с базовым указателем на таблицу строк,
; расположенных в сегменте данных. А в сегменте данных находятся либо
; статические, либо глобальные переменные.
; Поскольку, значение аргумента arg_0 умножаемся на некоторую величину
; (в данном случае на 16), можно предположить, что мы имеем дело с
; двухмерным массивом. В данном случае – массивом строк фиксированной длины.
; Таким образом, в EAX содержится указатель на строку с индексом arg_0 – 1
; Или, другими словами, – с индексом arg_0, считая с одного.
pop ebp
; Закрываем кадр стека, возвращая в регистре EAX
указатель на соответствующий
; элемент массива.
; Как мы видим, нет никакой принципиальной разницы между возвращением указателя
; на регион памяти, выделенный из кучи, с возращением указателя на статические
; переменные, расположенные в сегменте данных.
retn
MyFunc endp
main proc near ; CODE XREF: start+AFp
push ebp
mov ebp, esp
; Открываем кадр стека
push 6
; Передаем функции MyFunc значение типа int
; (шестой день – суббота)
call MyFunc
add esp, 4
; Вызываем MyFunc
push eax
; Передаем возращенное MyFunc значение функции printf
; Судя по строке спецификаторов, это – указатель на строку
push offset aS ; "%s\n"
call _printf
add esp, 8
pop ebp
; Закрываем кадр стека
retn
main endp
aPonedelNik db 'Понедельник',0,0,0,0,0 ; DATA XREF: MyFunc+Co
; Наличие перекрестной ссылки только на одну функцию, подсказывает, что тип
; этой переменной – static
aVtornik db 'Вторник',0,0,0,0,0,0,0,0,0
aSreda db 'Среда',0,0,0,0,0,0,0,0,0,0,0
aCetverg db 'Четверг',0,0,0,0,0,0,0,0,0
aPqtnica db 'Пятница',0,0,0,0,0,0,0,0,0
aSubbota db 'Суббота',0,0,0,0,0,0,0,0,0
aVoskresenE db 'Воскресенье',0,0,0,0,0
aS db '%s',0Ah,0 ; DATA XREF: main+Eo
Листинг 106
А теперь сравним предыдущий пример с настоящими глобальными переменными:
#include <stdio.h>
int a;
int b;
int c;
MyFunc()
{
c=a+b;
}
main()
{
a=0x666;
b=0x777;
MyFunc();
printf("%x\n",c);
}
Листинг 107 Пример, демонстрирующий возврат значения через глобальные переменные
main proc near ; CODE XREF: start+AFp
push ebp
mov ebp, esp
; Открываем кадр стека
call MyFunc
; Вызываем MyFunc. Обратите внимание – функции явно ничего не передается
; и ничего не возвращается. Потому, ее прототип выглядит
; (по предварительным заключением) так:
; void MyFunc()
call Sum
; Вызываем функцию Sum, явно не принимающую и не возвращающую никаких значений
; Ее предварительный прототип выглядит так: void Sum()
mov eax, c
; Загружаем в EAX значение глобальной переменной 'c'
; Смотрим в сегмент данных, - так-так, вот она переменная 'c', равная нулю
; Однако этому значению нельзя доверять – быть может, ее уже успели изменить
; ранее вызванные функции.
; Предположение о модификации подкрепляется парой перекрестных ссылок,
; одна из которых указывает на функцию Sum. Суффикс 'w', завершающий
; перекрестную ссылку, говорит о том, что Sum
записывает в переменную 'c'
; какое-то значение. Какое? Это можно узнать из анализа кода самой Sum.
push eax
; Передаем значение, возращенное функцией Sum, через глобальную переменную 'c'
; функции printf.
; Судя по строке спецификаторов, аргумент имеет тип int
push offset asc_406030 ; "%x\n"
call _printf
add esp, 8
; Выводим возвращенный Sum результат на терминал
pop ebp
; Закрываем кадр стека
retn
main endp
Sum proc near ; CODE XREF: main+8p
; Функция Sum не принимает через стек никаких аргументов!
push ebp
mov ebp, esp
; Открываем кадр стека
mov eax, a
; Загружаем в EAX значение глобальной переменной 'a'
; Находим 'a' в сегменте данных, - ага, есть перекрестная ссылка на MyFunc,
; которая что-то записывает в переменную 'a'.
; Поскольку, вызов MyFunc предшествовал вызову Sum, можно сказать, что MyFunc
; возвратила в 'a' некоторое значение
add eax, b
; Складываем EAX (хранящий значение глобальной переменной 'a') с содержимым
; глобальной переменной 'b'
; (все, сказанное выше относительно 'a', справедливо и для 'b')
mov c, eax
; Помещаем результат сложения a+b в переменную 'c'
; Как мы уже знаем (из анализа функции main), функция Sum
в переменной 'c'
; возвращает результат своих вычислений. Теперь мы узнали – каких именно.
pop ebp
; Закрываем кадр стека
retn
Sum endp
MyFunc proc near ; CODE XREF: main+3p
push ebp
mov ebp, esp
; Открываем кадр стека
mov a, 666h
; Присваиваем глобальной переменной 'a' значение 0x666
mov b, 777h
; Присваиваем глобальной переменной 'b' значение 0x777
; Как мы выяснили из анализа двух предыдущих функций – функция MyFunc
; возвращает в переменных а и b
результат своих вычислений
; Теперь мы определили какой именно, а вместе с тем смогли разобраться
; как три функции взаимодействуют друг с другом.
; main() вызывает MyFunc(), та инициализирует глобальные переменные 'a' и 'b',
; затем main() вызывает Sum(), помещающая сумму 'a' и 'b' в глобальную 'c',
; наконец, main() берет эту 'c' и передает ее через стек printf
; для вывода на экран.
; Уф! Как все запутано, а ведь это простейший пример из трех функций!
; Что же говорить о реальной программе, в которой этих функций тысячи, причем
; порядок вызова и поведение каждой из них далеко не так очевидны!
pop ebp
retn
MyFunc endp
a dd 0 ; DATA XREF: MyFunc+3w Sum+3r
b dd 0 ; DATA XREF: MyFunc+Dw Sum+8r
c dd 0 ; DATA XREF: Sum+Ew main+Dr
; Судя по перекрестным ссылкам – все три переменные глобальные, т.к. к
; каждой из них имеет непосредственный доступ более одной функции.
Листинг 108
::возврат значений через флаги процессора. Для большинства ассемблерных функций характерно использование регистра флагов процессора для возвращения результата успешности выполнения функции. По общепринятому соглашению установленный флаг переноса (CF) свидетельствует об ошибке, второе место по популярности занимает флаг нуля (ZF), а остальные флаги практически вообще не используются.
Установка флага переноса осуществляется командой STC
или любой математической операцией, приводящей к образованию переноса (например, CMP a, b
где a < b), а сброс – командой CLC или соответствующей математической операцией.
Проверка флага переноса обычно осуществляется условными переходами JC xxx
и JNC xxx, соответственно исполняющихся при наличии и отсутствии переноса. Условные переходы JB xxx и JNB xxx – их синтаксические синонимы, дающие при ассемблировании идентичный код.
#include <stdio.h>
// Функция сообщения об ошибке деления
Err(){ printf("-ERR: DIV by Zero\n");}
// Вывод результата деления на экран
Ok(int a){printf("%x\n",a);}
// Ассемблерная функция деления.
// Делит EAX на EBX, возвращая частное в EAX, а остаток – в EDX
// При попытке деления на ноль устанавливает флаг переноса
__declspec(naked) MyFunc()
{
__asm{
xor edx,edx ; Обнуляем EDX, т.е. команда div ожидает
делимого в EDX:EAX
test ebx,ebx ; Проверка делителя на равенство нулю
jz
_err ; Если делитель равен нулю, перейти к ветке _err
div ebx ; Делим EDX:EAX на EBX (EBX
заведомо не равен нулю)
ret ; Выход в с возвратом частного в EAX
и остатка в EDX
_err: ; // Эта ветка получает управление при попытке деления на ноль
stc ; устанавливаем флаг переноса, сигнализируя об ошибке и...
ret ; ...выходим
}
}
// Обертка для MyFunc
// Принимаем два аргумента через стек – делимое и делитель
// и выводим результат деления (или сообщение об ошибке) на экран
__declspec(naked) MyFunc_2(int a, int b)
{
__asm{
mov eax,[esp+4] ; Загружаем в EAX содержимое
аргумента
'a'
mov ebx,[esp+8] ; Загружаем в EDX содержимое аргумента 'b'
call MyFunc ; Пытаемся делить a/b
jnc
_ok ; Если флаг переноса сброшен выводим результат, иначе…
call Err ; …сообщение об ошибке
ret ; Возвращаемся
_ok:
push eax ; Передаем результат деления и…
call Ok ; …выводим его на экран
add esp,4 ; Вычищаем за собой стек
ret ; Возвращаемся
}
}
main(){MyFunc_2(4,0);}
Листинг 109
Использование WriteProcessMemory
Если требуется изменить некоторое количество байт своего (или чужого) процесса, самый простой способ сделать это – вызвать функцию WriteProcessMemory. Она позволяет модифицировать существующие страницы памяти, чей флаг супервизора не взведен, т.е., все страницы, доступные из кольца 3, в котором выполняются прикладные приложения. Совершенно бесполезно с помощью WriteProcessMemory пытаться изменить критические структуры данных операционной системы (например, page directory или page table) – они доступны лишь из нулевого кольца. Поэтому, эта функция не представляет никакой угрозы для безопасности системы и успешно вызывается независимо от уровня привилегий пользователя (автору этих строк доводилось слышать утверждение, дескать, WriteProcessMemory требует прав отладки приложений, но это не так).
Процесс, в память которого происходит запись, должен быть предварительно открыт функцией OpenProcess с атрибутами доступа "PROCESS_VM_OPERATION" и "PROCESS_VM_WRITE". Часто программисты, ленивые от природы, идут более коротким путем, устанавливая все атрибуты – "PROCESS_ALL_ACCESS". И это вполне законно, хотя справедливо считается дурным стилем программирования.
Простейший пример использования функции WriteProcessMemory для создания самомодифицирующегося кода, приведен в листинге 1. Она заменяет инструкцию бесконечного цикла "JMP short $-2" на условный переход "JZ $-2", который продолжает нормальное выполнение программы. Неплохой способ затруднить взломщику изучение программы, не правда ли? (Особенно, если вызов WriteMe расположен не возле изменяемого кода, а помещен в отдельный поток; будет еще лучше, если модифицируемый код вполне естественен сам по себе и внешне не вызывает никаких подозрений – в этом случае хакер может долго блуждать в той ветке кода, которая при выполнении программы вообще не получает управления).
int WriteMe(void *addr, int wb)
{
HANDLE h=OpenProcess(PROCESS_VM_OPERATION|PROCESS_VM_WRITE,
true,GetCurrentProcessId());
return WriteProcessMemory(h, addr,&wb,1,NULL);
}
int main(int argc, char* argv[])
{
_asm {
push 0x74 ; JMP --> > JZ
push offset Here
call WriteMe
add esp,8
Here: JMP short here
}
printf("#JMP SHORT $-2 was changed to JZ $-2\n");
return
0;
}
Листинг 227 Пример, иллюстрирующий использования функции WriteProcessMemory для создания самомодифицирующегося кода
Поскольку Windows для экономии оперативной памяти разделяет код между процессами, возникает вопрос: а что произойдет, если запустить вторую копию самомодифицирующейся программы? Создаст ли операционная система новые страницы или отошлет приложение к уже модифицируемому коду? В документации на Windows NT и Windows 2000 сказано, что они поддерживают копирование при записи (copy on write), т.е. автоматически дублируют страницы кода при попытке их модификации. Напротив, Windows 95 и Windows 98 не поддерживают такую возможность. Означает ли это то, что все копии самомодифицирующегося приложения будут вынуждены работать с одними и теми же страницами кода, что неизбежно приведет к конфликтам и сбоям?
Нет, и вот почему – несмотря на то, что копирование при записи в Windows 95 и Windows 98 не реализовано, эту заботу берет на себя сама функция WriteProcessMemory, создавая копии всех модифицируемых страниц, распределенных между процессами. Благодаря этому, самомодифицирующийся код одинаково хорошо работает как под Windows 95\Windows 98\Windows Me, так и под Windows NT\Windows 2000. Однако следует учитывать, что все копии приложения, модифицируемые любым иным путем (например, командой mov нулевого кольца) будучи запущенными под Windows 95\Windows 98 будут разделять одни и те же страницы кода со всеми вытекающими отсюда последствиями.
Теперь об ограничениях. Во-первых, использовать WriteProcessMemory разумно только в компиляторах, компилирующих в память или распаковщиках исполняемых файлов, а в защитах – несколько наивно.Мало-мальски опытный взломщик быстро обнаружит подвох, обнаружив эту функцию в таблице импорта. Затем он установит точку останова на вызов WriteProcessMemory, и будет контролировать каждую операцию записи в память. А это никак не входит в планы разработчика защиты!
Другое ограничение WriteProcessMemory заключается в невозможности создания новых страниц – ей доступны лишь уже существующие страницы. А как быть в том случае, если требуется выделить некоторое количество памяти, например, для кода, динамически генерируемого "на лету"? Вызов функций, управления кучей, таких как malloc, не поможет, поскольку в куче выполнение кода запрещено. И вот тогда-то на помощь приходит возможность выполнения кода в стеке…
Как хакеры ломают программы
Вскрыть защитный механизм взломщику в общем случае не проблема. Куда сложнее найти его во многих мегабайтах кода ломаемого приложения. Сегодня мало кто использует для этой цели автоматическую трассировку – на смену ей пришли аппаратные контрольные точки.
Например, пусть некая защита запрашивает пароль и затем каким-то образом удостоверяется в его подлинности (например, сравнивает с оригиналом), и в зависимости от результатов проверки передает управление соответствующей ветке программы. Вскрыть такую защиту взломщик может, даже не вникая в алгоритм аутентификации! Он просто введет первый пришедший ему на ум пароль (не обязательно совпадающий с правильным), найдет его в памяти, установит контрольную точку на первый символ строки своего пароля, дождется "всплытия" отладчика, отследившего обращение к паролю, выйдет из сравнивающей процедуры и "подправит" условие перехода так, чтобы управление получала всегда получала нужная ветвь программы.
Время снятия подобных защит измеряется секундами
(!) и обычно такие программы ломаются раньше, чем успевают дойти до легального потребителя. К счастью, этому можно противостоять!
Как обнаружить отладку средствами Windows
В своей книге "Секреты системного программирования в Windows 95" Мэт Питтрек описал структуру информационного блока цепочки (Thread Information Block), рассказав о назначении многих недокументированных полей. Особый интерес для данной статьи представляет двойное слово, лежащие по смещению 0x20 от начала структуры TIB, содержащие контекст отладчика (если данный процесс отлаживается) или ноль в противном случае. Информационный блок цепочки доступен через селектор, загруженный в регистр FS, и без проблем может читаться прикладным кодом.
Если двойное слово FS:[0x20] не равно нулю – процесс находится под отладкой. Это настолько заманчиво, что некоторые программисты включили такую проверку в свои защиты, не обратив внимания на ее "недокументированность". В результате, их программы не смогли исполняться под Windows NT, поскольку, она хранит в этом поле не контекст отладчика, а идентификатор процесса, который никогда не бывает равным нулю, отчего защита ошибочно полагает, что находится под отладкой.
Это обстоятельство было подробно описано самим же Мэтом Питтреком в майском номере журнала "Microsoft Systems Journal" за 1996 год, где в статье "Under The Hood" он привел следующую структуру:
union // 1Ch (NT/Win95 differences)
{
struct // Win95 fields
{
WORD TIBFlags; // 1Ch
WORD Win16MutexCount; // 1Eh
DWORD DebugContext; // 20h
DWORD pCurrentPriority; // 24h
DWORD pvQueue; // 28h Message Queue selector
} WIN95;
struct // WinNT fields
{
DWORD unknown1; // 1Ch
DWORD processID; // 20h
DWORD threadID; // 24h
DWORD unknown2; // 28h
} WINNT;
} TIB_UNION2;
Листинг 226
Этот случай в очередной раз подтвердил – не стоит без особой необходимости использовать недокументированные особенности, – как правило, они приносят больше проблем, чем пользы.
Как противостоять контрольным точкам останова
Контрольные точки, установленные на важнейшие системные функции, – мощное оружие в руках взломщика. Путь, к примеру, защита пытается открыть ключевой файл. Под Windows существует только один документированный способ это сделать – вызвать функцию CreateFile (точнее CreateFileA или CreateFileW для ASCII и UNICODE-имени файла соответственно). Все остальные функции, наподобие OpenFile, доставшиеся в наследство от ранних версий Windows, на самом деле представляют собой переходники к CreateFile.
Зная об этом, взломщик может заблаговременно установить точку останова на адрес начала этой функции (благо он ему известен) и мгновенно локализовать защитный код, вызывающий эту функцию, ну а остальное, как говорится, дело техники.
Но не всякий взломщик осведомлен, что открыть файл можно и другим путем – вызвать функцию ZwCreateFile (равно как и NtCreateFile), экспортируемую NTDLL.DLL, или обратится напрямую к ядру вызовом прерывания INT 0x2Eh. Сказанное справедливо не только для CreateFile, но и для всех остальных функций ядра. Причем для этого не нужны никакие привилегии, и такой вызов можно осуществить даже из прикладного кода!
Опытного взломщика, такой трюк надолго не остановит, но почему бы ему ни приготовить один маленький сюрприз, поместив вызов INT 0x2E в блок __try. Это приведет к тому, что управление получит не ядро системы, а обработчик данного исключения, находящийся за блоком _try. Взломщик же, не имеющий исходных текстов, не сможет быстро определить: относится ли данный вызов к блоку _try или нет. Отсюда: он может быть легко введен в заблуждение – достаточно имитировать открытие файла, не выполняя его на самом деле! Кроме того, ничего не мешает использовать прерывание INT 0x2E для взаимодействия компонентов свой программы – взломщику будет очень не просто отличить какой вызов пользовательский, а какой системный.
Хорошо, с ядром все понятно, а как же быть с функциями модулей USER и GDI, например, GetWindowsText, использующейся для считывания введенной пользователем ключевой информации (как правило, серийного номера или пароля)? На помощь приходит то обстоятельство, что практически все эти функции начинаются с инструкций PUSH EBP\MOV EBP,ESP, которые прикладной код может выполнить и самостоятельно, передав управление не на начало функции, а на три байта ниже. (Поскольку PUSH EBP изменяет стек, приходится прибегать к передаче управления посредством JMP вместо CALL).
Контрольная точка, установленная взломщиком на начало функции, не возымеет никакого действия! Такой трюк может сбить с толку даже опытного хакера, хотя рано или поздно он все равно раскусит обман, но…
Если есть желание окончательно отравить взломщику жизнь, следует скопировать системную функцию в свой собственный стек и передать на него управление – контрольные точки взломщика "отдыхают"! Основная сложность заключается в необходимости распознания всех инструкций с относительными адресными аргументами и их соответствующей коррекции. Например, двойное слово, стоящее после инструкции CALL, представляет собой не адрес перехода, а разность целевого адреса и адреса следующей за CALL инструкции. Перенос инструкции CALL на новое место потребует коррекции ее аргумента. Впрочем, эта задача не так сложна, как может показаться на первый взгляд (глаза страшатся, а руки делают), и результат оправдывает средства – во-первых, при каждом запуске функции можно произвольным образом менять ее адрес, во-вторых, проверкой целости кода легко обнаружить программные точки останова – а аппаратных точек на все вызовы просто не хватит!
Разве ж не заслуживают награды за свою целеустремленность те единицы, которую такую защиту взломают?! (Под наградой здесь подразумевается отнюдь не сама взломанная программа, а глубокое чувство удовлетворения от того, что "я это сделал!").
Еще легче противостоять аппаратным точкам останова на память – поскольку их всего четыре и каждая может контролировать не более двойного слова, взломщик может одновременно контролировать не более 16 байт памяти. Если же обращения к буферам, содержащим ключевую информацию, будут происходить не последовательно байт за байтам от начала до конца, а произвольно, и количество самих буферов окажется больше четырех, отследить все операции чтения-записи в них станет невозможно.
Некоторые отладчики поддерживают возможность установки точки останова на диапазон памяти, но ее функциональность вызывает большие сомнения – единственный способ контролировать целый регион – трассировать исследуемую программу, проверяя, не обращается ли очередная команда к охраняемому диапазону и если да, – генерировать исключение.
Во-первых, команд, манипулирующих с памятью очень много, и можно придумать самые неожиданные комбинации – например, установить указатель стека на требуемую ячейку памяти и вызвать RET для чтения содержащегося в ней значения. Во-вторых, возникшее при этом исключение, может служить хорошим средством избавления от трассировщка (см. раздел "Как противостоять трассировке").
Таким образом, справится с контрольными точками, защитному механизму совсем не трудно!
Точка останова представляет собой однобайтовую команду 0xCC, генерирующую исключение 0x3 при попытке ее выполнения (в просторечии "дергающие отладочным прерыванием"). Обработчик INT 0x3 получает управление и может делать с программой абсолютно все, что ему заблагорассудится, но прежде – до вызова прерывания – в стек заносятся текущие регистр флагов, указатель кодового сегмента (регистр CS), указатель команд (регистр IP), запрещаются прерывания (очищается флаг IF) и сбрасывается флаг трассировки – словом, вызов отладочного прерывания не отличатся от вызова любого прерывания вообще. (см. рис)
Чтобы узнать в какой точке программы произошел останов, отладчик извлекает из стека сохраненное значение регистров, не забывая о том, – CS:IP указывают на следующую выполняемую команду.
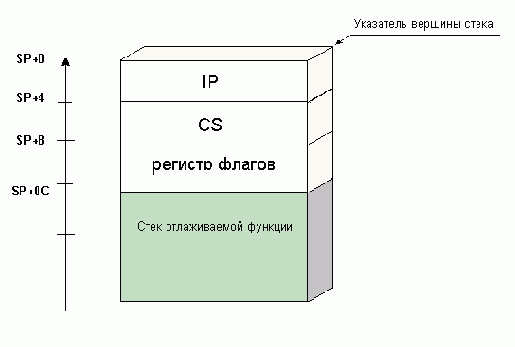
Рисунок 37 0x005 Состояние стека на момент входа в обработчик прерывания
Условно точки останова (называемые так же контрольными точками) можно разделить на две категории: точки останова жестко прописанные в программе самим разработчиком и точки динамические устанавливаемые самим отладчиком. Ну, с первыми все ясно – хочешь остановить программу и передать управление отладчику в там-то месте – пишешь __asm{ int 0x3} и – надевай тигра Шляпу!
Несколько сложнее установить точку в произвольное место программы – сначала отладчик должен сохранить текущее значение ячейки памяти по указанному адресу, затем записать сюда код 0xCC, а перед выходом из отладочного прерывания вернуть все на место и модифицировать сохраненный в стеке IP, для перемещения его на начало восстановленной команды (иначе, он будет указывать на ее середину).
Какими недостатками обладает механизм точек останова 8086-процессора? Первое, и самое неприятное, состоит в том, что точка устанавливая точку останова, отладчик вынужден непосредственно модифицировать код. Отлаживая программа тривиальной проверкой собственной целостности может легко обнаружить факт отладки и даже удалить точку останова! Не стоит использовать конструкции наподобие if (CalculateMyCRC()!=MyValidCRC) {printf("Hello, Hacker!\n");return;} их слишком легко обнаружить и нейтрализовать, подправив условный переход так, чтобы он всегда передавал управление нужной ветке программы. Лучше расшифровывать полученным значением контрольной суммы критические данные или некоторый код.
Простейшая защита может выглядеть, например, так (только не удивляйтесь откуда взялись 32-разрядные регистры в процессоре 8086 – пример, разумеется, предназначен для 386+, сохранившего точки останова от своего предшественника, причем их активно используют не только прикладные отладчики, но даже… сам Айс!):
int main(int argc, char* argv[])
{
// зашифрованная
строка Hello, Free World!
char s0[]="\x0C\x21\x28\x28\x2B\x68\x64\x02\x36\
\x21\x21\x64\x13\x2B\x36\x28\x20\x65\x49\x4E";
__asm
{
BeginCode: ; //начало контролируемого кода
pusha ; //сохранение всех регистров общего назначения
lea ebx,s0 ; // ebx=&s0[0]
GetNextChar: ; // do
XOR eax,eax ; // eax = 0;
LEA esi,BeginCode;// esi = &BeginCode
LEA ecx,EndCode ; // выислиление длины...
SUB ecx,esi ; // ...контролируемого кода
HarvestCRC: ; // do
LODSB ; // загрузка очередного байта в al
ADD eax,eax ; // выисление контрольной суммы
LOOP HarvestCRC ; // until(--cx>0)
xor [ebx],ah ; // расшифровка очередного символа s0
inc ebx ; // указатель на след. симв.
cmp [ebx],0 ; // until (пока не конец строки)
jnz GetNextChar ; // продолжить расшифровку
popa ; // восстановить все регистры
EndCode: ; // конец контролируемого кода
NOP ; // Safe BreakPoint here
}
printf(s0); // вывод строки на экран
return
0;
}
Листинг 224
При нормальном запуске на экране должна появиться строка "Hello, Free World!", но при прогоне под отладчиком при наличии хотя бы одной точки останова, установленной в пределах от BeginCode до EndCode на экране появится бессмысленный мусор наподобие: "Jgnnm."Dpgg"Umpnf#0"
Причем, Soft-Ice неявно помещает точку останова в начало каждой следующей команды при трассировке программы по Step Over (<F10>)! Разумеется, это искажает контрольную сумму, чем и пользуются защита.
Самое простое решение проблемы - положить кирпич на клавишу <F8> (покомандная трассировка) и идти пить чай, пока программа будет расшифровываться. Шутка, конечно. А если говорить серьезно, то необходимо вспомнить в каком веке мы живем и, отбросив каменные топоры, установить аппаратную точку останова (см. "Приемы против отладчиков защищенного режима"). {>>>>> сноска Кстати, значительно усилить защиту можно, если поместить процедуру подсчета контрольной суммы в отдельный поток, занимающийся (для сокрытия свой деятельности) еще чем-нибудь полезным так, чтобы защитный механизм по возможности не бросался в глаза.}
Наши же предки (хакеры восьмидесятых) в этой ситуации обычно вручную расшифровывали программу, а затем затирали процедуру расшифровки NOP-ми, после чего отладка программы уже не представляла проблемы (естественно, если в защите не было других нычек). До появления IDA расшифровщик приходилось писать на Си (Паскале, Бацике) в виде самостоятельной программы, теперь же эта задача упростилась, и заниматься расшифровкой стало можно непосредственно в самом дизассемблере.
Техника расшифровки сводится к воспроизведению расшифровщика на языке IDA-Си – в данном случае сначала необходимо вычислить контрольную сумму от BginCode до EndCode подчитывая сумму байтов, используя при этом младший байт контрольной суммы для загрузки следующего символа, а затем полученным значением "поксорить" строку s0.
Все это можно сделать следующим скриптом (предполагается, что в дизассемблированном тексте соответствующие метки уже расставлены):
auto a; auto p; auto crc; auto ch;
for (p=LocByName("s0");Byte(p)!=0;p++)
{
crc=0;
for(a=LocByName("BeginCode");a<(LocByName("EndCode"));a++)
{
ch=Byte(a);
// Поскольку IDA не поддерживает типов byte и word
// (а напрасно) приходится заниматься битовыми
// выкрутасами – сначала очищать младший байт crc,
// а затем копировать в него считанное значение ch
crc = crc & 0xFFFFFF00;
crc = crc | ch;
crc=crc+crc;
}
// Берем старший байт от crc
crc=crc & 0xFFFF;
crc=crc / 0x100;
// Расшифровываем очередной байт строки
PatchByte(p,Byte(p) ^ crc);
}
Листинг 225
Если под рукой нет IDA, эту же операцию можно осуществить и в HIEW-е:
NoTrace.exe vW PE 00001040 a32 <Editor> 28672 ? Hiew 6.04 (c)SEN 00401003: 83EC18 sub esp,018 ;"^" 00401006: 53 push ebx 00401007: 56 push esi 00401008: 57 push edi 00401009: B905000000 000005 ;" ¦" 0040100E: BE30604000 г=[Byte/Forward ] =============¬ 406030 ;" @`0" 00401013: 8D7DE8 ¦ 1>mov bl,al ¦ AX=0061 ¦p][-0018] 00401016: F3A5 ¦ 2 add ebx,ebx ¦ BX=44C2 ¦гнать 00401018: A4 ¦ 3 ¦ CX=0000 ¦отсюда-> 00401019: 6660 ¦ 4 ¦ DX=0000 ¦ 0040101B: 8D9DE8FFFF ¦ 5 ¦ SI=0000 ¦ [0FFFFFFE8] 00401021: 33C0 ¦ 6 ¦ DI=0000 ¦.0040101B: 8D9DE8FFFFFF L==============================-.00401021: 33C0 xor eax,eax.00401023: 8D3519104000 lea esi,[000401019] ; < BeginCode.00401029: 8D0D40104000 lea ecx,[000401040] ; < EndCode.0040102F: 2BCE sub ecx,esi.00401031: AC lodsb 00401032: 03C0 add eax,eax 00401034: E2FB loop 000001031 00401036: 3023 xor [ebx],ah 00401038: 43 inc ebx 00401039: 803B00 cmp b,[ebx],000 ;" " 0040103C: 75E3 jne 000001021 0040103E: 6661 popaдосюда-> 00401040: 90 nop 00401041: 8D45E8 lea eax,[ebp][-0018] 00401044: 50 push eax 00401045: E80C000000 call 000001056 0040104A: 83C404 add esp,004 ;"¦"1Help 2Size 3Direct 4Clear 5ClrReg 6 7Exit 8 9Store 10Load
На первой стадии производится подсчет контрольной суммы. Загрузив файл в HIEW, находим нужный фрагмент (<ENTER>, <ENTER> для перехода в режим ассемблера и <F8>, <F5> для прыжка в точку входа, далее находим в стартовом коде процедуру main), нажимаем <F3> для разрешение правки файла, вызываем редактор скрипта-расшифровщика (<CTRL-F7>, впрочем, эта комбинация варьируется от версии к версии) и вводим следующий код:
mov bl, al
add ebx, ebx
Вместо EBX можно использовать и другой регистр, но не EAX – HIEW, считывая очередной байт обнуляет EAX целиком. Теперь установим курсор на строку 0x401019 и, нажимая <F7>, погоним расшифрошик до строки 0x401040, не включая последнюю. Если все сделано правильно в старшем байте BX должно находится значение 0x44, - это и есть контрольная сумма.
На второй стадии находим шифрованную строку (ее смещение грузится в ESI и равно .406030) и ксорим ее по 0x44. (Нажимаем <F3> для перехода в режим правки, <CTRL-F8> для задания ключа шифрования – 0x44, а затем ведем расшифровщик по строке, нажимая <F8>)
NoTrace.exe vW PE 00006040 <Editor> 28672 ? Hiew 6.04 (c)SEN
00006030: 48 65 6C 6C-6F 2C 20 46-72 65 65 20-57 6F 72 6C Hello, Free Worl
00006040: 20 65 49 4E-00 00 00 00-7A 1B 40 00-01 00 00 00 eIN z<@ O
Остается лишь забить NOP-ми XOR в строке 0x401036, иначе при запуске программы он испортит расшифрованный текст (зашифрует его вновь) и программа, работать, естественно не будет.
Теперь, после снятия защиты, ее можно безболезненно отлаживать сколько душе угодно – да, контрольная сумма по-прежнему считается, но теперь она не используется (если бы в защите была проверка на корректность CRC, пришлось бы нейтрализовать и ее, но в этом примере для упрощения понимания ничего подобного нет).
